Java学习-055-Jsoup爬虫通过设置获取响应数据大小的最大值,解决因默认获取 1MB 响应数据导致的无法获取全部的响应数据内容问题
在日常工作中,通常会遇到获取各种网络数据使用的情况,Java中可使用Jsoup(Python中可使用 BeatifulSoup)进行数据的获取及处理。
今天有朋友问,在使用 Jsoup 进行请求数据时,获取的响应结果信息一直不完整,然后帮忙解决了一下。下面把解决的方法记录下,方便后续遇到的亲,免受搜索却解决不了之苦。
解决步骤:
1、脚本多次执行时,未发生逻辑异常;
2、执行过程中,因接口响应时长原因,有超时响应,默认超时时间为 30 秒;
更改超时时间为 100秒,如下所示:
Jsoup.connect(url).timeout(100000)
3、调试爬虫脚本,打印查看每次请求的响应数据大小,发现始终为 1MB;
Jsoup.connect(url).timeout(60000).execute().bodyAsBytes().length / 1024 / 1024
4、查看 Jsoup 的源码,发现 Jsoup 通过 HttpConnction.Request.maxBodySizeBytes 设置获取的响应数据大小,默认为 1MB,如下所示: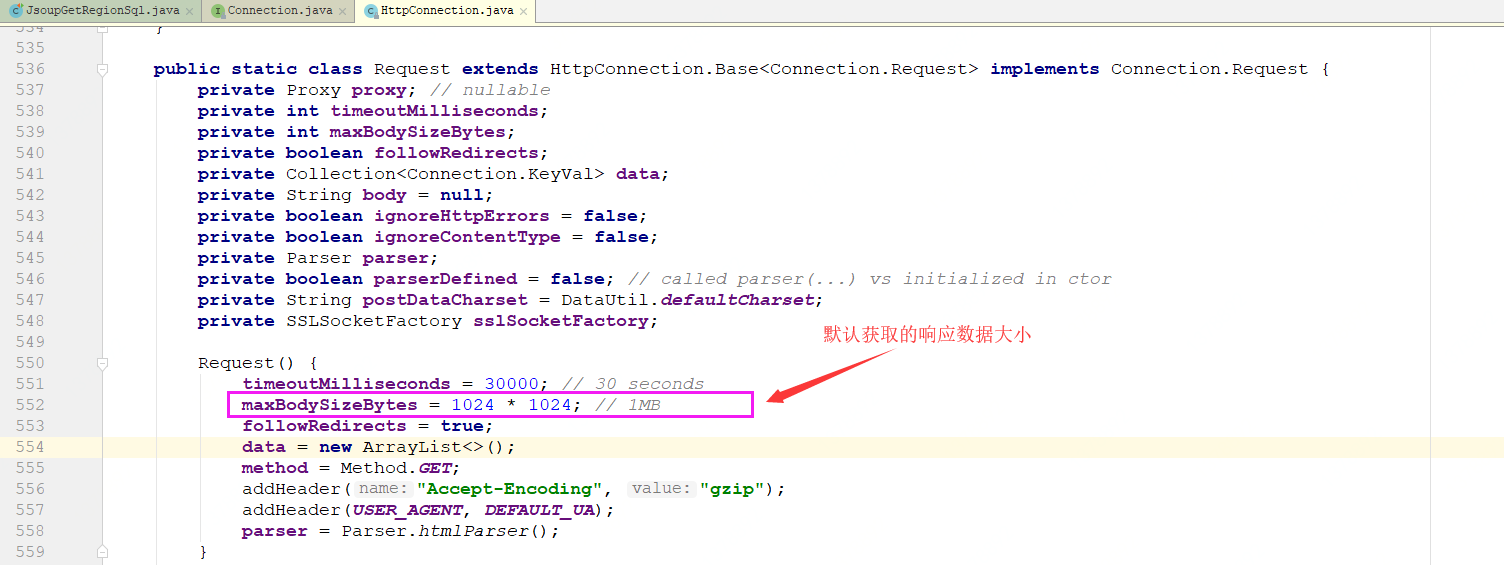
通过 Connection.maxBodySize(大小) 设置获取的响应数据大小,如下所示:

修改后,再次执行脚本,可成功获取所有的响应内容信息。
Java学习-055-Jsoup爬虫通过设置获取响应数据大小的最大值,解决因默认获取 1MB 响应数据导致的无法获取全部的响应数据内容问题的更多相关文章
- 从.Net到Java学习第七篇——SpringBoot Redis 缓存穿透
从.Net到Java学习系列目录 场景描述:我们在项目中使用缓存通常都是先检查缓存中是否存在,如果存在直接返回缓存内容,如果不存在就直接查询数据库然后再缓存查询结果返回.这个时候如果我们查询的某一个数 ...
- (java)Jsoup爬虫学习--获取智联招聘(老网站)的全国java职位信息,爬取10页
Jsoup爬虫学习--获取智联招聘(老网站)的全国java职位信息,爬取10页,输出 职位名称*****公司名称*****职位月薪*****工作地点*****发布日期 import java.io.I ...
- (java)Jsoup爬虫学习--获取网页所有的图片,链接和其他信息,并检查url和文本信息
Jsoup爬虫学习--获取网页所有的图片,链接和其他信息,并检查url和文本信息 此例将页面图片和url全部输出,重点不太明确,可根据自己的需要输出和截取: import org.jsoup.Jsou ...
- 【Java】Jsoup爬虫,一个简单获取京东商品信息的小Demo
简单记录 - Jsoup爬虫入门实战 数据问题?数据库获取,消息队列中获取中,都可以成为数据源,爬虫! 爬取数据:(获取请求返回的页面信息,筛选出我们想要的数据就可以了!) 我们经常需要分析HTML网 ...
- Java学习-058-Jsoup爬虫获取中国所有的三级行政区划数据(三),处理二级编码缺失
通过查看数据可知,直辖市或者某些三级行政区域没有对应的二级区域,为方便后续的地址使用,可自定义缺失的二级地址. 如下示例自定义的二级行政区域的名称为一级区域的名称,对应的源码如下所示: 将此段源码添加 ...
- Java学习-056-Jsoup爬虫获取中国所有的三级行政区划数据(一)
在涉及地址服务时,经常需要用到地址信息的获取,而行政区划可能不定期的发生变化,所以我们需要获取最新的行政区划信息.因行政区划数据量较大,Java中可以使用Jsoup进行数据的获取.处理. 大家经常用到 ...
- Java 实现 HttpClients+jsoup,Jsoup,htmlunit,Headless Chrome 爬虫抓取数据
最近整理一下手头上搞过的一些爬虫,有HttpClients+jsoup,Jsoup,htmlunit,HeadlessChrome 一,HttpClients+jsoup,这是第一代比较low,很快就 ...
- JAVA之旅(三十四)——自定义服务端,URLConnection,正则表达式特点,匹配,切割,替换,获取,网页爬虫
JAVA之旅(三十四)--自定义服务端,URLConnection,正则表达式特点,匹配,切割,替换,获取,网页爬虫 我们接着来说网络编程,TCP 一.自定义服务端 我们直接写一个服务端,让本机去连接 ...
- golang学习笔记17 爬虫技术路线图,python,java,nodejs,go语言,scrapy主流框架介绍
golang学习笔记17 爬虫技术路线图,python,java,nodejs,go语言,scrapy主流框架介绍 go语言爬虫框架:gocolly/colly,goquery,colly,chrom ...
随机推荐
- 浅谈布隆过滤器Bloom Filter
先从一道面试题开始: 给A,B两个文件,各存放50亿条URL,每条URL占用64字节,内存限制是4G,让你找出A,B文件共同的URL. 这个问题的本质在于判断一个元素是否在一个集合中.哈希表以O(1) ...
- 大数据:Hadoop(JDK安装、HDFS伪分布式环境搭建、HDFS 的shell操作)
所有的内容都来源与 Hadoop 官方文档 一.Hadoop 伪分布式安装步骤 1)JDK安装 解压:tar -zxvf jdk-7u79-linux-x64.tar.gz -C ~/app 添加到系 ...
- 《linux就该这么学》课堂笔记04 常用命令cat、mor...tar、find
本节命令汇总 命令 说明 格式 常用参数 实例 备注 cat 查看纯文本文件(内容较少) cat [选项] 文件名称 -n 显示行号 cat -n install-setup-ks.cfg 查看ins ...
- 内核中dump_stack的实现原理(2) —— symbol
环境 Linux-4.14 Aarch64 正文 在前面的分析中调用print_symbol("PC is at %s\n", instruction_pointer(regs ...
- 将linux和uboot集成到Android编译框架中
span::selection, .CodeMirror-line > span > span::selection { background: #d7d4f0; }.CodeMirror ...
- input事件在进行模糊搜索时,用到的即时监测input的值变化的方法(即时搜索的input和propertychange方法)
做搜索功能的时候,经常遇到输入框检查的需求,最常见的是即时搜索,今天好好小结一下. 即时搜索的方案: (1)change事件 触发事件必须满足两个条件: a)当前对象属性改变,并且是由键盘或鼠标 ...
- Beyond Compare设置自定义过滤
Beyond Compare是一款优秀的专业级文件比较软件,利用它可以快速比较出文件之间的差异,以便于修改.整合.其中较强大的功能之一就是文件夹比较,面对海量的子文件夹以及文件,Beyond Comp ...
- Caused by: javax.persistence.TransactionRequiredException: Executing an update/delete query
org.springframework.dao.InvalidDataAccessApiUsageException: Executing an update/delete query; nested ...
- reflow和repaint理解总结
repaint就是重绘,reflow就是回流 严重性: 在性能优先的前提下,reflow的性能消耗要比repaint的大. 体现: repaint是某个dom元素进行重绘,reflow是整个页面进行重 ...
- 为什么 JVM 不用 JIT 全程编译?
考虑到跨平台,所以无法使用AOT: 考虑到执行效率,所以无法全部使用JIT: 编译技术大约分为两种,一种AOT,只线下(offline)就将源代码编译成目标机器码,这是普遍用在系统程序语言中:另一种是 ...