大数据Hadoop——HDFS Shell操作
一.查询目录下的文件
1.查询根目录下的文件
Hadoop fs -ls /

2.查询文件夹下的文件
Hadoop fs -ls /input

二.创建文件夹
hadoop fs -mkdir /文件名称

三. 上传本地文件到HDFS中
hadoop fs -put 文件名称 文件名称 /上传位置/

四.删除文件
hadoop fs -rm /文件名称

五.删除文件夹
hadoop fs -rm -r 文件夹名称

六.从HDFS中复制文件到本地
hadoop fs -get 文件名称

七.查询文件内容
hadoop fs -cat 文件名称

八.移动HDFS中的文件
hadoop fs -mv 文件位置以及要要移动的文件 移动后的位置

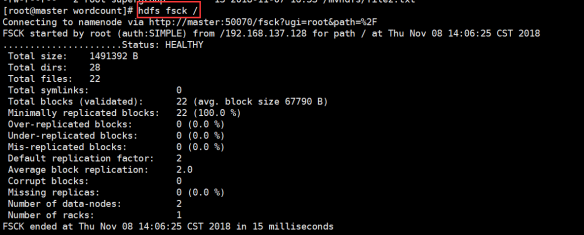
九.检查文件系统健康情况
hdfs fsck /

十.复制HDFS中的文件
hadoop fs -cp 要复制的文件位置以及文件 复制后的位置

十一.显示目录文件大小
hadoop fs -du 文件名称

如果是目录,则显示总大小

十二.清空回收站 (看不到结果)
hadoop fs -expunge

其他的命令:
hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] [-x] <path> ...]
[-expunge]
[-find <path> ... <expression> ...]
[-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] [-skip-empty-file] <src> <localdst>]
[-help [cmd ...]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
大数据Hadoop——HDFS Shell操作的更多相关文章
- 我要进大厂之大数据Hadoop HDFS知识点(1)
01 我们一起学大数据 老刘今天开始了大数据Hadoop知识点的复习,Hadoop包含三个模块,这次先分享出Hadoop中的HDFS模块的基础知识点,也算是对今天复习的内容进行一次总结,希望能够给想学 ...
- 我要进大厂之大数据Hadoop HDFS知识点(2)
01 我们一起学大数据 老刘继续分享出Hadoop中的HDFS模块的一些高级知识点,也算是对今天复习的HDFS内容进行一次总结,希望能够给想学大数据的同学一点帮助,也希望能够得到大佬们的批评和指点! ...
- 大数据 - hadoop - HDFS+Zookeeper实现高可用
高可用(Hign Availability,HA) 一.概念 作用:用于解决负载均衡和故障转移(Failover)问题. 问题描述:一个NameNode挂掉,如何启动另一个NameNode.怎样让两个 ...
- 大数据学习——hdfs客户端操作
package cn.itcast.hdfs; import org.apache.commons.io.IOUtils; import org.apache.hadoop.conf.Configur ...
- 云计算分布式大数据Hadoop实战高手之路第七讲Hadoop图文训练课程:通过HDFS的心跳来测试replication具体的工作机制和流程
这一讲主要深入使用HDFS命令行工具操作Hadoop分布式集群,主要是通过实验的配置hdfs-site.xml文件的心跳来测试replication具体的工作和流程. 通过HDFS的心跳来测试repl ...
- 云计算分布式大数据Hadoop实战高手之路第八讲Hadoop图文训练课程:Hadoop文件系统的操作实战
本讲通过实验的方式讲解Hadoop文件系统的操作. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发布云 ...
- 成都大数据Hadoop与Spark技术培训班
成都大数据Hadoop与Spark技术培训班 中国信息化培训中心特推出了大数据技术架构及应用实战课程培训班,通过专业的大数据Hadoop与Spark技术架构体系与业界真实案例来全面提升大数据工程师 ...
- 大数据Hadoop学习之搭建hadoop平台(2.2)
关于大数据,一看就懂,一懂就懵. 一.概述 本文介绍如何搭建hadoop分布式集群环境,前面文章已经介绍了如何搭建hadoop单机环境和伪分布式环境,如需要,请参看:大数据Hadoop学习之搭建had ...
- 王家林的“云计算分布式大数据Hadoop实战高手之路---从零开始”的第十一讲Hadoop图文训练课程:MapReduce的原理机制和流程图剖析
这一讲我们主要剖析MapReduce的原理机制和流程. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发 ...
随机推荐
- 【Solution】MySQL 5.8 this is incompatible with sql_mode=only_full_group_by
[42000][1055] Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated colu ...
- HRY and codefire
传送门: 设 dp[i][j]为第一个号i等级,第二个号j等级的期望值 a[i]存每个等级上分的概率 dp[i][j]=a[i]*dp[i+1][j]+(1-a[i])*dp[j][i]+1 dp[j ...
- .NET Core 事件总线,分布式事务解决方案:CAP 基于Kafka
背景 相信前面几篇关于微服务的文章也介绍了那么多了,在构建微服务的过程中确实需要这么一个东西,即便不是在构建微服务,那么在构建分布式应用的过程中也会遇到分布式事务的问题,那么 CAP 就是在这样的背景 ...
- Sublime 个人常用快捷键
Sublime 个人常用快捷键 Hot Key Alt + F3 选中文本所以有相同项;同多次Ctrl + D Ctrl + L 选中整行,继续按可继续选 Ctrl + Shift + M 选择括号内 ...
- PHP----------支付宝支付的一些注意事项。该博客只适用于20180209之后,的app支付宝支付。
1.签名方式: 2.设置应用公钥.也就是开发者公钥.
- CentOS 7 Sersync+Rsync 实现数据文件实时同步
rsync+inotify-tools与rsync+sersync架构的区别? 1.rsync+inotify-tools inotify只能记录下被监听的目录发生了变化(增,删,改)并没有把具体是哪 ...
- 信用评分卡(A卡/B卡/C卡)的模型简介及开发流程|干货
https://blog.csdn.net/varyall/article/details/81173326 如今在银行.消费金融公司等各种贷款业务机构,普遍使用信用评分,对客户实行打分制,以期对客户 ...
- 2017.11.19 C语言基础及流水灯实现
/* 从右往左*/ #include <reg52.h> sbit ADDR0 = P1^0; sbit ADDR1 = P1^1; sbit ADDR2 = P1^2; sbit ADD ...
- Instrumentation接口详解
Instrumentation接口位于jdk1.6包java.lang.instrument包下,Instrumentation指的是可以独立于应用程序之外的代理程序,可以用来监控和扩展JVM上运行的 ...
- 【转】git示意图