Scala 函数式编程
将函数赋值给变量
// Scala中的函数是一等公民,可以独立定义,独立存在,而且可以直接将函数作为值赋值给变量
// Scala的语法规定,将函数赋值给变量时,必须在函数后面加上空格和下划线
def sayHello(name: String) { println("Hello, " + name) }
val sayHelloFunc = sayHello _
sayHelloFunc("leo")
匿名函数
// Scala中,函数也可以不需要命名,此时函数被称为匿名函数。// 可以直接定义函数之后,将函数赋值给某个变量;也可以将直接定义的匿名函数传入其他函数之中
// Scala定义匿名函数的语法规则就是,(参数名: 参数类型) => 函数体
// 这种匿名函数的语法必须深刻理解和掌握,在spark的中有大量这样的语法,如果没有掌握,是看不懂spark源码的
val sayHelloFunc = (name: String) => println("Hello, " + name)
高阶函数
// Scala中,由于函数是一等公民,因此可以直接将某个函数传入其他函数,作为参数。这个功能是极其强大的,也是Java这种面向对象的编程语言所不具备的。
// 接收其他函数作为参数的函数,也被称作高阶函数(higher-order function)
val sayHelloFunc = (name: String) => println("Hello, " + name)
def greeting(func: (String) => Unit, name: String) { func(name) }
greeting(sayHelloFunc, "leo")
Array(1, 2, 3, 4, 5).map((num: Int) => num * num)
// 高阶函数的另外一个功能是将函数作为返回值
def getGreetingFunc(msg: String) = (name: String) => println(msg + ", " + name)
val greetingFunc = getGreetingFunc("hello")
greetingFunc("leo")
高阶函数的类型推断
// 高阶函数可以自动推断出参数类型,而不需要写明类型;而且对于只有一个参数的函数,还可以省去其小括号;如果仅有的一个参数在右侧的函数体内只使用一次,则还可以将接收参数省略,并且将参数用_来替代
// 诸如3 * _的这种语法,必须掌握!!spark源码中大量使用了这种语法!
def greeting(func: (String) => Unit, name: String) { func(name) }
greeting((name: String) => println("Hello, " + name), "leo")
greeting((name) => println("Hello, " + name), "leo")
greeting(name => println("Hello, " + name), "leo")
def triple(func: (Int) => Int) = { func(3) }
triple(3 * _)
Scala的常用高阶函数
// map: 对传入的每个元素都进行映射,返回一个处理后的元素
Array(1, 2, 3, 4, 5).map(2 * _)
// foreach: 对传入的每个元素都进行处理,但是没有返回值
(1 to 9).map("*" * _).foreach(println _)
// filter: 对传入的每个元素都进行条件判断,如果对元素返回true,则保留该元素,否则过滤掉该元素
(1 to 20).filter(_ % 2 == 0)
和元素2进行处理,然后将结果与元素3处理,再将结果与元素4处理,依次类推,即为reduce;reduce操作必须掌握!spark编程的重点!!!
// 下面这个操作就相当于1 * 2 * 3 * 4 * 5 * 6 * 7 * 8 * 9
(1 to 9).reduceLeft( _ * _)
// sortWith: 对元素进行两两相比,进行排序
Array(3, 2, 5, 4, 10, 1).sortWith(_ < _)
闭包
// 闭包最简洁的解释:函数在变量不处于其有效作用域时,还能够对变量进行访问,即为闭包
def getGreetingFunc(msg: String) = (name: String) => println(msg + ", " + name)
val greetingFuncHello = getGreetingFunc("hello")
val greetingFuncHi = getGreetingFunc("hi")
// 两次调用getGreetingFunc函数,传入不同的msg,并创建不同的函数返回
// 然而,msg只是一个局部变量,却在getGreetingFunc执行完之后,还可以继续存在创建的函数之中;greetingFuncHello("leo"),调用时,值为"hello"的msg被保留在了函数体内部,可以反复的使用
// 这种变量超出了其作用域,还可以使用的情况,即为闭包
// Scala通过为每个函数创建对象来实现闭包,实际上对于getGreetingFunc函数创建的函数,msg是作为函数对象的变量存在的,因此每个函数才可以拥有不同的msg
// Scala编译器会确保上述闭包机制
SAM转换
// 在Java中,不支持直接将函数传入一个方法作为参数,通常来说,唯一的办法就是定义一个实现了某个接口的类的实例对象,该对象只有一个方法;而这些接口都只有单个的抽象方法,也就是single abstract method,简称为SAM
// 由于Scala是可以调用Java的代码的,因此当我们调用Java的某个方法时,可能就不得不创建SAM传递给方法,非常麻烦;但是Scala又是支持直接传递函数的。此时就可以使用Scala提供的,在调用Java方法时,使用的功能,SAM转换,即将SAM转换为Scala函数
// 要使用SAM转换,需要使用Scala提供的特性,隐式转换
import javax.swing._
import java.awt.event._
val button = new JButton("Click")
button.addActionListener(new ActionListener {
override def actionPerformed(event: ActionEvent) {
println("Click Me!!!")
}
})
implicit def getActionListener(actionProcessFunc: (ActionEvent) => Unit) = new ActionListener {
override def actionPerformed(event: ActionEvent) {
actionProcessFunc(event)
}
}
button.addActionListener((event: ActionEvent) => println("Click Me!!!"))
Currying函数
// Curring函数,指的是,将原来接收两个参数的一个函数,转换为两个函数,第一个函数接收原先的第一个参数,然后返回接收原先第二个参数的第二个函数。
// 在函数调用的过程中,就变为了两个函数连续调用的形式
// 在Spark的源码中,也有体现,所以对()()这种形式的Curring函数,必须掌握!
def sum(a: Int, b: Int) = a + b
sum(1, 1)
def sum2(a: Int) = (b: Int) => a + b
sum2(1)(1)
def sum3(a: Int)(b: Int) = a + b
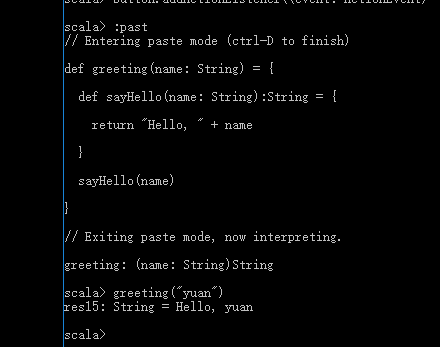
Return
// Scala中,不需要使用return来返回函数的值,函数最后一行语句的值,就是函数的返回值。在Scala中,return用于在匿名函数中返回值给包含匿名函数的带名函数,并作为带名函数的返回值。
// 使用return的匿名函数,是必须给出返回类型的,否则无法通过编译
def greeting(name: String) = {
def sayHello(name: String):String = {
return "Hello, " + name
}
sayHello(name)
}
Scala 函数式编程的更多相关文章
- Scala函数式编程进阶
package com.dtspark.scala.basics /** * 函数式编程进阶: * 1,函数和变量一样作为Scala语言的一等公民,函数可以直接赋值给变量: * 2, 函数更长用的方式 ...
- Scala函数式编程——近半年的痛并快乐着
从9月初啃完那本让人痛不欲生却又欲罢不能的<七周七并发模型>,我差不多销声匿迹了整整4个月.这几个月里,除了忙着讨食,便是继续啃另一本"锯著"--<Scala函数 ...
- Scala实战高手****第5课:零基础实战Scala函数式编程及Spark源码解析
Scala函数式编程 ----------------------------------------------------------------------------------------- ...
- 9、scala函数式编程-集合操作
一.集合操作1 1.Scala的集合体系结构 // Scala中的集合体系主要包括:Iterable.Seq.Set.Map.其中Iterable是所有集合trait的根trai.这个结构与Java的 ...
- Scala函数式编程(三) scala集合和函数
前情提要: scala函数式编程(二) scala基础语法介绍 scala函数式编程(二) scala基础语法介绍 前面已经稍微介绍了scala的常用语法以及面向对象的一些简要知识,这次是补充上一章的 ...
- Scala函数式编程(四)函数式的数据结构 上
这次来说说函数式的数据结构是什么样子的,本章会先用一个list来举例子说明,最后给出一个Tree数据结构的练习,放在公众号里面,练习里面给出了基本的结构,但代码是空缺的需要补上,此外还有预留的test ...
- Scala函数式编程(四)函数式的数据结构 下
前情提要 Scala函数式编程指南(一) 函数式思想介绍 scala函数式编程(二) scala基础语法介绍 Scala函数式编程(三) scala集合和函数 Scala函数式编程(四)函数式的数据结 ...
- scala 函数式编程之集合操作
Scala的集合体系结构 // Scala中的集合体系主要包括:Iterable.Seq.Set.Map.其中Iterable是所有集合trait的根trai.这个结构与Java的集合体系非常相似. ...
- 大数据笔记(二十五)——Scala函数式编程
===================== Scala函数式编程 ======================== 一.Scala中的函数 (*) 函数是Scala中的头等公民,就和数字一样,可以在变 ...
- Scala函数式编程(五) 函数式的错误处理
前情提要 Scala函数式编程指南(一) 函数式思想介绍 scala函数式编程(二) scala基础语法介绍 Scala函数式编程(三) scala集合和函数 Scala函数式编程(四)函数式的数据结 ...
随机推荐
- c# 读数据库二进制流到图片
public Bitmap PictureShow(string connectionString, string opName, string productType) { ...
- 一个很简单的SpringCloud项目,集成Feign、Hystrix
Feign的功能:这是个消费者,根据服务注册在Eureka的ID去找到该服务,并调用接口Hystrix的功能:熔断器,假如A服务需要调用B服务的/cities接口获取数据,那就在A服务的control ...
- dos2unix的使用
由于在DOS(windows系统)下,文本文件的换行符为CRLF,而在Linux下换行符为LF,使用git进行代码管理时,git会自动进行CRLF和LF之间的转换,这个我们不用操心.而有时候,我们需要 ...
- Python字符编码和转码
一:Python2 python2默认编码格式是ascii码,解释器解释代码时会将代码以及代码中的字符串等转换成ascii码再执行.这样会导致字符串输出或传输时,与当前环境编码格式不同的话会显示乱码. ...
- Linux的DNS实现负载均衡及泛域名部署
DNS负载均衡技术的实现原理是在DNS服务器中为同一个主机名配置多个IP地址,在应答DNS查询时,DNS服务器对每个查询将以DNS文件中主机记录的IP地址按顺序返回不同的解析结果,将客户端的访问引导到 ...
- Memcache未授权访问漏洞简单修复方法
漏洞描述: memcache是一套常用的key-value缓存系统,由于它本身没有权限控制模块,所以开放在外网的memcache服务很容易被攻击者扫描发现,通过命令交互可直接读取memcache中的敏 ...
- nginx 请求限制
1.nginx 请求限制 1.连接频率限制 - limit_conn_module 2.请求频率限制 - limit_req_module 连接限制的语法 请求限制的语法 limit_conn_zon ...
- NiFi使用总结 一 hive到hive的PutHiveStreaming processor和SelectHiveQL
我说实话,NiFi的坑真的挺多的... 1.PutHiveStreaming processor的使用 具体配置可参考:https://community.hortonworks.com/articl ...
- Helm 安装Kafka
helm镜像库配置 helm repo add stable http://mirror.azure.cn/kubernetes/charts helm repo add incubator http ...
- BEST FREE UNITY ASSETS – OVER 200 CURATED QUALITY ASSETS
http://www.procedural-worlds.com/blog/best-free-unity-assets-categorised-mega-list/ BEST FREE UNITY ...