如何使用JMeter从文件中提取数据
在性能测试方面,重用响应数据至关重要。几乎(如果不是全部!)负载测试场景假设您:
从先前的响应中提取有趣的方面,并在下一个请求中重用它们(也称为相关)
确保实际响应符合预期(又称断言)
因此,如果您是性能测试工程师,那么了解如何实现此关联和断言逻辑非常重要。幸运的是,BlazeMeter的知识库和JMeter博客已经有一些关于如何做到这一点的精彩文章。请查看以下内容:
使用带有JMeter的RegEx(正则表达式提取器) - 使用Perl5样式的正则表达式解析响应
在JMeter中使用XPath和JSON路径提取器 - 处理XML / XHTML和JSON数据
如何在3个简单步骤中使用JMeter断言 - 将断言应用于响应并有条件地设置通过或失败标准
这些都是基于文本的响应的好方法。但是,如果你需要从二进制文件中提取某些内容呢?例如,如果您需要验证作为HTTP请求采样器响应的Microsoft Word文档的内容,该怎么办?
这正是我将要在本文中解决的那种挑战。我将引导您完成查看和获取不同文档类型内容的过程,包括Microsoft Office,OpenOffice,ZIP存档和多媒体文件。
如何查看二进制文件的内容
在开始之前,请确保您知道如何使用JMeter的View Results Tree Listener - 因为它对请求和响应详细信息的可视化和检查非常有用。如果您不熟悉它,请查看本文:如何调试Apache JMeter脚本
现在让我们从一个非常基本的Microsoft Excel兼容电子表格开始。我拿了一个3.6KB的Microsoft Office Excel工作表。


如您所见,我们有一个文件test.xlsx,其中一个工作表标记为“Sheet1”。在单元格A1中,我们有字符串foo,在单元格B1中,我们有字符串条。
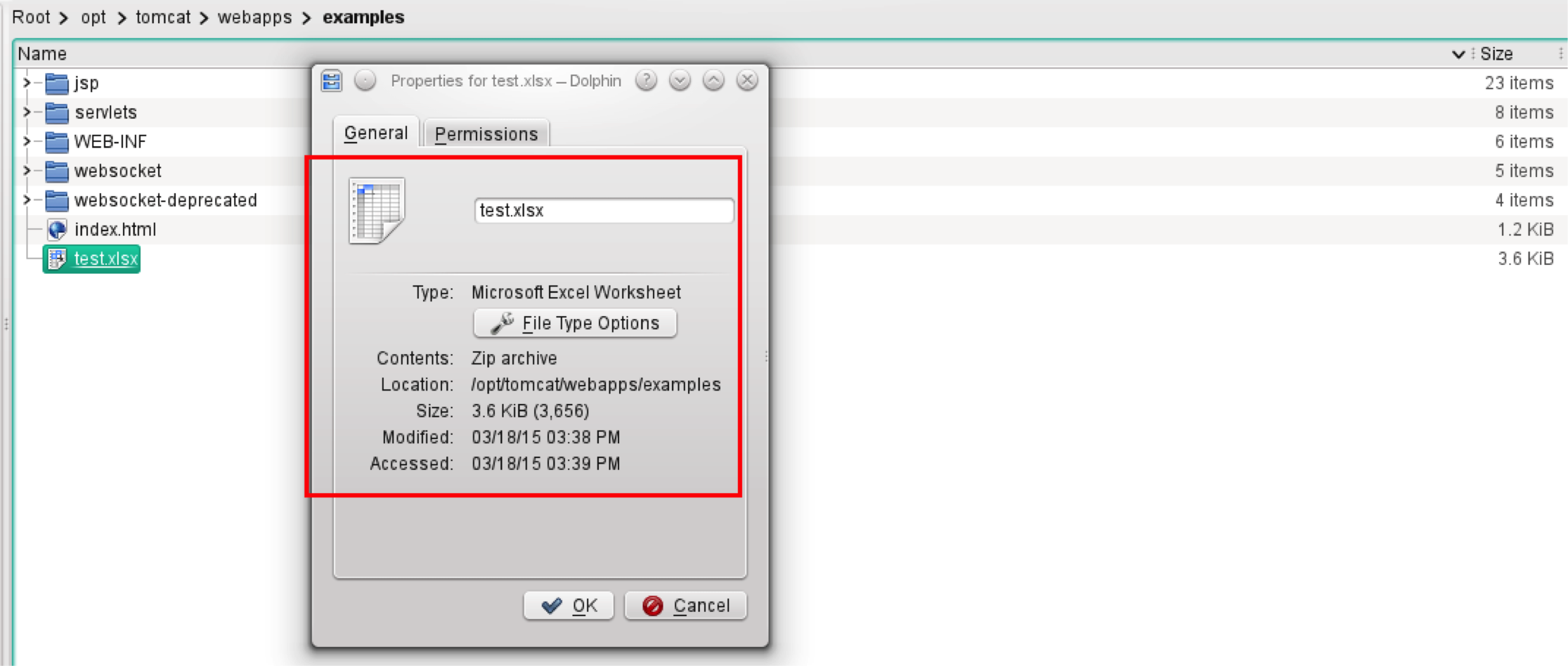
现在是时候使用'查看结果树监听器'来了解JMeter如何看待它。
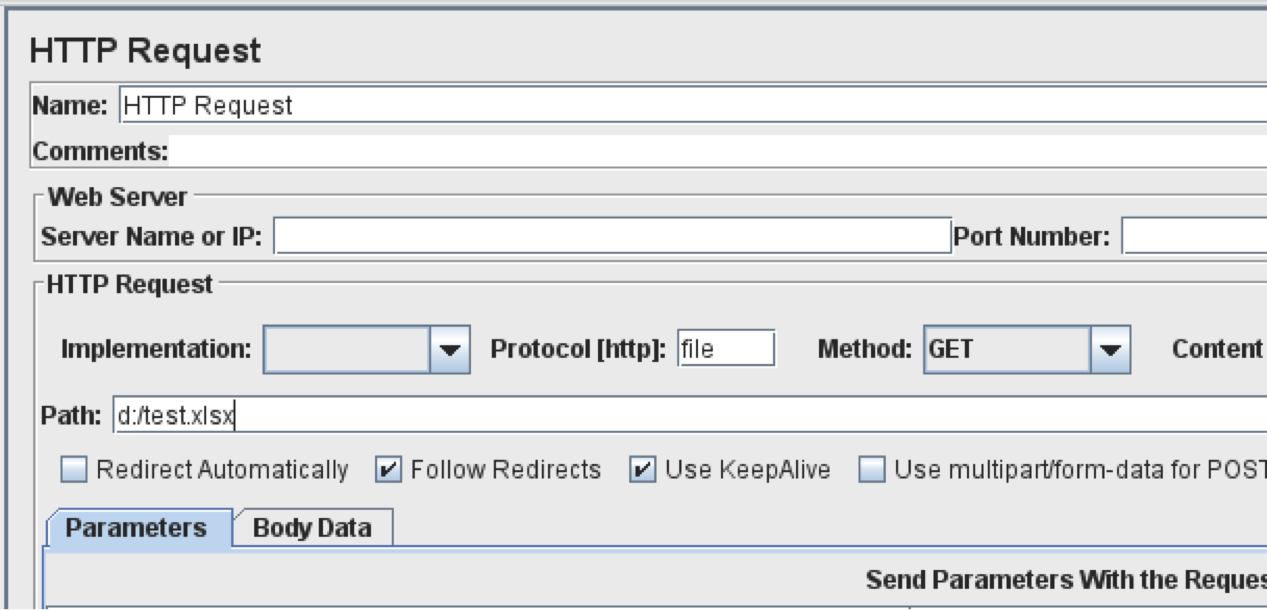
我使用本地Apache Tomcat应用程序服务器获取“test.xlsx”文件,但JMeter的HTTP Request采样器也可以从本地文件系统中获取文件。只需在“协议”字段中输入“文件”,并在“路径”字段中提供完整路径(如下面的屏幕截图所示)。
以下是“查看结果树监听器”中“采样器结果”选项卡的外观:
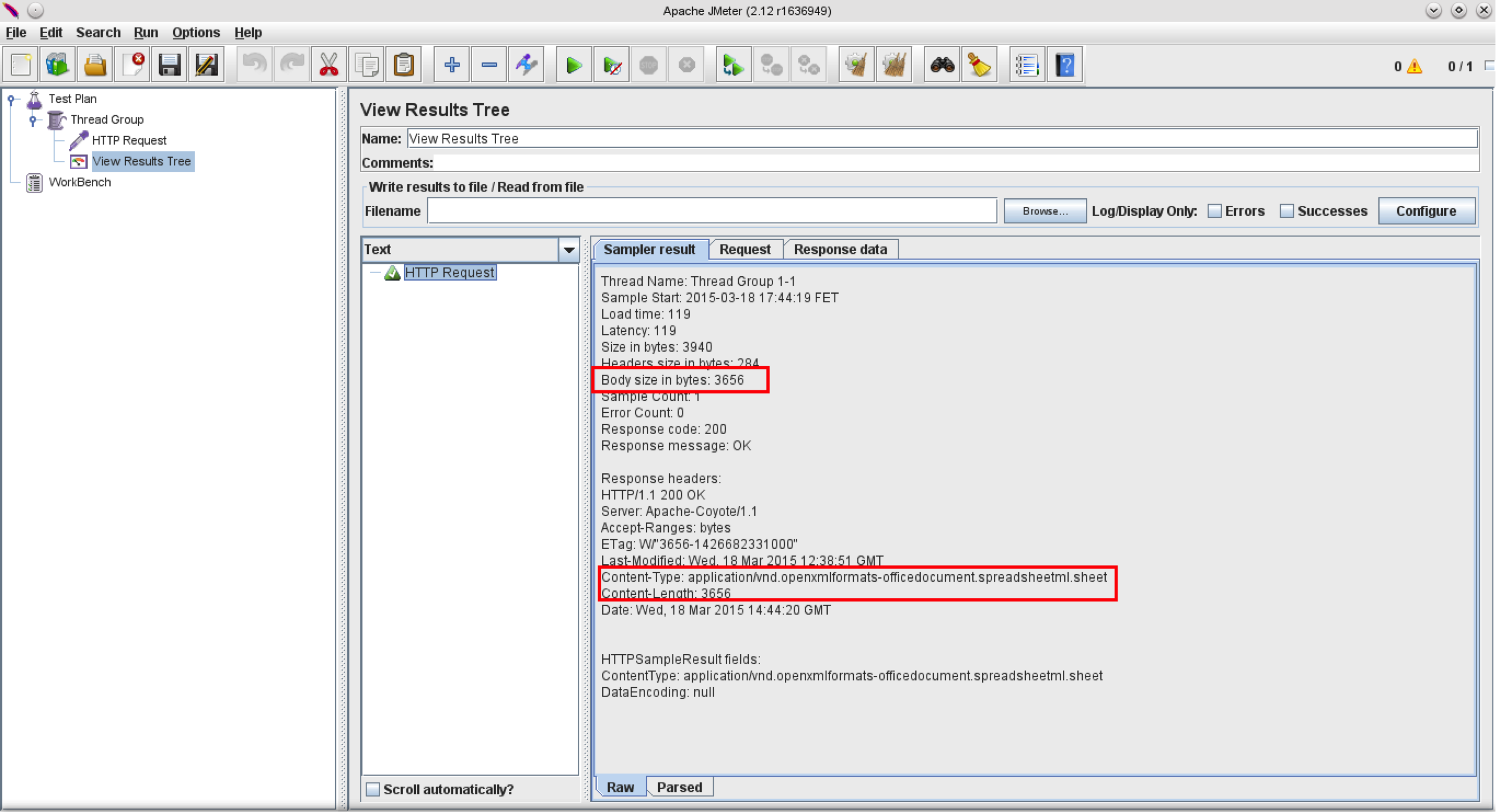
这表明JMeter识别MIME类型(“application / vnd.openxmlformats-officedocument.spreadsheetml.sheet”)并报告正确的响应体大小为3656字节。
现在让我们看看“响应数据”选项卡:
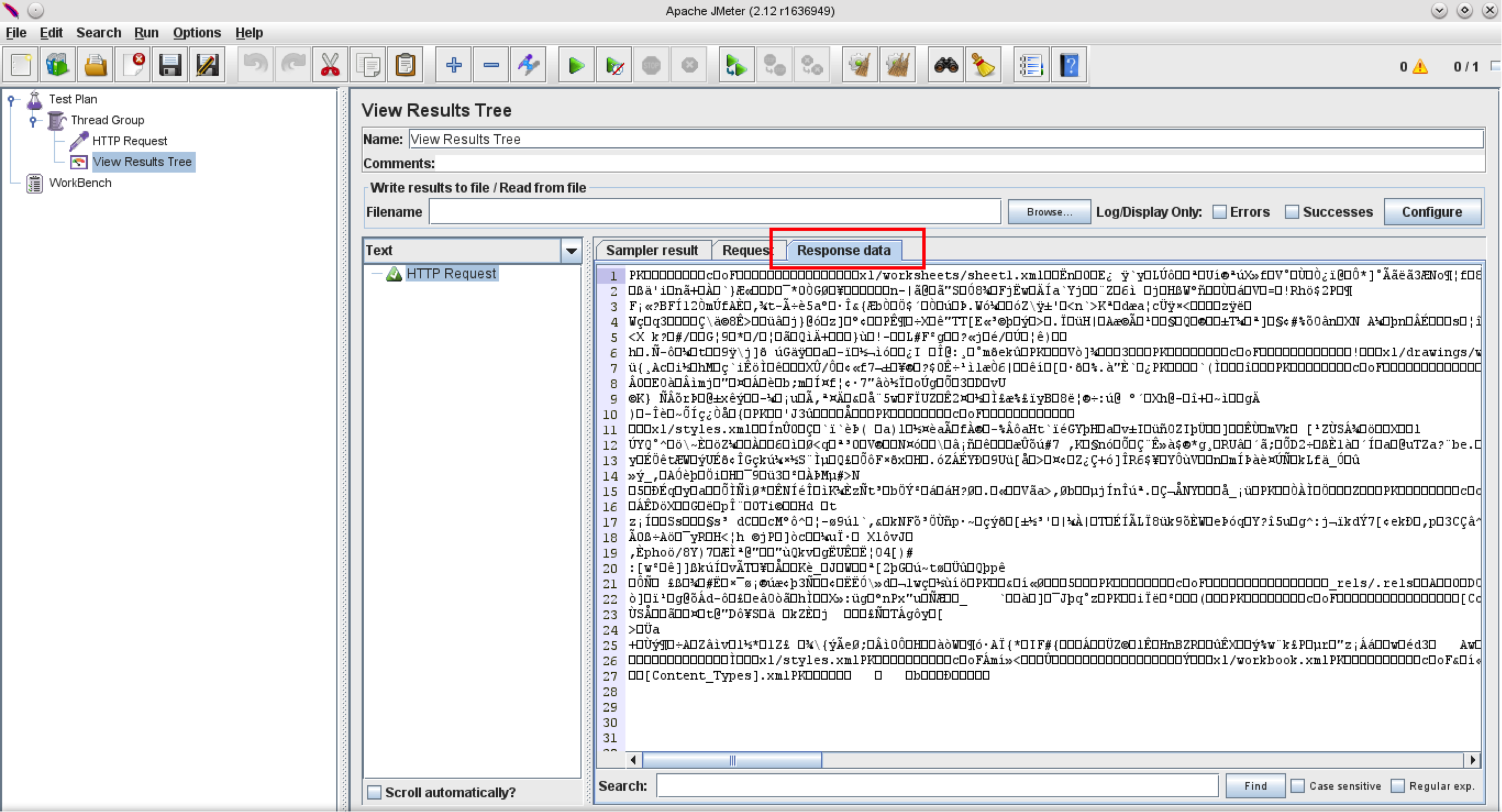
这显示了ZIP存档的文本表示 - 由于其二进制特性而无法读取。
“查看结果树监听器”为您提供了有关如何显示响应数据的一些选项。它可以解析HTML,XML,JSON,提供Regex,CSS和XPath测试功能,还可以显示来自不同文档类型的内容(要做到这一点,你需要在drop中将默认选项“Text”更改为“Document” - 在左上角)
让我们切换到“文档”选项
现在我们可以看到JMeter的CLASSPATH中缺少“tika-app.jar”。要启用基于非文本的响应解析,您需要从Apache Tika下载页面下载tika-app - * .jar 并将其放入JMeter安装的/ lib文件夹中。Asterisk(*)代表这个版本。最新的一个应该没问题但是如果它不起作用,在JMeter的/ lib文件夹中查找tika-core - * .jar和tika-parsers - * .jar文件并下载相关的tika-app.jar。
这里有些例子:
JMeter 2.12附带了tika-core-1.6.jar和tika-parsers-1.6.jar。因此,如果您使用的是JMeter 2.12,那么下载tika-app-1.6.jar是值得的
JMeter 2.13附带了tika-core-1.7.jar和tika-parsers-1.7.jar。在这种情况下,你需要tika-app-1.7.jar
话虽如此,我建议尽可能使用最新的JMeter版本,因为它将包含错误修复,性能改进和新功能。
将tika-app - * .jar添加到/ lib文件夹后,重启所有正在运行的JMeter实例实例非常重要,因为拾取外部.jar文件的过程不是动态的。这也适用于JMeter插件,JUnit测试等。
因此,让我们看看响应如何将tika-app.jar添加到JMeter的类路径中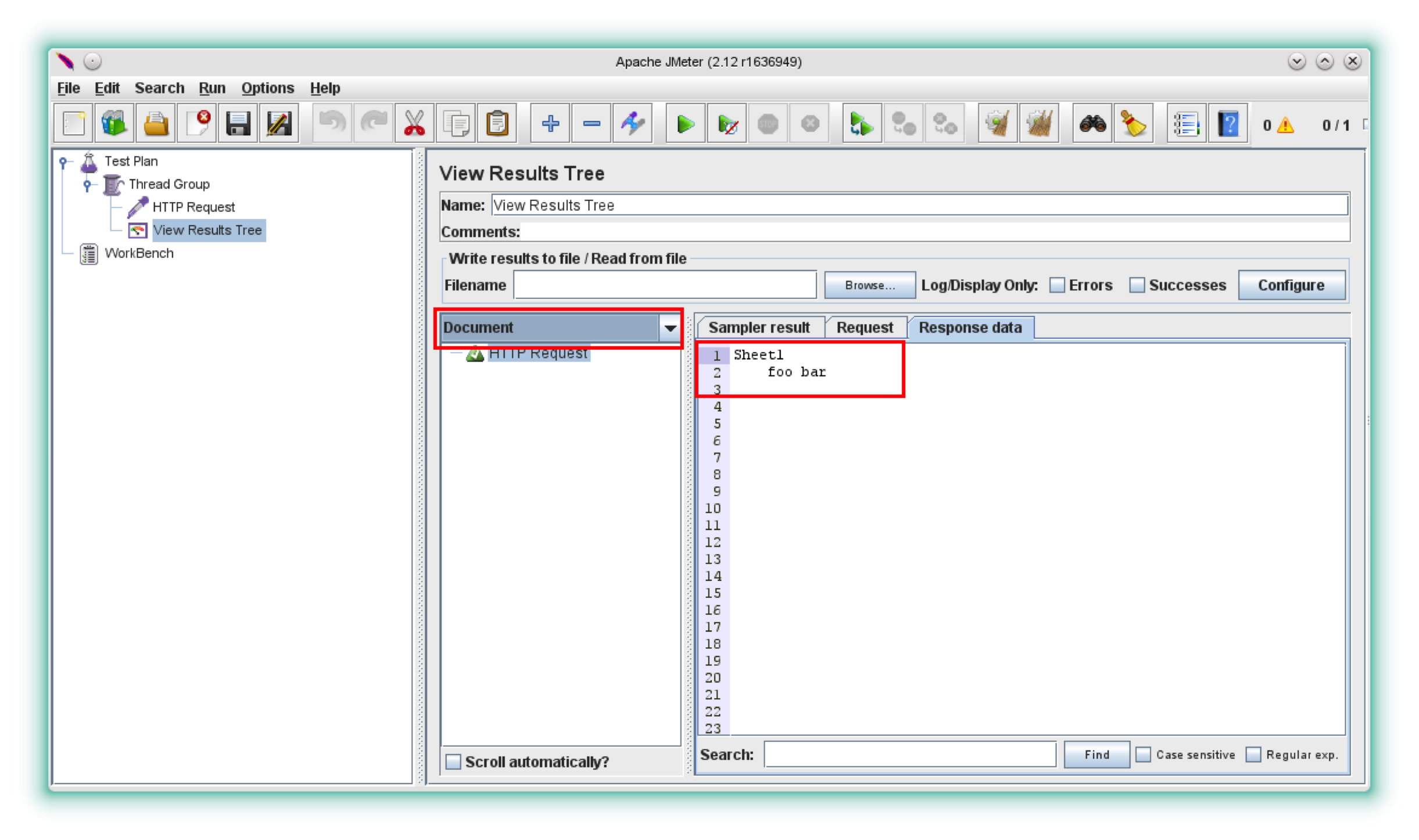
现在我们可以看到工作表的标题以及A1和B1单元格的值。
如何访问二进制文件的内容
有时仅仅“看到”内容是不够的。如果您需要对提取的数据执行某些操作,例如将其用作下一个请求的参数或验证实际响应是否包含“foo”字符串,该怎么办?
让我们看看我们是否可以使用正则表达式提取器从Excel文档中获取内容。首先,让我们将整个响应保存到JMeter变量中。
如何将采样器响应保存到JMeter变量中
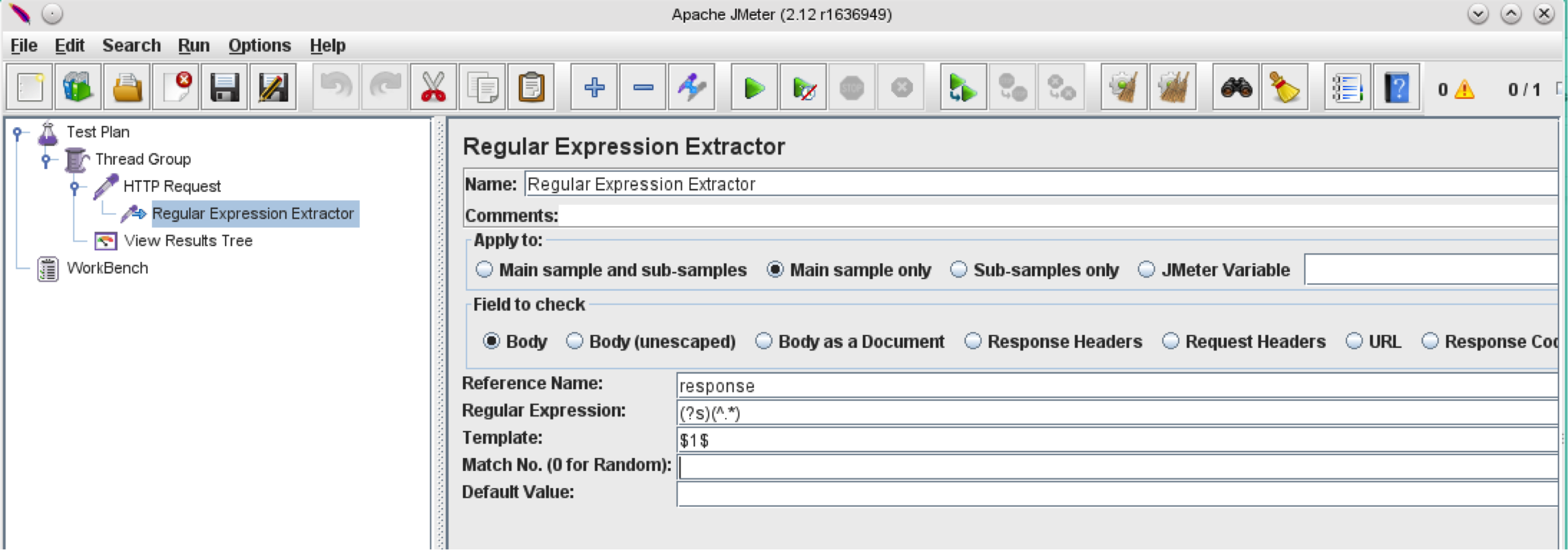
在这里,我将向您展示如何构造匹配整个响应的正则表达式。
请查看JMeter用户手册的正则表达式部分。在这里,我们可以识别元和控制字符,以开发一个匹配响应中所有内容的正则表达式:
() = grouping
(?s) = single line modifier
^ = line start
. = wild-card character
* = repetition
因此,将返回整个响应的正则表达式应如下所示:
(?s)(^.*)
并且整个Regular Expression Extractor Post Processor应如下所示:
现在我们想看到“响应”变量值。让我们在HTTP请求和视图结果树监听器之间添加一个Debug Sampler,然后再次运行测试。
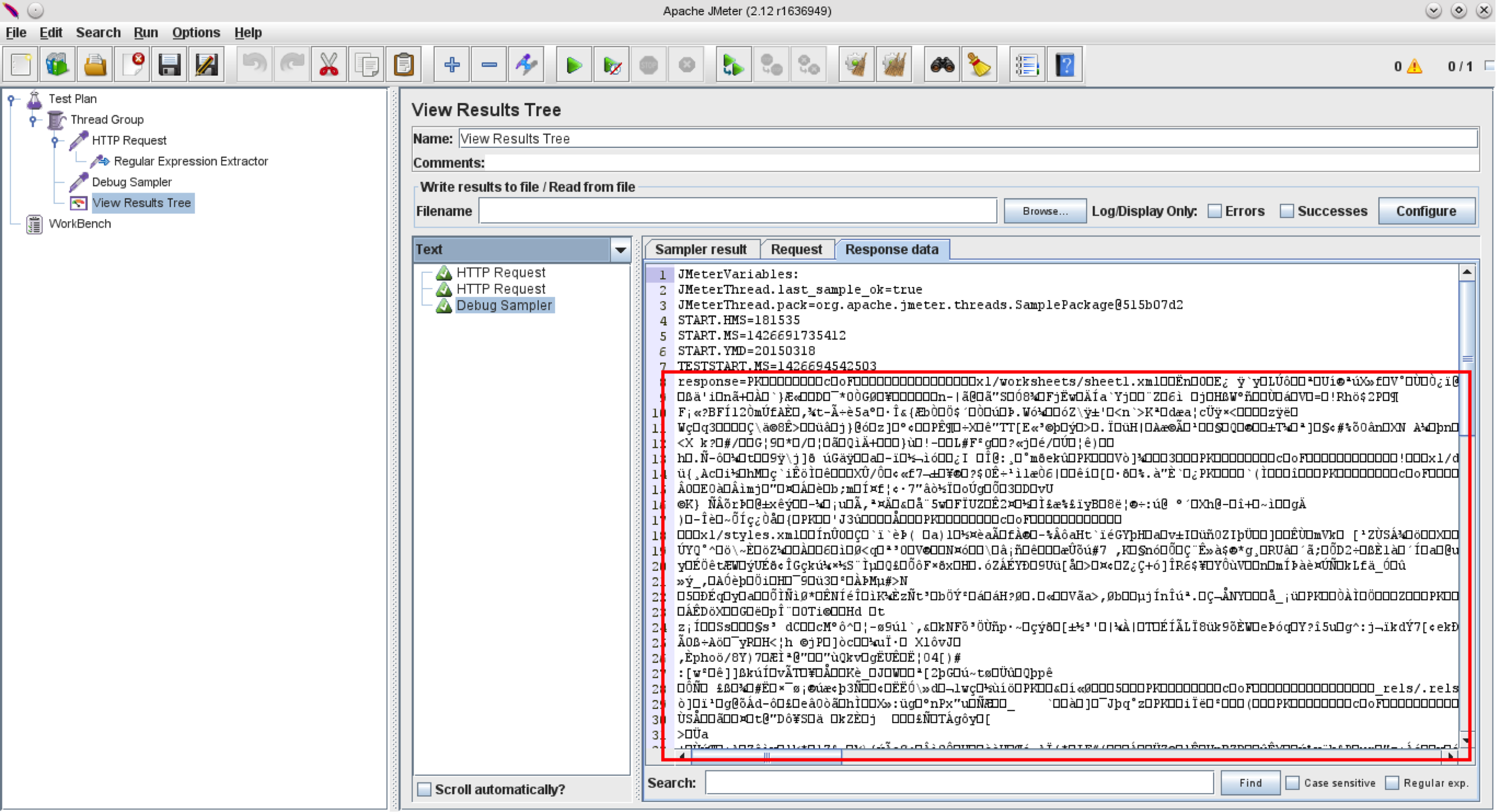
这有点令人失望!:(
显然,正则表达式提取器不适用于已解析的响应,它只返回二进制文件内容,该内容不是非常有用或有用。但是如果JMeter显示Excel文件内容,则应该可以获得它。让我们更深入一点,看看JMeter的View Results Tree Listener如何显示Excel文件内容。
这里是:org.apache.jmeter.util.Document.String getTextFromDocument(byte [] document)。正如它在此处所述,您使用Apache Tika将多种文档(包括odt,ods,odp,doc(x),xls(x),ppt(x),pdf,mp3,mp4等)转换为文本。
因此,让我们删除正则表达式提取器并添加Beanshell Post Processor。
将以下代码插入Beanshell的后处理器的“脚本”区域
import org.apache.jmeter.util.Document; String converted = Document.getTextFromDocument(data);
vars.put("response", converted);
哪里:
第1行 - 导入以解析Document类
第2行 - 调用getTextFromDocument方法
data - 这是一个预定义的Beanshell变量,它将父采样器响应保存为字节数组
将结果存储到转换的字符串对象中
创建JMeter变量响应并为其分配已转换字符串的值
有关Beanshell脚本域的更多信息以及更多有用的提示和技巧,请参阅如何使用BeanShell:JMeter最喜欢的内置组件指南。
现在让我们重试请求,看看这次是怎么回事。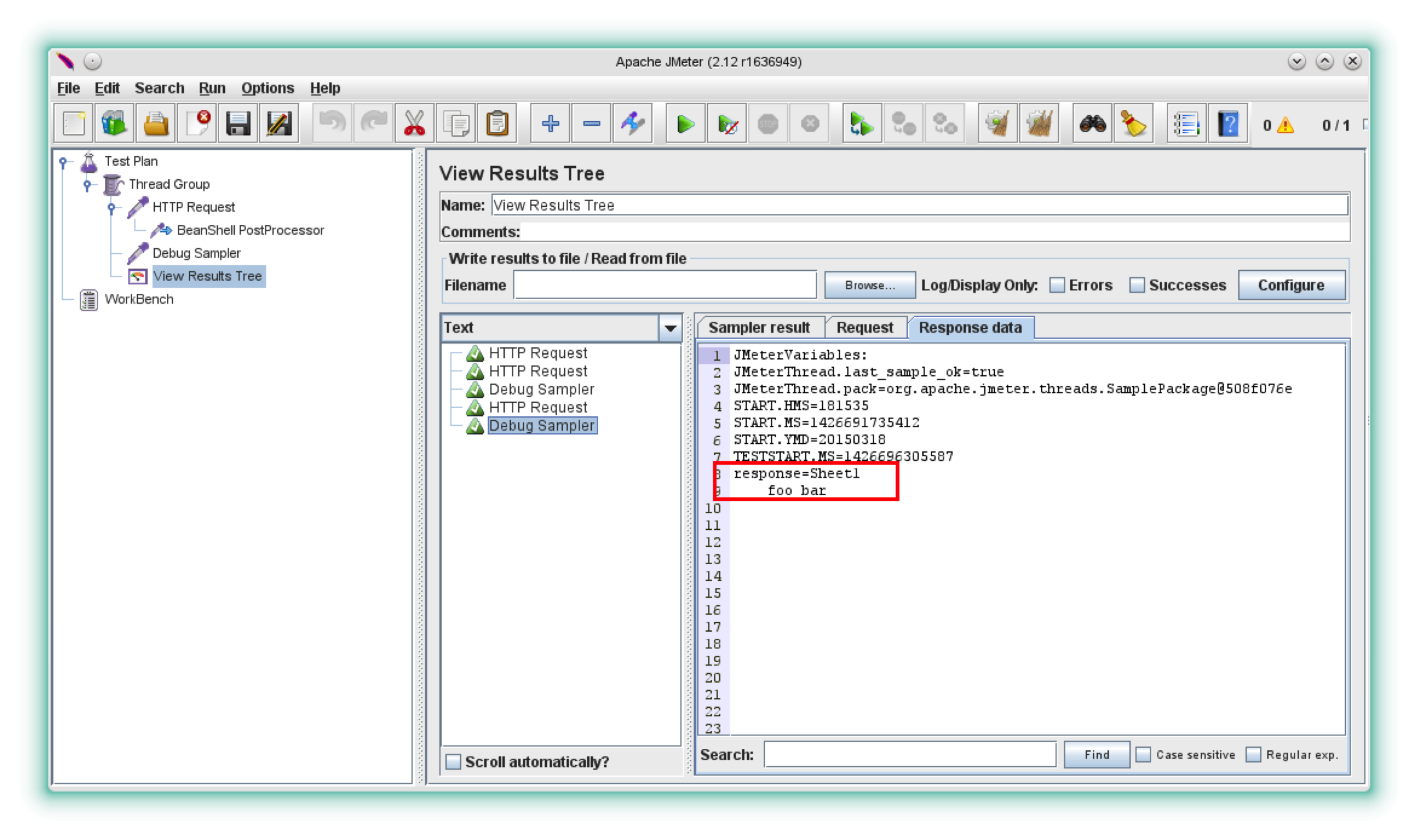
如您所见,您现在可以将整个文件内容称为:$ {response} JMeter Variable。更重要的是:您可以将后处理器和断言应用于它。
如何解析二进制文件
最后,让我们看一下如何以更智能的方式处理二进制文件。我已经介绍了如何将二进制文件内容转换为JMeter变量,现在我将介绍如何访问单个元素。
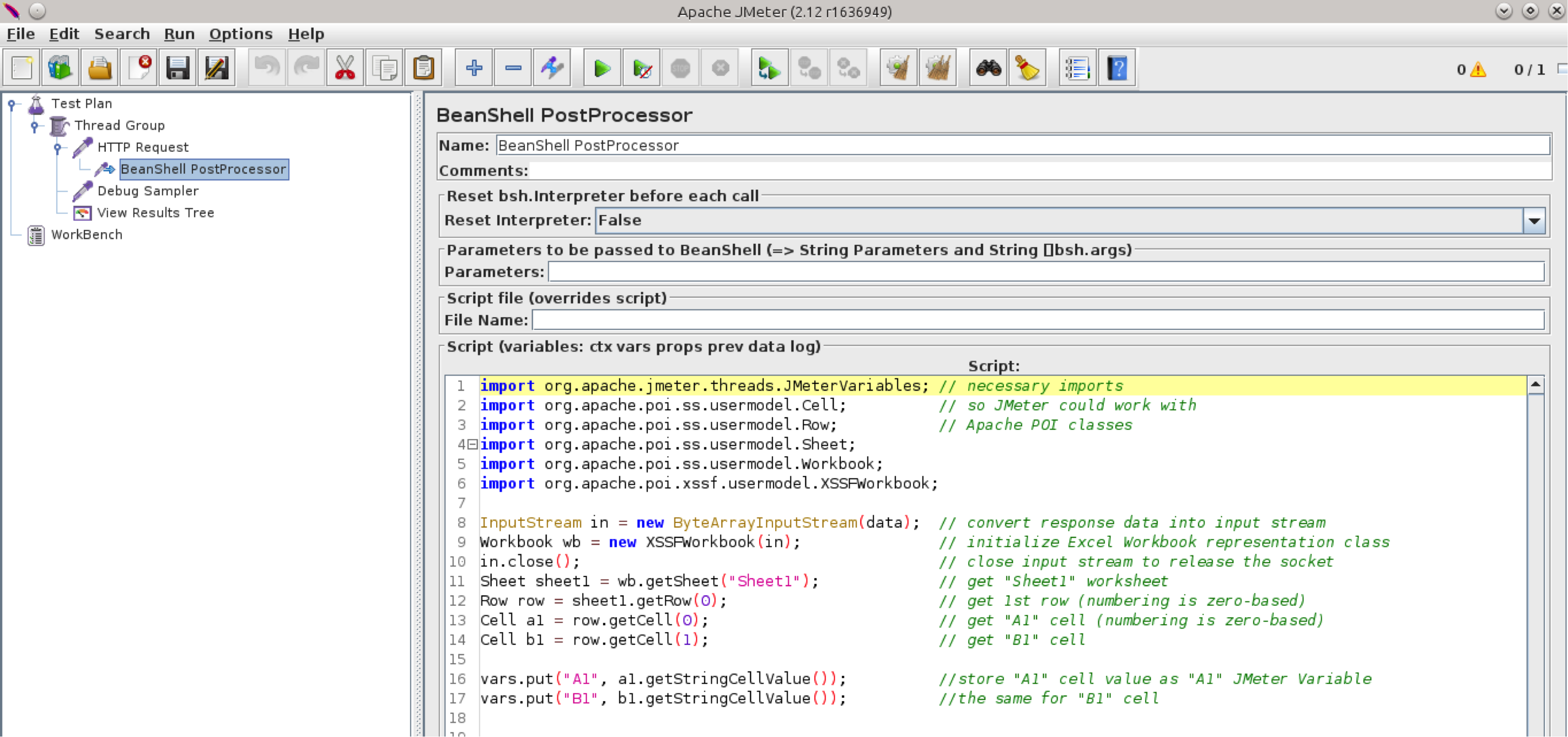
让我们以示例Excel文件为例,从A1和B1单元格中提取值。
Apache Tika二进制文件包括几个能够处理文档文件类型,多媒体文件,存档等的库。它使用Apache POI API for Microsoft文件类型,因此我们需要使用Apache POI类来提取单元格内容来自Excel文档(请参阅有关使用Spreadsheets获取代码示例的POI快速指南以及有关如何执行此操作的更多信息)。
所以我们示例中的代码如下所示:
import org.apache.jmeter.threads.JMeterVariables;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.usermodel.Sheet;
import org.apache.poi.ss.usermodel.Workbook;
import org.apache.poi.xssf.usermodel.XSSFWorkbook; InputStream in = new ByteArrayInputStream(data);
Workbook wb = new XSSFWorkbook(in);
in.close();
Sheet sheet1 = wb.getSheet("Sheet1");
Row row = sheet1.getRow(0);
Cell a1 = row.getCell(0);
Cell b1 = row.getCell(1); vars.put("A1", a1.getStringCellValue());
vars.put("B1", b1.getStringCellValue());
这意味着我们的Beanshell PostProcessor将如下所示:
让我们再次运行测试,并在Debug Sampler中查看A1和B1的变量值
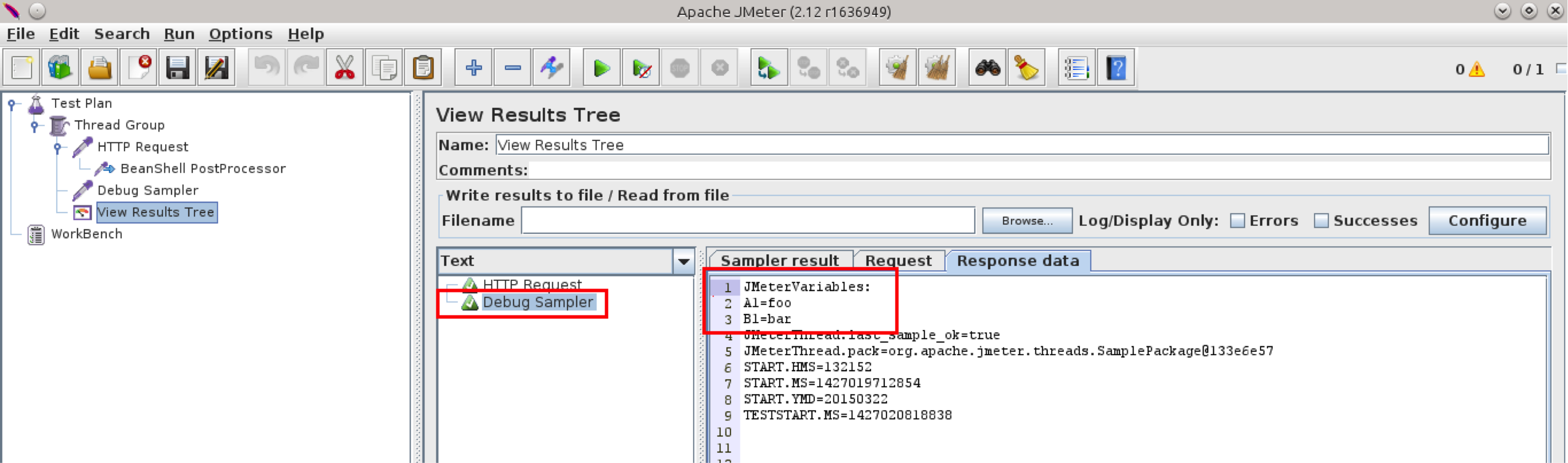
如您所见,有两个变量(不包括预定义的变量)
A1=foo
B1=bar
$ {A1}和$ {B1}可用作参数,后处理器的目标,断言等。
而已!!现在我们知道如何使用JMeter和Tika从Excel文档中提取数据。
这只是Apache Tika 300多种格式中的一种 - 但我认为我不能在一篇博文中涵盖所有这些格式!如果您使用的是Excel之外的其他内容,请查看Tika支持的格式页面以确定实现库和类。然后阅读文档以了解如何正确提取它。
如何使用JMeter从文件中提取数据的更多相关文章
- [数据科学] 从csv, xls文件中提取数据
在python语言中,用丰富的函数库来从文件中提取数据,这篇博客讲解怎么从csv, xls文件中得到想要的数据. 点击下载数据文件http://seanlahman.com/files/databas ...
- 使用Python从PDF文件中提取数据
前言 数据是数据科学中任何分析的关键,大多数分析中最常用的数据集类型是存储在逗号分隔值(csv)表中的干净数据.然而,由于可移植文档格式(pdf)文件是最常用的文件格式之一,因此每个数据科学家都应该了 ...
- matlab从fig文件中提取数据
如果你的fig文件中图像是由多条曲线绘制而成,比如说plot命令生成的,通过以下方式输出横坐标,纵坐标的取值 open('figname.fig'); lh = findall(gca, 'type' ...
- [数据科学] 从text, json文件中提取数据
文本文件是基本的文件类型,不管是csv, xls, json, 还是xml等等都可以按照文本文件的形式读取. #-*- coding: utf-8 -*- fpath = "data/tex ...
- 利用ROS工具从bag文件中提取图片
bag文件是ROS常用的数据存储格式,因此要从bag文件中提取数据就需要了解一点ROS的背景知识. 1. 什么是ROS及其优势 ROS全称Robot Operating System,是BSD-lic ...
- JMETER从JSON响应中提取数据
如果你在这里,可能是因为你需要使用JMeter从Json响应中提取变量. 好消息!您正在掌握掌握JMeter Json Extractor的权威指南.作为Rest API测试指南的补充,您将学习掌握J ...
- 如何使用JMETER从JSON响应中提取数据
如果你在这里,可能是因为你需要使用JMeter从Json响应中提取变量. 好消息!您正在掌握掌握JMeter Json Extractor的权威指南.作为Rest API测试指南的补充,您将学习掌握J ...
- 嵌入式 H264—MP4格式及在MP4文件中提取H264的SPS、PPS及码流
一.MP4格式基本概念 MP4格式对应标准MPEG-4标准(ISO/IEC14496) 二.MP4封装格式核心概念 1 MP4封装格式对应标准为 ISO/IEC 14496-12(信息技术 视听对象 ...
- [转]【流媒體】H264—MP4格式及在MP4文件中提取H264的SPS、PPS及码流
[流媒體]H264—MP4格式及在MP4文件中提取H264的SPS.PPS及码流 SkySeraph Apr 1st 2012 Email:skyseraph00@163.com 一.MP4格式基本 ...
随机推荐
- 0-mybatis目录
mybatis 第一天: 对原生态jdbc程序(单独使用jdbc开发)问题总结 框架原理 入门程序 用户的增.删.改.查 开发dao两种方法: 原始dao开发方法(程序需要编写dao接口和dao实现类 ...
- BZOJ 1657 [Usaco2006 Mar]Mooo 奶牛的歌声:单调栈【高度序列】
题目链接:http://www.lydsy.com/JudgeOnline/problem.php?id=1657 题意: Farmer John的N(1<=N<=50,000)头奶牛整齐 ...
- 我所理解的RESTful Web API [设计篇]【转】
原文:http://www.cnblogs.com/artech/p/restful-web-api-02.html <我所理解的RESTful Web API [Web标准篇]>Web服 ...
- 分享知识-快乐自己:Oracle基本语法(创建:表空间、用户、授权、约束等)使用指南
Oracle12c 与 Oracle11g 创建用户时有差别.Oracle12C默认为 CDB模式 这时创建用户的时候需要加上 c## 开头:例如:c##MLQ. --说明--需求:创建表空间(MLQ ...
- leetcode 67. Add Binary (高精度加法)
Given two binary strings, return their sum (also a binary string). For example,a = "11"b = ...
- C语言中的指针(二)
指针指向谁,就把谁的地址赋给指针,指针变量和指针指向的内存变量是不一样的.不停的给指针赋值,相当于是不断的改变指针的指向. 在开发中要避免野指针的存在,在指针使用完毕之后,记得要给指针赋值成为NULL ...
- <C++>友元与虚函数的组合
为类重载<<与>>这两个运算符时,重载函数必须为该类的友元函数. 当友元不能被继承,故不能当作虚函数,无法使用多态. 可以用以下结构实现友元与虚函数的组合. class bas ...
- ls命令还能这么玩
排序文件大小: 我们希望以文件大小排序,我们可以使用-S 参数来这么做 如果希望文件大小从小到大排序: 如果只希望列出目录条目: 增加 /(斜线) 标记目录:要这么做,使用-p选项: 通过修改时间列出 ...
- poj3585树最大流——换根法
题目:http://poj.org/problem?id=3585 二次扫描与换根法,一次dfs求出以某个节点为根的相关值,再dfs遍历一遍树,根据之前的值换根取最大值为答案. 代码如下: #incl ...
- 关于ajaxfileupload的使用方法以及一些问题
使用问题: 1.ajax-fileupload.js handleError 异常 由于本来handleError方法是jquery的方法,但jquery到了某个版本这个方法就去掉了没有了 所以最简单 ...