Hadoop 伪分布模式安装
( 温馨提示:图片中有id有姓名,不要盗用哦,可参考流程,有问题评论区留言哦 )
一、任务目标
1、了解Hadoop的3种运行模式
2、熟练掌握Hadoop伪分布模式安装流程
3、培养独立完成Hadoop伪分布安装的能力
二、系统环境
Linux Ubuntu 16.04
三、任务内容
在只安装Linux系统的服务器上,安装Hadoop2.6.0伪分布模式。
四、任务步骤
1.此步为可选项,建议用户创建一个新用户及用户组,后续的操作基本都是在此用户下来操作。但是用户亦可在自己当前非 root 用户下进行操作。 创建一个用户,名为 zhangyu,并为此用户创建 home 目录, 此时会默认创建一个与 zhangyu 同名的用户组。
为 zhangyu 用户设置密码,按提示消息,输入密码以及确认密码即可,此处密码设置为 zhangyu 将 zhangyu 用户的权限,提升到 sudo 超级用户级别
后续操作,我们需要切换到 zhangyu 用户下来进行操作。

2.(1)首先来配置SSH 免密码登陆 SSH免密码登陆需要在服务器执行以下命令,生成公钥和私钥对. 此时会有多处提醒输入在冒号后输入文本,这里主要是要求输入ssh密码以及密码的放置位置。在这里, 只需要使用默认值,按回车即可。
(2)此时ssh公钥和私钥已经生成完毕,且放置在~/.ssh目录下。切换到~/.ssh目录下。查看~/.ssh目录下的文件。

(3)下面在~/.ssh目录下,创建一个空文本,名为authorized_keys。
将存储公钥文件的id_rsa.pub里的内容,追加到authorized_keys中。
(4)下面执行ssh localhost测试ssh配置是否正确。第一次使用ssh访问,会提醒是否继续连接,输入“yes"继续进行,执行完以后退出。后续再执行ssh localhost时,就不用输入密码了。

3.(5)下面首先来创建两个目录,用于存放安装程序及数据。并为/apps和/data 目录切换所属的用户为zhangyu及用户组为zhangyu。两个目录的作用分别为:/apps目录用来存放安装的框架,/data 目录用来存放临时数据、HDFS数据、程 序代码或脚本。
(6)切换到根目录下,执行 ls -l 命令。可以看到根目录下/apps和/data 目录所属用户及用户组已切换为zhangyu:zhangyu。

4. 配置HDFS。
创建/data/hadoop1目录,用来存放相关安装工具,如jdk安装包jdk-7u75-linux-x64.tar.gz及hadoop安装包hadoop-2.6.0-cdh5.4.5.tar.gz。
切换目录到/data/hadoop1目录,使用wget命令,下载所需的hadoop安装包jdk-7u75-linux-x64.tar.gz及hadoop-2.6.0-cdh5.4.5.tar.gz。

5.(1)安装jdk。将/data/hadoop1目录下jdk-7u75-linux-x64.tar.gz 解压缩到/apps目录下。其中,tar -xzvf 对文件进行解压缩,-C 指定解压后,将文件放到/apps目录下。
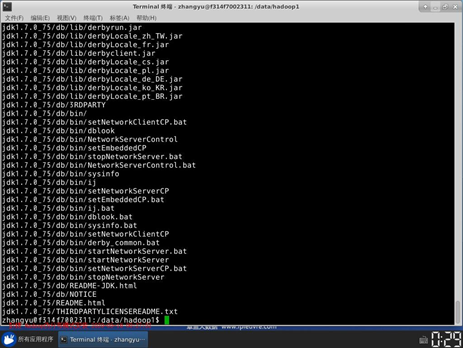
(2)切换到/apps目录下,我们可以看到目录下内容如下:
(3)下面将jdk-14.0.1目录重命名为java,执行:

6. 下面来修改环境变量:系统环境变量或用户环境变量。我们在这里修改用户环境变量。

(1)输入下面命令,打开存储环境变量的文件。空几行,将java的环境变量,追加进用户环境变量中。输入Esc, 进入vim 命令模式,输入 :wq !进行保存。
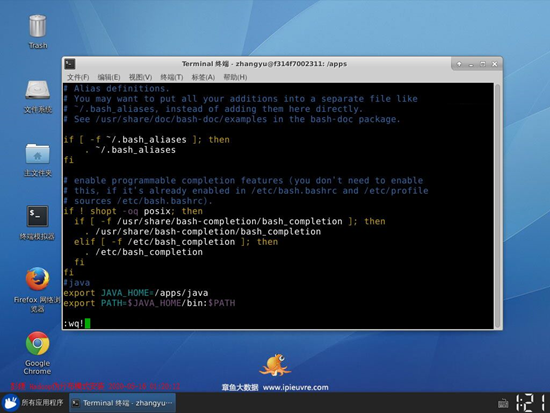
(2)执行source命令,让java环境变量生效。执行完毕后,可以输入java,来测试环境变量是否配置正确。 如果出现下面界面,则正常运行。

7. 下面安装hadoop,切换到/data/hadoop1目录下,将hadoop-2.6.0-cdh5.4.5.tar.gz解压缩到/apps 目录下。为了便于操作,我们也将hadoop-2.6.0-cdh5.4.5重命名为hadoop。

8. (1)0修改用户环境变量,将hadoop的路径添加到path中。先打开用户环境变量文件。将以下内容追加到环境变量~/.bashrc文件中。
(2)让环境变量生效。

(3)验证hadoop环境变量配置是否正常

9. 下面来修改hadoop本身相关的配置。首先切换到hadoop配置目录下。

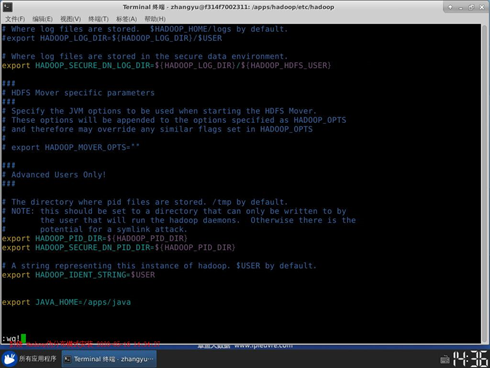
10. (1)输入vim /apps/hadoop/etc/hadoop/hadoop-env.sh,打开hadoop-env.sh配置文件。将下面JAVA_HOME追加到hadoop-env.sh文件中。
11. 输入vim /apps/hadoop/etc/hadoop/core-site.xml,打开core-site.xml配置文件。添加下面配置到<configuration>与</configuration>标签之间。

12. 输入vim /apps/hadoop/etc/hadoop/hdfs-site.xml,打开hdfs-site.xml配置文件。添加下面配置到<configuration>与</configuration>标签之间。配置项说明: dfs.namenode.name.dir,配置元数据信息存储位置; dfs.datanode.data.dir,配置具体数据存储位置; dfs.replication,配置每个数据库备份数,由于目前我们使用 1 台节点,所以,设置为 1,如果设置为2 的话,运行会报错。 dfs.permissions.enabled,配置hdfs是否启用权限认证 另外/data/tmp/hadoop/hdfs路径,需要提前创建,所以我们需要执行

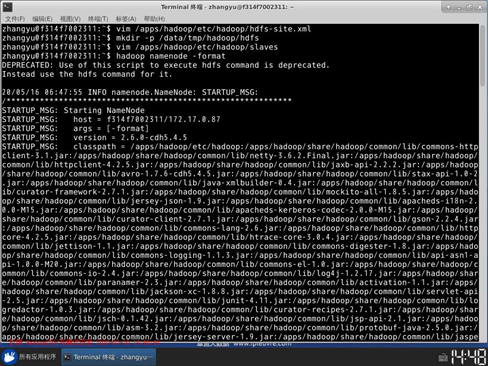
13. 输入vim /apps/hadoop/etc/hadoop/slaves,打开slaves配置文件。将集群中slave角色的节点的主机名,添加进slaves文件中。目前只有一台节点,所以slaves文件内容为:localhost

14.下面格式化HDFS文件系统。执行:
15. 切换目录到/apps/hadoop/sbin目录下。
16. 启动hadoop的hdfs相关进程
17. 输入jps查看HDFS相关进程是否已经启动。

18. 下面可以再进一步验证HDFS运行状态。先在HDFS上创建一个目录。
19. 执行下面命令,查看目录是否创建成功。
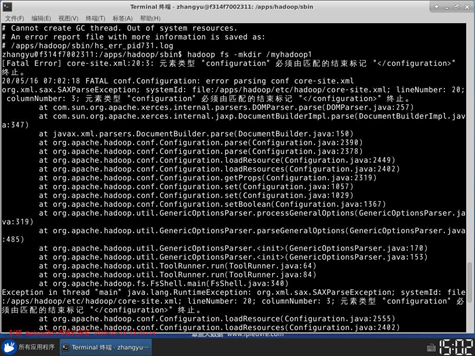
20. 下面来配置MapReduce相关配置。再次切换到hadoop配置文件目录

21. 下面将mapreduce的配置文件mapred-site.xml.template,重命名为mapred-site.xml。

22. 输入vim /apps/hadoop/etc/hadoop/mapred-site.xml,打开mapred-site.xml配置文件。将mapreduce相关配置,添加到<configuration>标签之间。

23. 输入vim /apps/hadoop/etc/hadoop/yarn-site.xml,打开yarn-site.xml配置文件。将yarn相关配置,添加到<configuration>标签之间。

24. 下面来启动计算层面相关进程,切换到hadoop启动目录。
25. 执行命令,启动yarn。
26. 输入jps,查看当前运行的进程。

27. 执行测试。切换到/apps/hadoop/share/hadoop/mapreduce目录下。然后,在该目录下跑一个mapreduce程序,来检测一下hadoop是否能正常运行。

五、实验总结
章鱼互联网平台非常好用,是一个实践操作的很好平台,本次实验历经很多波折,最开始做了一遍,因为截图不合格后来重新做的,但可能网络不稳定,好多地方不对,重新做了好多遍才完成,也更加熟悉了。
Hadoop 伪分布模式安装的更多相关文章
- Hadoop学习笔记(3)hadoop伪分布模式安装
为了学习这部分的功能,我们这里的linux都是使用root用户登录的.所以每个命令的前面都有一个#符号. 伪分布模式安装步骤: 关闭防火墙 修改ip地址 修改hostname 设置ssh自动登录 安装 ...
- hadoop伪分布模式安装
软件环境 操作系统 : OracleLinux-R6-U6 主机名: hadoop java: jdk1.7.0_75 hadoop: hadoop-2.4.1 环境搭建 1.软件安装 由于所需的软 ...
- hadoop伪分布模式的配置和一些常用命令
大数据的发展历史 3V:volume.velocity.variety(结构化和非结构化数据).value(价值密度低) 大数据带来的技术挑战 存储容量不断增加 获取有价值的信息的难度:搜索.广告.推 ...
- 【原】Hadoop伪分布模式的安装
Hadoop伪分布模式的安装 [环境参数] (1)Host OS:Win7 64bit (2)IDE:Eclipse Version: Luna Service Release 2 (4.4.2) ( ...
- Spark新手入门——2.Hadoop集群(伪分布模式)安装
主要包括以下三部分,本文为第二部分: 一. Scala环境准备 查看 二. Hadoop集群(伪分布模式)安装 三. Spark集群(standalone模式)安装 查看 Hadoop集群(伪分布模式 ...
- Hadoop单点伪分布模式安装
Hadoop单点伪分布模式安装 概述 单点 single-node,单节点,即一台计算机. 伪分布式模式 pseudo-distributed mode 所谓集群,表面上看是多台计算机联合完成任务:但 ...
- 伪分布模式安装hadoop
准备工具: 虚拟机:VMware Linux系统:CentOS hadoop-1.1.2.tar.gz jdk-7u75-linux-x64.gz CentOS的网络配置 1.设置主机中VMware ...
- Hadoop伪分布模式配置
本作品由Man_华创作,采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可.基于http://www.cnblogs.com/manhua/上的作品创作. 请先按照上一篇文章H ...
- Linux环境搭建Hadoop伪分布模式
Hadoop有三种分布模式:单机模式.伪分布.全分布模式,相比于其他两种,伪分布是最适合初学者开发学习使用的,可以了解Hadoop的运行原理,是最好的选择.接下来,就开始部署环境. 首先要安装好Lin ...
随机推荐
- 【WPF学习】第六十八章 自定义绘图元素
上一章分析了WPF元素的内部工作元素——允许每个元素插入到WPF布局系统的MeasureOverride()和ArrangeOverride()方法中.本章将进一步深入分析和研究元素如何渲染自身. 大 ...
- C# 基础知识系列- 15 异常处理篇
0. 前言 为什么我们需要异常处理?什么是异常? 在汉语中,异常指非正常的:不同于平常的.翻译到程序中,就是指会导致程序无法按照既定逻辑运行的意外,或者说是错误.可能会有小伙伴好奇了,我们的程序不是正 ...
- F - Qualification Rounds CodeForces - 868C 二进制
F - Qualification Rounds CodeForces - 868C 这个题目不会,上网查了一下,发现一个结论就是如果是可以的,那么两个肯定可以满足. 然后就用二进制来压一下这个状态就 ...
- NIO(一) Java NIO 概述
转:http://ifeve.com/overview/ Java NIO 由以下几个核心部分组成: Channels Buffers Selectors 虽然Java NIO 中除此之外还有很多类和 ...
- Facebook 开源微光效果 Shimmer
我的引言 晚上好,我是吴小龙同学,我的公众号「一分钟 GitHub」会推荐 GitHub 上好玩的项目,挖掘开源的价值,欢迎关注我. 今天要推荐的是 Facebook 开源的闪光效果:Shimmer, ...
- HDU 2007 (水)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=2007 题目大意:给你段连续数字,让你求 all sum of (偶数2 )and all sum of ...
- python --集合set的学习
集合是一个无序的不重复的元素序列,一般我们使用set(value)函数来创建集合. 如下: 定义以及添加元素,以及注意点如下: 再如下:
- java ->Iterator (迭代)
Iterator迭代器概述 java中提供了很多个集合,它们在存储元素时,采用的存储方式不同.我们要取出这些集合中的元素,可通过一种通用的获取方式来完成. Collection集合元素的通用获取方式: ...
- vue.use()方法从源码到使用
在做 vue 开发的时候大家一定经常接触 Vue.use() 方法,官网给出的解释是: 通过全局方法 Vue.use() 使用插件:我觉得把使用理解成注册更合适一些,首先看下面常见的注册场景. 1 2 ...
- 把iview中的table组件写成了一个公用组件,在另一个组件里去引用它的时候rander函数里的this指向不正确
在vue项目里使用iview制作后台管理系统时,由于有多个页面都需要用到table组件,所以就把table写到了一个公共组件里,在其他页面去引用它,但是这时会发现一个问题,就是render函数里的th ...