【真相揭秘】requests获取网页编码乱码本质
有没有被网页编码抓狂,怎么转都是乱码。
通过查看requests源代码,才发现是库本身历史原因造成的。
作者是严格http协议标准写这个库的,《HTTP权威指南》里第16章国际化里提到,如果HTTP响应中Content-Type字段没有指定charset,则默认页面是'ISO-8859-1'编码。
这处理英文页面当然没有问题,但是中文页面,特别是那些不规范的页面,就会有乱码了!
比如分析jd.com 页面为gbk编码,问题就出在这里。
chardet库监测编码却是GB2312,两种编码虽然兼容的,但用GB2312解码gbk编码的网页字节串会运行错误!
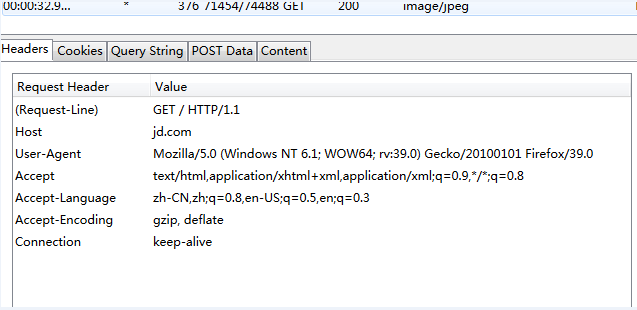

reqponse header只指定了type,但是没有指定编码(一般现在页面编码都直接在html页面中)。所有该函数就直接返回'ISO-8859-1'。
# test1
In [1]: r = requests.get('https://www.baidu.com/')
In [2]: r.encoding
Out[2]: 'ISO-8859-1'
In [3]: type(r.text)
Out[3]: unicode
In [4]: type(r.content)
Out[4]: str
In [5]: r.apparent_encoding
Out[5]: 'utf-8'
In [6]: chardet.detect(r.content)
Out[6]: {'confidence': 0.99, 'encoding': 'utf-8'}
在requests获取网页的编码格式时,有两种方式encoding和apparent_encoding,结果也不同,
推荐apparent_encoding,常规写法
url='xxx'
req =requests.get(url)
req.encoding=req.apparent_encoding
print(req.text)
总之一句话,遇到乱码加上apparent_encoding就完事了。
参考
https://www.cnblogs.com/emmm/p/9792832.html
https://www.cnblogs.com/bitpeng/p/4748872.html
【真相揭秘】requests获取网页编码乱码本质的更多相关文章
- python获取网页编码问题(encoding和apparent_encoding)
在requests获取网页的编码格式时,有两种方式,而结果也不同,通常用apparent_encoding更合适 注:推荐一个大佬写的关于获取网页编码格式以及requests中text()和conte ...
- Python 2.7.3 urllib2.urlopen 获取网页出现乱码解决方案
出现乱码的原因是,网页服务端有bug,它硬性使用使用某种特定的编码方案,而并没有按照客户端的请求头的编码要求来发送编码. 解决方案:使用chardet来猜测网页编码. 1.去chardet官网下载ch ...
- java根据URL获取网页编码
由于很多原因,我们要获取网页的编码(多半是写批量抓取的脚本吧...嘻嘻嘻) 注意: 如果你的目的是获取不乱码的网页内容(而不是根据网址发送post请求获取返回值),切记切记,移步这里 java根据UR ...
- asp.net 利用HttpWebRequest自动获取网页编码并获取网页源代码
/// <summary> /// 获取源代码 /// </summary> /// <param name="url"></param& ...
- 解决requests获取源代码时中文乱码问题
用requests获取源代码时,如果是中文网页,就可能会出现乱码,下面我以中关村的网站为例: import requests url = 'http://desk.zol.com.cn/meinv/' ...
- WebRequest 获取网页乱码
问题:在用WebRequest获取网页源码时得到的源码是乱码. 原因:1,编码不对 解决办法:设置对应编码 WebRequest request = WebRequest.Create(Url);We ...
- 爬虫 Http请求,urllib2获取数据,第三方库requests获取数据,BeautifulSoup处理数据,使用Chrome浏览器开发者工具显示检查网页源代码,json模块的dumps,loads,dump,load方法介绍
爬虫 Http请求,urllib2获取数据,第三方库requests获取数据,BeautifulSoup处理数据,使用Chrome浏览器开发者工具显示检查网页源代码,json模块的dumps,load ...
- 解决Chrome网页编码显示乱码的问题
解决Chrome网页编码显示乱码的问题 记得在没多久以前,Google Chrome上面出现编码显示问题时,可以手动来调整网页编码问题,可是好像在Chrome 55.0版以后就不再提供手动调整编码,所 ...
- node爬虫之gbk网页中文乱码解决方案
之前在用 node 做爬虫时碰到的中文乱码问题一直没有解决,今天整理下备忘.(PS:网上一些解决方案都已经不行了) 中文乱码具体是指用 node 请求 gbk 编码的网页,无法正确获取网页中的中文(需 ...
随机推荐
- POJ 1330 Nearest Common Ancestors(裸LCA)
Nearest Common Ancestors Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 39596 Accept ...
- ubuntu16 安装curl
sudo apt-get install openssl sudo apt-get install libssl-dev wget -P /usr/local/software https://cu ...
- 使用 if elseif else 指定条件
nrows = 4; ncols = 6; A = ones(nrows,ncols); 遍历矩阵并为每个元素指定一个新值.对主对角线赋值 2,对相邻对角线赋值 -1,对其他位置赋值 0. for c ...
- 你真的会用Flutter日期类组件吗
Flutter系统提供了一些日期选择类组件,比如DayPicker.MonthPicker.YearPicker.showDatePicker.CupertinoDatePicker等,其中前4个为M ...
- 真香!PySpark整合Apache Hudi实战
1. 准备 Hudi支持Spark-2.x版本,你可以点击如下链接安装Spark,并使用pyspark启动 # pyspark export PYSPARK_PYTHON=$(which python ...
- EEGLAB-批量处理.dat数据及保存脑电地形图
步骤 1.先在图形界面操作一遍准备做的操作. 2.在命令行窗口输入 EEG.history 获取刚刚操作都用到哪些语句. 3.稍加修改即可以写一个批量化函数来读取生成数据. 4.在 EEGLAB\ee ...
- 一文教你快速修改ubuntu终端显示的主机名和用户名
为了让终端的显示更加简洁,清爽,改掉显示的用户名和主机名,改成你喜欢的名字. 创作不易,如果本文帮到了您: 如果本文帮到了您,请帮忙点个赞
- [hdu5323]复杂度计算,dfs
题意:求最小的线段树的右端点(根节点表示区间[0,n]),使得给定的区间[L,R]是线段树的某个节点. 数据范围:L,R<=1e9,L/(R-L+1)<=2015 思路:首先从答案出发来判 ...
- [hdu5101]计数问题
http://acm.hdu.edu.cn/showproblem.php?pid=5101 题目大意:给n个集合,求从两个不同集合里面各取一个数使得它们的和大于给定数的方案数. ans=从所有数里面 ...
- [hdu1242]优先队列
题意:给一个地图,'x'走一步代价为2,'.'走一步代价为1,求从s到t的最小代价.裸优先队列. #pragma comment(linker, "/STACK:10240000,10240 ...