linux源码分析(三)-start_kernel
前置:这里使用的linux版本是4.8,x86体系。
start_kernel是过了引导阶段,进入到了内核启动阶段的入口。函数在init/main.c中。
set_task_stack_end_magic(&init_task);
这个函数是设置操作系统的第一个进程init。
这个init_task变量是怎么来的呢?从init/init_task.c中初始化的。
struct task_struct init_task = INIT_TASK(init_task);
EXPORT_SYMBOL(init_task);
而这个INIT_TASK的初始化在init/init_task.h:
#define INIT_TASK(tsk) \
{ \
.state = 0, \
.stack = init_stack, \
.usage = ATOMIC_INIT(2), \
.flags = PF_KTHREAD, \
.prio = MAX_PRIO-20, \
.static_prio = MAX_PRIO-20, \
.normal_prio = MAX_PRIO-20, \
...
这里使用的是gcc的结构体初始化方式。http://blog.csdn.net/justlinux2010/article/details/7494754 。这个结构体是根据task_struct结构进行初始化的。
再回到set_task_stack_end_magic
void set_task_stack_end_magic(struct task_struct *tsk)
{
unsigned long *stackend;
stackend = end_of_stack(tsk);
*stackend = STACK_END_MAGIC; /* for overflow detection */
}
这个end_of_stack 在include/linux/sched.h中。它的意思是获取栈边界地址。然后把栈底地址设置为STACK_END_MAGIC。这个作为栈溢出的标记。
每个进程创建的时候,系统会为这个进程创建2个页大小的内核栈。这个内核栈底下是thread_info结构。高位是栈。
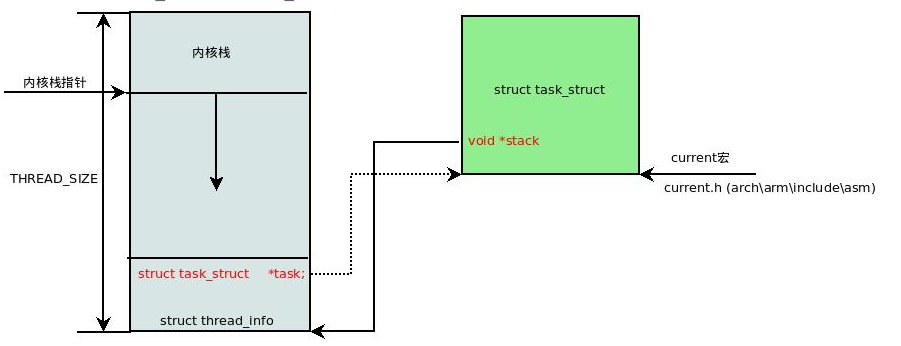
http://blog.chinaunix.net/uid-20543672-id-2996319.html
这里的STACK_END_MAGIC就是设置在thread_info结构的上面。比如如果你写了一个无限循环,导致栈使用不断增长了,那么,一旦把这个标记未修改了,就导致了栈溢出的错误。
smp_setup_processor_id();
下面是这个
smp_setup_processor_id(); // 设置smp模型的处理器id
smp模型指的是对称多处理模型(Symmetric Multi-Processor),与它对应的是NUMA非一致存储访问结构(Non-Uniform Memory Access)和MPP 海量并行处理结构(Massive Parallel Processing)。它们的区别分别在于,SMP指的是多个CPU之间是平等关系,共享全部总线,内存和I/O等。但是这个结构扩展性不好,往往CPU数量多了之后,很容易遇到抢占资源的问题。NUMA结构则是把CPU分模块,每个模块具有独立的内存,I/O插槽等。各个模块之间通过互联模块进行数据交互。但是这样,就表示了有的内存数据在这个CPU模块中,那么处理这个数据当然最好是选择当前的CPU模块,这样每个CPU实际上地位就不一致了。所以叫做非一致的存储访问结构。而MPP呢,则是由多个SMP服务器通过互联网方式连接起来。
支持SMP模型的CPU有AMD/AMD64。而支持NUMA的有X86等。而这里的代码,smp_setup_process_id在普通情况下是空实现,在不同的体系,比如arch/arm/kernel/setup.c, line 586
就有对应的逻辑了。
debug_objects_early_init();
这个函数的实际代码在lib/debugobject.c
void __init debug_objects_early_init(void)
{
int i;
for (i = 0; i < ODEBUG_HASH_SIZE; i++)
raw_spin_lock_init(&obj_hash[i].lock);
for (i = 0; i < ODEBUG_POOL_SIZE; i++)
hlist_add_head(&obj_static_pool[i].node, &obj_pool);
}
可以看到,它主要是用来对obj_hash,obj_static_pool这两个全局变量进行初始化设置。这两个全局变量在进行调试的时候会使用到。
http://m.blog.chinaunix.net/uid-27717694-id-4425488.html
boot_init_stack_canary();
这个函数是做什么的呢?我们要说堆栈溢出漏洞,它的意思就是动态分配的堆中,不按照本来分配的大小进行设置,而是使用某种方法,设置变量分配大小之外的数据。甚至设置到了函数栈的数据了,那么,这个时候就可能会被调用到注入的某个函数中了。具体攻击示例看:http://www.ibm.com/developerworks/cn/linux/l-overflow/
那么,和前面的end_magic逻辑一样,我们在堆和栈的中介处设置一个标记位(叫做canary word)。当这个位被修改的时候,我们就知道了,这个时候存在堆栈溢出,就进行错误处理。
那么这个标记位的值是怎么样子的,就是使用这个函数。这个也和CPU架构有关系了,比如在x86的系统中,是随机产生的。https://www.ibm.com/developerworks/cn/linux/l-cn-gccstack/
linux源码分析(三)-start_kernel的更多相关文章
- linux源码分析2
linux源码分析 这里使用的linux版本是4.8,x86体系. 这篇是 http://home.ustc.edu.cn/~boj/courses/linux_kernel/1_boot.html ...
- tomcat源码分析(三)一次http请求的旅行-从Socket说起
p { margin-bottom: 0.25cm; line-height: 120% } tomcat源码分析(三)一次http请求的旅行 在http请求旅行之前,我们先来准备下我们所需要的工具. ...
- 使用react全家桶制作博客后台管理系统 网站PWA升级 移动端常见问题处理 循序渐进学.Net Core Web Api开发系列【4】:前端访问WebApi [Abp 源码分析]四、模块配置 [Abp 源码分析]三、依赖注入
使用react全家桶制作博客后台管理系统 前面的话 笔者在做一个完整的博客上线项目,包括前台.后台.后端接口和服务器配置.本文将详细介绍使用react全家桶制作的博客后台管理系统 概述 该项目是基 ...
- Tomcat源码分析三:Tomcat启动加载过程(一)的源码解析
Tomcat启动加载过程(一)的源码解析 今天,我将分享用源码的方式讲解Tomcat启动的加载过程,关于Tomcat的架构请参阅<Tomcat源码分析二:先看看Tomcat的整体架构>一文 ...
- ABP源码分析三:ABP Module
Abp是一种基于模块化设计的思想构建的.开发人员可以将自定义的功能以模块(module)的形式集成到ABP中.具体的功能都可以设计成一个单独的Module.Abp底层框架提供便捷的方法集成每个Modu ...
- ABP源码分析三十一:ABP.AutoMapper
这个模块封装了Automapper,使其更易于使用. 下图描述了改模块涉及的所有类之间的关系. AutoMapAttribute,AutoMapFromAttribute和AutoMapToAttri ...
- ABP源码分析三十三:ABP.Web
ABP.Web模块并不复杂,主要完成ABP系统的初始化和一些基础功能的实现. AbpWebApplication : 继承自ASP.Net的HttpApplication类,主要完成下面三件事一,在A ...
- ABP源码分析三十四:ABP.Web.Mvc
ABP.Web.Mvc模块主要完成两个任务: 第一,通过自定义的AbpController抽象基类封装ABP核心模块中的功能,以便利的方式提供给我们创建controller使用. 第二,一些常见的基础 ...
- ABP源码分析三十五:ABP中动态WebAPI原理解析
动态WebAPI应该算是ABP中最Magic的功能之一了吧.开发人员无须定义继承自ApiController的类,只须重用Application Service中的类就可以对外提供WebAPI的功能, ...
- Duilib源码分析(三)XML解析器—CMarkup
上一节介绍了控件构造器CDialogBuilder,接下来将分析其XML解析器CMarkup: CMarkup:xml解析器,目前内置支持三种编码格式:UTF8.UNICODE.ASNI,默认为UTF ...
随机推荐
- 安卓学习之--UI控件用法 单选 按钮 下拉框
1.单选 .RadioGroup 可将各自不同的RadioButton ,设限于同一个Radio 按钮组,同一个RadioGroup 组里的按钮,只能做出单一选择(单选题). <RadioGro ...
- C# RabbitMq .net 使用
本文转载来自 [http://www.cnblogs.com/yangecnu/p/Introduce-RabbitMQ.html]写的很详细. 文件安装包官方DEMO下载地址是:http://pan ...
- Linux 配置YUM
标签:MYSQL/linux 概述 文章主要介绍配置163,mysql,epel这三个yum源. 目录 概述 步骤 下载安装包 卸载自带的yum 安装yum包 添加yum 总结 步骤 安装163源 注 ...
- 老司机学新平台 - Xamarin开发环境及开发框架初探
随着被微软收购,最近一年间,Xamarin的火爆程度与日俱增.免费.更好的VS2015集成.更好的模拟器,甚至,在windows上运行和调试iOS平台程序,让我这样接触了十几年.NET平台的老司机,即 ...
- Andrew Ng机器学习公开课笔记 -- 学习理论
网易公开课,第9,10课 notes,http://cs229.stanford.edu/notes/cs229-notes4.pdf 这章要讨论的问题是,如何去评价和选择学习算法 Bias/va ...
- 防止SQL注入攻击
了解了SQL注入的方法,如何能防止SQL注入?如何进一步防范SQL注入的泛滥?通过一些合理的操作和配置来降低SQL注入的危险. 使用参数化的过滤性语句 要防御SQL注入,用户的输入就绝对不能直接被嵌入 ...
- JQuery图片切换动画效果
由于博主我懒,所以页面画的比较粗糙,但是没关系,因为我主要讲的是如何实现图片动画切换. 思路:想必大家都逛过淘宝或者其他的一些网站,一般都会有图片动画切换的效果,那是怎样实现的呢?博主我呢,技术不是很 ...
- salesforce 零基础学习(四十九)自定义列表分页之使用Pagination实现分页效果 ※※※
上篇内容为Pagination基类的封装,此篇接上篇内容描述如何调用Pagination基类. 首先先创建一个sObject,起名Company info,此object字段信息如下: 为了国际化考虑 ...
- 导入一些常用命令比如(rz),关闭防火墙外面可以访问
yum -y install lrzsz-----------导入常用命令 我在虚拟机上面启动了一个项目 这个原因是防火墙造成的,关闭防火墙 iptables -L 查看下 service ipt ...
- Android笔记——提升ListView的运行效率
之所以说 ListView 这个控件很难用,就是因为它有很多的细节可以优化,其中运行效率就是很重要的一点.目前我们ListView 的运行效率是很低的,因为在 FruitAdapter 的getVie ...