SLAM概念学习之随机SLAM算法
这一节,在熟悉了Featue maps相关概念之后,我们将开始学习基于EKF的特征图SLAM算法。
1. 机器人,图和增强的状态向量
随机SLAM算法一般存储机器人位姿和图中的地标在单个状态向量中,然后通过一个递归预测和量测过程来估计状态参数。其中,预测阶段通过增量航迹估计来处理机器人的运动,并增加了机器人位姿不确定性的估计。当再次观测到Map中存储的特征后,量测阶段,或者叫更新阶段开始执行,这个过程可以改善整个的状态估计。当机器人在运动过程中观测到新特征时,便通过一个状态增强的过程将新观测的特征添加到状态向量中。
机器人的状态,即一个相对于参考笛卡尔坐标系的自身位姿参数通过均值和协方差来定义:
 (1)
(1)
 (2)
(2)
图的协方差矩阵Pm 包含特征之间的互相关信息(即非对角项),这些交叉关联信息表征了每个特征对Map中其他特征相关信息的依赖。由于特征的位置是静态的,当周围的环境也即Map是刚性的话,特征之间的交叉关联将会随着的特征的二次观测增强。图中的特征可以表示如下
 (3)
(3)
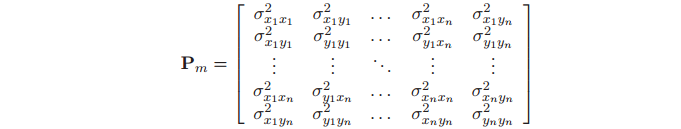 (4)
(4)
SLAM中的图通过一个串联了机器人位姿和特征图状态的增强状态向量定义,如图1所示。这是很有必要的,因为一致的SLAM依赖于机器人位姿和图之间相关性Pvm
 (5)
(5)
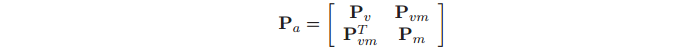 (6)
(6)

Fig. 1 增强的状态向量.
需要注意的是,状态的初始化时通常为 和
和 .也就是说,还没有特征被机器人观测到,并且初始时刻机器人位于参考坐标系的原点。
.也就是说,还没有特征被机器人观测到,并且初始时刻机器人位于参考坐标系的原点。
2. 预测阶段
随机SLAM算法的过程模型根据航迹推算运动估计来确定机器人相对于先前时刻位姿的运动,图特征仍然保持静止。这个模型对状态估计的影响存在于状态向量 部分和状态协方差矩阵中的
部分和状态协方差矩阵中的 以及
以及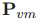 项。而
项。而 和
和 这些图特征相关项仍保持不变。
这些图特征相关项仍保持不变。
估计带来的机器人(这里以移动小车为例)位姿变化 和协方差
和协方差 通常用车轮的编码器测量和小车对应的运动学模型获取。本文里面的位姿改变通过基于激光测距的航迹推算获取,该算法可以通过批处理数据关联算法来找出序列激光扫描之间的相对位姿关系。
通常用车轮的编码器测量和小车对应的运动学模型获取。本文里面的位姿改变通过基于激光测距的航迹推算获取,该算法可以通过批处理数据关联算法来找出序列激光扫描之间的相对位姿关系。

Fig. 2 机器人位姿变化示意.
因此,预测的增强状态可以表示为
 (7)
(7)
 (8)
(8)
其中,雅各比矩阵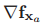 和
和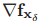 的定义为
的定义为
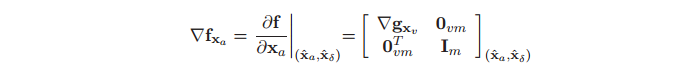 (9)
(9)
 (10)
(10)
雅各比矩阵 和
和 定义为
定义为
 (11)
(11)
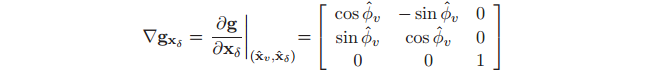 (12)
(12)
因为雅各比矩阵仅仅影响机器人的协方差矩阵 和对应的交叉相关性
和对应的交叉相关性 ,方程(8)用下式高效地实现
,方程(8)用下式高效地实现
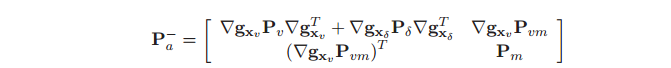 (13)
(13)
3. 更新阶段
如果已经存储在图中的估计特征 被距离方位传感器二次观测到,此时对应的量测量可以表示为
被距离方位传感器二次观测到,此时对应的量测量可以表示为
 (14)
(14)
 (15)
(15)
其中,量测量 分别表示对应的距离值和相对于观测机器人的偏转角度。
分别表示对应的距离值和相对于观测机器人的偏转角度。 为量测协方差。传感器获取的量测值和图之间的关联可以通过下面的方程表示
为量测协方差。传感器获取的量测值和图之间的关联可以通过下面的方程表示
 (16)
(16)
Kalman增益 可以得到
可以得到
 (17)
(17)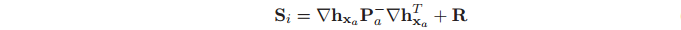 (18)
(18)
 (19)
(19)
其中,雅各比矩阵 为
为
 (20)
(20)
对于包含许多特征的SLAM图,雅各比矩阵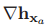 将会含有许多零项,这会使得方程(18)和(19)的计算非常高效。
将会含有许多零项,这会使得方程(18)和(19)的计算非常高效。
随后我们可以从更新过程得到一个后验SLAM估计
 (21/22)
(21/22)
实践表明,如果几个独立的量测同时可用,即知道 ,便有可能获取更加精确的更新。
,便有可能获取更加精确的更新。
4. 状态增强
当机器人在环境中漫游时,一旦新特征被观测到,就必须存储到图中。接下来将给出新观测到的特征初始化方法,首先,状态向量和对应的协方差矩阵通过新的量测的极值增强为
 (23)
(23)
 (24)
(24)
量测z 通过函数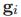 被转换位全局的笛卡尔坐标系特征位置,对应的变换表示如下
被转换位全局的笛卡尔坐标系特征位置,对应的变换表示如下
 (25)
(25)
可以通过线性化函数 将增强的状态初始化
将增强的状态初始化
 (26/27)
(26/27)
其中,雅克比矩阵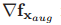 表示为
表示为
 (28)
(28)
与特征的储存相比,特征的删除非常简单,只需将特征对应的元素直接从状态向量删除,同时将相关的行和列中的项目从协方差矩阵中删除。
SLAM概念学习之随机SLAM算法的更多相关文章
- SLAM概念学习之特征图Feature Maps
特征图(或者叫地标图,landmark maps)利用参数化特征(如点和线)的全局位置来表示环境.如图1所示,机器人的外部环境被一些列参数化的特征,即二维坐标点表示.这些静态的地标点被观测器(装有传感 ...
- Bagging与随机森林算法原理小结
在集成学习原理小结中,我们讲到了集成学习有两个流派,一个是boosting派系,它的特点是各个弱学习器之间有依赖关系.另一种是bagging流派,它的特点是各个弱学习器之间没有依赖关系,可以并行拟合. ...
- R语言︱决策树族——随机森林算法
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 笔者寄语:有一篇<有监督学习选择深度学习 ...
- R语言︱机器学习模型评估方案(以随机森林算法为例)
笔者寄语:本文中大多内容来自<数据挖掘之道>,本文为读书笔记.在刚刚接触机器学习的时候,觉得在监督学习之后,做一个混淆矩阵就已经足够,但是完整的机器学习解决方案并不会如此草率.需要完整的评 ...
- Python机器学习笔记——随机森林算法
随机森林算法的理论知识 随机森林是一种有监督学习算法,是以决策树为基学习器的集成学习算法.随机森林非常简单,易于实现,计算开销也很小,但是它在分类和回归上表现出非常惊人的性能,因此,随机森林被誉为“代 ...
- 使用Numpy验证Google GRE的随机选择算法
最近在读<SRE Google运维解密>第20章提到数据中心内部服务器的负载均衡方法,文章对比了几种负载均衡的算法,其中随机选择算法,非常适合用 Numpy 模拟并且用 Matplotli ...
- H2O中的随机森林算法介绍及其项目实战(python实现)
H2O中的随机森林算法介绍及其项目实战(python实现) 包的引入:from h2o.estimators.random_forest import H2ORandomForestEstimator ...
- 用Python实现随机森林算法,深度学习
用Python实现随机森林算法,深度学习 拥有高方差使得决策树(secision tress)在处理特定训练数据集时其结果显得相对脆弱.bagging(bootstrap aggregating 的缩 ...
- 随机森林算法-Deep Dive
0-写在前面 随机森林,指的是利用多棵树对样本进行训练并预测的一种分类器.该分类器最早由Leo Breiman和Adele Cutler提出.简单来说,是一种bagging的思想,采用bootstra ...
随机推荐
- C++小程序(1)——文件整理工具
网上下载的漫画是jpg或png之类的图片文件,用系统自带的图片管理器看不方便,想要能把图片想网页一样浏览的功能,找了很多图片管理器也没有带这个功能,于是就自己编写了一个小程序实现. 思想就是在图片目录 ...
- Unity 需不需要再建Assets文件夹
不需要,默认所有文件都是在Assets文件夹下创建的,看不到是因为设置了单栏模式,开启双栏模式就能看到了.
- 构造器参数过多时考虑使用构建器(Builder)
一.静态工厂和构造器的局限性 面对需要大量可选参数才能构建对象时,静态工厂和构造器并不能随着可选参数的增加而合理扩展. 假设创建一个类Person需要使用大量的可选参数,其中两个参数是必填的,剩下的都 ...
- 解决PL/SQL管理工具database下拉为空和登录出现ORA-12154
前言:昨天捣鼓了一下午,终于可以用plsql连接上oracle了... 测试环境:win10 注意问题: (一).环境变量 我发现按网上别人说的那一大推环境配置,很容易出错,我把它们全删了,就留了两个 ...
- Facebook再次爆出安全漏洞,9000万用户受影响
今年上半年开始,美国社交媒体Facebook因数据泄露事件和涉嫌操纵选举等问题频繁接受听证会拷问,然而事情却远没有结束.今年9月Facebook再次爆出安全漏洞,导致9000万用户可能受到影响. 根据 ...
- Vue双向绑定原理(源码解析)---getter setter
Vue双向绑定原理 大部分都知道Vue是采用的是对象的get 和set方法来实现数据的双向绑定的过程,本章将讨论他是怎么利用他实现的. vue双向绑定其实是采用的观察者模式,get和s ...
- [CodeForces]500B New Year Permutation
刷水题做几道入门贪心题预热... 找联通块里字典序最小的放到最前面即可.记得写传递闭包 #include <iostream> #include <cstdio> #inclu ...
- [读书笔记] Python数据分析 (四) 数组和矢量计算
Numpy:高性能计算和数学分析的基础包 ndarray, 一个具有矢量算术运算和复杂广播能力的快速且节省空间的多维数组 用于对数组数据进行快速运算的标准数学函数 用于读写磁盘数据的工具和用于操作内存 ...
- ArchLinux出现ACPI ERROR的解决方法
ArchLinux关机.重启时出现ACPI错误: ACPI Error:Method parse/execution failed \_SB.PCI0.PGON,AE_AML_LOOP_TIMEOUT ...
- 紫书 习题7-14 UVa 307(暴搜+剪枝)
这道题一开始我想的是在排序之后只在头和尾往中间靠近来找木块, 然后就WA, 事实证明这种方法是错误的. 然后参考了别人的博客.发现别人是直接暴搜, 但是加了很多剪枝, 所以不会超时. 我也想过这个做法 ...