云计算与大数据实验:Hbase shell操作用户表
【实验目的】
1)了解hbase服务
2)学会hbase shell命令操作用户表
【实验原理】
HBase是一个分布式的、面向列的开源数据库,它利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理HBase中的海量数据。本试验hbase提供了一个shell的终端通过操作命令对表user操作。
【实验环境】
本次环境是:centos6.5 + jdk1.7.0_79 + hadoop-2.4.1 + hbase
工具包在/simple/soft目录下
【实验步骤】
一、操作hbase表score
1.1 通过命令start-all.sh启动hadoop,在linux系统中终端执行命令:start-hbase.sh回车启动hbase服务。然后执行连接hbase shell命令:hbase shell进入命令环境,然后执行命令:create ‘user’,’info’,’data’创建一个表user并指定该表的一个列族info和data。如图1所示

图1
1.2 创建user表后需要向user表中插入信息,row key为rk0001,列族info中添加name列标示符,值为zhangsan,执行命令:put 'user', 'rk0001', 'info:name', 'zhangsan'。向user表中插入信息,row key为rk0001,列族info中添加gender列标示符,值为female,执行命令:put 'user', 'rk0001', 'info:gender', 'female'。向user表中插入信息,row key为rk0001,列族info中添加age列标示符,值为20。执行命令:put 'user', 'rk0001', 'info:age', 20。如图2所示
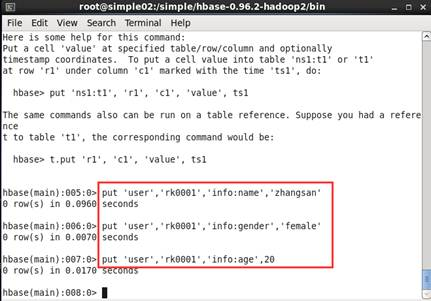
图2
1.3 创建hbase表user之后, 向user表中插入信息,row key为rk0001,列族data中添加pic列标示符,值为picture,执行命令:put 'user', 'rk0001', 'data:pic', 'picture'。如图3所示
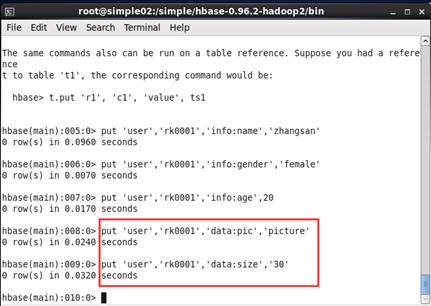
图3
1.4 查看user表中相关数据。获取user表中row key为rk0001的所有信息,执行命令:get 'user', 'rk0001'。获取user表中row key为rk0001,info列族的所有信息,执行命令:get 'user', 'rk0001', 'info'。获取user表中row key为rk0001,info列族的name、age列标示符的信息,执行命令:get 'user', 'rk0001', 'info:name', 'info:age'。如图4所示

图4
1.5 获取user表中row key为rk0001,info、data列族的信息,可以执行如下各命令实现
get 'user', 'rk0001', 'info', 'data'
get 'user', 'rk0001', {COLUMN => ['info', 'data']}
get 'user', 'rk0001', {COLUMN => ['info:name', 'data:pic']}。如图5所示
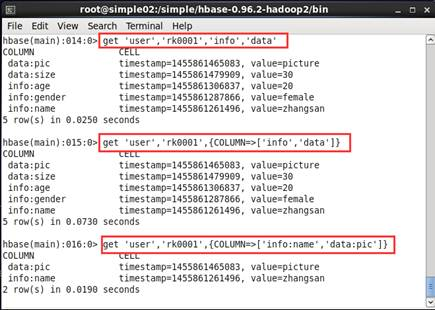
图5
1.6查看某一行指定列族的列单元中的某个元素。
获取user表中row key为rk0001,列族为info,5个最新的版本信息
get 'user', 'rk0001', {COLUMN => 'info', VERSIONS => 2}
get 'user', 'rk0001', {COLUMN => 'info:name', VERSIONS => 5}。如图6所示

图6
云计算与大数据实验:Hbase shell操作用户表的更多相关文章
- 云计算与大数据实验:Hbase shell终端操作之数据操作一
[实验目的] 1)学会向表中添加记录 2)学会添加记录时动态添加列 3)学会查看一条记录 4)学会查看表中的记录总数 5)学会删除记录 [实验原理] Hbase shell作为Hbase数据的客户端, ...
- 云计算与大数据实验:Hbase shell基本命令操作
[实验目的] 1)了解hbase服务 2)学会启动和停止服务 3)学会进入hbase shell环境 [实验原理] HBase是一个分布式的.面向列的开源数据库,它利用Hadoop HDFS作为其文件 ...
- 云计算与大数据实验:Hbase shell操作成绩表
[实验目的] 1)了解hbase服务 2)学会hbase shell命令操作成绩表 [实验原理] HBase是一个分布式的.面向列的开源数据库,它利用Hadoop HDFS作为其文件存储系统,利用Ha ...
- 大数据Hadoop——HDFS Shell操作
一.查询目录下的文件 1.查询根目录下的文件 Hadoop fs -ls / 2.查询文件夹下的文件 Hadoop fs -ls /input 二.创建文件夹 hadoop fs -mkdir /文件 ...
- 大数据技术之_11_HBase学习_01_HBase 简介+HBase 安装+HBase Shell 操作+HBase 数据结构+HBase 原理
第1章 HBase 简介1.1 什么是 HBase1.2 HBase 特点1.3 HBase 架构1.3 HBase 中的角色1.3.1 HMaster1.3.2 RegionServer1.3.3 ...
- 云计算分布式大数据Hadoop实战高手之路第八讲Hadoop图文训练课程:Hadoop文件系统的操作实战
本讲通过实验的方式讲解Hadoop文件系统的操作. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发布云 ...
- HBase Shell操作
Hbase 是一个分布式的.面向列的开源数据库,其实现是建立在google 的bigTable 理论之上,并基于hadoop HDFS文件系统. Hbase不同于一般的关系型数据库(RDBMS ...
- 云计算分布式大数据Hadoop实战高手之路第七讲Hadoop图文训练课程:通过HDFS的心跳来测试replication具体的工作机制和流程
这一讲主要深入使用HDFS命令行工具操作Hadoop分布式集群,主要是通过实验的配置hdfs-site.xml文件的心跳来测试replication具体的工作和流程. 通过HDFS的心跳来测试repl ...
- 一站式Hadoop&Spark云计算分布式大数据和Android&HTML5移动互联网解决方案课程(Hadoop、Spark、Android、HTML5)V2的第一门课程
Hadoop是云计算的事实标准软件框架,是云计算理念.机制和商业化的具体实现,是整个云计算技术学习中公认的核心和最具有价值内容. 如何从企业级开发实战的角度开始,在实际企业级动手操作中深入浅出并循序渐 ...
随机推荐
- springMVC返回json数据乱码问
在springMVC controller中返回json数据出现乱码问题,因为没有进行编码,只需要简单的注解就可以了 在@RequestMapping()中加入produces="text/ ...
- 使用Cloud Toolkit部署SpringBoot项目到服务器
由于我们经常发布项目到测试服,在测试服上调试一些本地无法调试的东西,所以出现了各种打包,然后上传.启动,时间都耗费在这无聊的事情上面了,偶然在网上看到IntelliJ IDEA有 Cloud Tool ...
- MyCat不支持毫秒 bug fix
问题描述:mysql jdbc的驱动(mysql-connector-java-5.1.34.jar)设置的服务器的版本号最低是5.6.4才不会截取时间毫秒,但是现在取的是mycat 的版本号 5.5 ...
- 百度SMS发送短信C#
/// <summary> /// 百度接口签名帮助类 /// </summary> public class BaiduApiHelper { #region 构造函数 // ...
- vue网页添加水印
水印添加方式:1.新建 waterMark.js 内容如下 let watermarkOption = {} let setWatermarkContent = (content) => { l ...
- 【javascript】日期转字符串
function dateFormat(fmt, date) { var ret; var tf = function(str, len){ if(str.length < len) { for ...
- ThinkPHP3开发模式,控制器操作,配置文件,框架语法
ThinkPHP的开发模式 tp框架有两种使用模式:开发模式(调试模式),一种是生产模式(运行模式) define('APP_DEBUG', true); //调试模式 define('APP_DE ...
- elasticsearch 常见查询及聚合的JAVA API
ES 常见查询 (1)根据ID 进行单个查询 GetResponse response = client.prepareGet("accounts", "person&q ...
- Anaconda的pip加速下载命令
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
- Linux查看CPU信息计算CPU核数量
1. 物理CPU的个数: cat /proc/cpuinfo | grep "physical id" | sort | uniq | wc -l 2. 每个物理CPU的核心数量: ...