LinkedHashMap和hashMap和TreeMap的区别
推荐博客:https://www.jianshu.com/p/8f4f58b4b8ab
区别:
- LinkedHashMap是继承于HashMap,是基于HashMap和双向链表来实现的。
- HashMap无序;LinkedHashMap有序,可分为插入顺序和访问顺序两种。如果是访问顺序,那put和get操作已存在的Entry时,都会把Entry移动到双向链表的表尾(其实是先删除再插入)。
- LinkedHashMap存取数据,还是跟HashMap一样使用的Entry[]的方式,双向链表只是为了保证顺序。
- LinkedHashMap是线程不安全的。
LinkedHashMap应用场景
HashMap是无序的,当我们希望有顺序地去存储key-value时,就需要使用LinkedHashMap了。
Map<String, String> hashMap = new HashMap<String, String>();
hashMap.put("name1", "josan1");
hashMap.put("name2", "josan2");
hashMap.put("name3", "josan3");
Set<Entry<String, String>> set = hashMap.entrySet();
Iterator<Entry<String, String>> iterator = set.iterator();
while(iterator.hasNext()) {
Entry entry = iterator.next();
String key = (String) entry.getKey();
String value = (String) entry.getValue();
System.out.println("key:" + key + ",value:" + value);
}
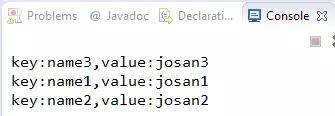
我们是按照xxx1、xxx2、xxx3的顺序插入的,但是输出结果并不是按照顺序的。
同样的数据,我们再试试LinkedHashMap
Map<String, String> linkedHashMap = new LinkedHashMap<>();
linkedHashMap.put("name1", "josan1");
linkedHashMap.put("name2", "josan2");
linkedHashMap.put("name3", "josan3");
Set<Entry<String, String>> set = linkedHashMap.entrySet();
Iterator<Entry<String, String>> iterator = set.iterator();
while(iterator.hasNext()) {
Entry entry = iterator.next();
String key = (String) entry.getKey();
String value = (String) entry.getValue();
System.out.println("key:" + key + ",value:" + value);
}
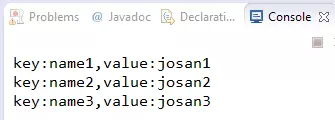
结果可知,LinkedHashMap是有序的,且默认为插入顺序。
插入顺序和访问顺序。
LinkedHashMap默认的构造参数是默认 插入顺序的,就是说你插入的是什么顺序,读出来的就是什么顺序,但是也有访问顺序,就是说你访问了一个key,这个key就跑到了最后面
// 第三个参数用于指定accessOrder值
Map<String, String> linkedHashMap = new LinkedHashMap<>(16, 0.75f, true);
linkedHashMap.put("name1", "josan1");
linkedHashMap.put("name2", "josan2");
linkedHashMap.put("name3", "josan3");
System.out.println("开始时顺序:");
Set<Entry<String, String>> set = linkedHashMap.entrySet();
Iterator<Entry<String, String>> iterator = set.iterator();
while(iterator.hasNext()) {
Entry entry = iterator.next();
String key = (String) entry.getKey();
String value = (String) entry.getValue();
System.out.println("key:" + key + ",value:" + value);
}
System.out.println("通过get方法,导致key为name1对应的Entry到表尾");
linkedHashMap.get("name1");
Set<Entry<String, String>> set2 = linkedHashMap.entrySet();
Iterator<Entry<String, String>> iterator2 = set2.iterator();
while(iterator2.hasNext()) {
Entry entry = iterator2.next();
String key = (String) entry.getKey();
String value = (String) entry.getValue();
System.out.println("key:" + key + ",value:" + value);
}
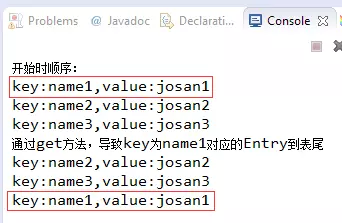
因为调用了get("name1")导致了name1对应的Entry移动到了最后,这里只要知道LinkedHashMap有插入顺序和访问顺序两种就可以
TreeMap的用法(主要是排序)
TreeMap中默认的排序为升序,如果要改变其排序可以自己写一个Comparator
import java.util.Comparator;
import java.util.Iterator;
import java.util.Set;
import java.util.TreeMap; public class Compare {
public static void main(String[] args) {
TreeMap<String,Integer> map = new TreeMap<String,Integer>(new xbComparator());
map.put("key_1", 1);
map.put("key_2", 2);
map.put("key_3", 3);
Set<String> keys = map.keySet();
Iterator<String> iter = keys.iterator();
while(iter.hasNext())
{
String key = iter.next();
System.out.println(" "+key+":"+map.get(key));
}
}
}
class xbComparator implements Comparator
{
public int compare(Object o1,Object o2)
{
String i1=(String)o1;
String i2=(String)o2;
return -i1.compareTo(i2);
}
}

LinkedHashMap和hashMap和TreeMap的区别的更多相关文章
- HashMap与TreeMap的区别?
HashMap与TreeMap的区别? 解答:HashMap通过hashcode对其内容进行快速查找,而TreeMap中所有的元素都保持着某种固定的顺序,如果你需要得到一个有序的结果你就应该使用Tre ...
- java面试题之HashMap和TreeMap的区别
HashMap和TreeMap的区别 相同点: 都是以key和value的形式存储: key不可以重复: 都是线程不安全的: 不同点: HashMap的key可以为空 TreeMap的key值是有序的 ...
- HashMap和TreeMap的区别
HashMap:数组方式存储key/value,线程非安全,允许null作为key和value,key不可以 重复,value允许重复,不保证元素迭代顺序是按照插入时的顺序,key的hash值是先计算 ...
- HashMap与TreeMap的区别
首先描述下什么是Map. 在数组中我们是通过数组的下标来对其内容进行索引的,而在Map中我们是通过对象对对象进行索引的,用来索引的对象叫做key,其对应的对象叫做value.这就是我们平常说的键值对. ...
- Java中HashMap和TreeMap的区别深入理解
首先介绍一下什么是Map.在数组中我们是通过数组下标来对其内容索引的,而在Map中我们通过对象来对对象进行索引,用来索引的对象叫做key,其对应的对象叫做value.这就是我们平时说的键值对. Has ...
- Java中HashMap和TreeMap的区别
什么是Map集合在数组中我们是通过数组下标来对其内容索引的,而在Map中我们通过对象来对对象进行索引,用来索引的对象叫做key,其对应的对象叫做value.这就是我们平时说的键值对. HashMap ...
- Java 中HashTable、HashMap、TreeMap三者区别,以及自定义对象是否相同比较,自定义排序等
/* Map集合:该集合存储键值对.一对一对往里存.而且要保证键的唯一性. Map |--Hashtable:底层是哈希表数据结构,不可以存入null键null值.该集合是线程同步的.效率低.基本已废 ...
- Java中HashMap,LinkedHashMap,TreeMap的区别[转]
原文:http://blog.csdn.net/xiyuan1999/article/details/6198394 java为数据结构中的映射定义了一个接口java.util.Map;它有四个实现类 ...
- HashMap,LinkedHashMap,TreeMap的区别(转)
Map主要用于存储健值对,根据键得到值,因此不允许键重复(重复了覆盖了),但允许值重复.Hashmap 是一个最常用的Map,它根据键的HashCode 值存储数据,根据键可以直接获取它的值,具有很快 ...
随机推荐
- memset()函数的使用
1.概述 memset()函数,称为按字节赋值函数,使用时需要加头文件 #include<cstring>或者#include<string.h>.通常有两个用法: (1)用来 ...
- CF463D Gargari and Permutations dp
给定 $n<=10$ 个 $1$~$n$ 的排列,求这些排列的 $LCS$. 考虑两个排列怎么做:以第一个序列为基准,将第二个序列的元素按照该元素在第一个序列中出现位置重新编号. 然后,求一个 ...
- CODE FESTIVAL 2016 Grand Final 题解
传送门 越学觉得自己越蠢--这场除了\(A\)之外一道都不会-- \(A\) 贪心从左往右扫,能匹配就匹配就好了 //quming #include<bits/stdc++.h> #def ...
- (32)Vue模板语法
模板语法 文本: <span>Message: {{ msg }}</span> v-once 一次性地插值,当数据改变时,插值处的内容不会更新 <span v-once ...
- UOJ272. 【清华集训2016】石家庄的工人阶级队伍比较坚强 [FWT]
UOJ 思路 很容易想到\(O(3^{3m}\log T)\)的暴力大矩乘,显然过不了. 我们分析一下每次转移的性质.题目给的转移方程是填表法,我们试着改成刷表法看看-- 发现好像没啥用. 注意到游戏 ...
- 未公开函数 NtQuerySystemInfoMation 遍历进程信息,获得进程的用户名(如: system,Admin..)
目录 遍历进程用户名 代码例子 遍历进程用户名 代码例子 #include <windows.h> #include <iostream> #include <COMDE ...
- CF1163F Indecisive Taxi Fee(线段树+图论)
做法 这里的修改是暂时的 找到一条最短路径\(E\),需要考虑的是将最短路径上的边增大 每个点考虑与\(1/n\)的最短路径在E上前缀/后缀的位置,设\(L_i,R_i\) 考虑每条边\((u,v)\ ...
- Java GUI小程序--画板
画板效果 (以前写在Csdn上的博文,没去水印,Csdn名字同博客园) 布局类: package gary; import java.awt.Color; import java.awt.even ...
- nginx压力测试和并发预估
一.Nginx并发预估 预估算法:{(?G)*1024-system}/请求大小 (?G):表示内存大小1024:表示内存容量标准进制system:表示系统和服务占用的额外内存和需要预留的内存请求大小 ...
- Coupled和segregated【转载】
转载自:http://blog.sina.com.cn/s/blog_67873f6c0100ltq6.html 问题1: 我看中文帮组里说是'分离'的意思?我绝对翻译不太好,请问有更好的翻译吗? 和 ...