C#使用CSS选择器抓取页面内容
最近在查wpf绘图资料时,偶然看到Python使用CSS选择器抓取网页的功能。觉得很强,这里用C#也实现一下。
先介绍一下CSS选择器
在 CSS 中,选择器是一种模式,用于选择需要添加样式的元素。
|
选择器 |
例子 |
例子描述 |
|
.intro |
选择 class="intro" 的所有元素。 |
|
|
#firstname |
选择 id="firstname" 的所有元素。 |
|
|
* |
选择所有元素。 |
|
|
p |
选择所有 <p> 元素。 |
|
|
div,p |
选择所有 <div> 元素和所有 <p> 元素。 |
|
|
div p |
选择 <div> 元素内部的所有 <p> 元素。 |
|
|
div>p |
选择父元素为 <div> 元素的所有 <p> 元素。 |
|
|
div+p |
选择紧接在 <div> 元素之后的所有 <p> 元素。 |
|
|
[target] |
选择带有 target 属性所有元素。 |
|
|
[target=_blank] |
选择 target="_blank" 的所有元素。 |
|
|
[title~=flower] |
选择 title 属性包含单词 "flower" 的所有元素。 |
|
|
[lang|=en] |
选择 lang 属性值以 "en" 开头的所有元素。 |
|
|
a:link |
选择所有未被访问的链接。 |
|
|
a:visited |
选择所有已被访问的链接。 |
|
|
a:active |
选择活动链接。 |
|
|
a:hover |
选择鼠标指针位于其上的链接。 |
|
|
input:focus |
选择获得焦点的 input 元素。 |
|
|
p:first-letter |
选择每个 <p> 元素的首字母。 |
|
|
p:first-line |
选择每个 <p> 元素的首行。 |
|
|
p:first-child |
选择属于父元素的第一个子元素的每个 <p> 元素。 |
|
|
p:before |
在每个 <p> 元素的内容之前插入内容。 |
|
|
p:after |
在每个 <p> 元素的内容之后插入内容。 |
|
|
p:lang(it) |
选择带有以 "it" 开头的 lang 属性值的每个 <p> 元素。 |
|
|
p~ul |
选择前面有 <p> 元素的每个 <ul> 元素。 |
|
|
a[src^="https"] |
选择其 src 属性值以 "https" 开头的每个 <a> 元素。 |
|
|
a[src$=".pdf"] |
选择其 src 属性以 ".pdf" 结尾的所有 <a> 元素。 |
|
|
a[src*="abc"] |
选择其 src 属性中包含 "abc" 子串的每个 <a> 元素。 |
|
|
p:first-of-type |
选择属于其父元素的首个 <p> 元素的每个 <p> 元素。 |
|
|
p:last-of-type |
选择属于其父元素的最后 <p> 元素的每个 <p> 元素。 |
|
|
p:only-of-type |
选择属于其父元素唯一的 <p> 元素的每个 <p> 元素。 |
|
|
p:only-child |
选择属于其父元素的唯一子元素的每个 <p> 元素。 |
|
|
p:nth-child(2) |
选择属于其父元素的第二个子元素的每个 <p> 元素。 |
|
|
p:nth-last-child(2) |
同上,从最后一个子元素开始计数。 |
|
|
p:nth-of-type(2) |
选择属于其父元素第二个 <p> 元素的每个 <p> 元素。 |
|
|
p:nth-last-of-type(2) |
同上,但是从最后一个子元素开始计数。 |
|
|
p:last-child |
选择属于其父元素最后一个子元素每个 <p> 元素。 |
|
|
:root |
选择文档的根元素。 |
|
|
p:empty |
选择没有子元素的每个 <p> 元素(包括文本节点)。 |
|
|
#news:target |
选择当前活动的 #news 元素。 |
|
|
input:enabled |
选择每个启用的 <input> 元素。 |
|
|
input:disabled |
选择每个禁用的 <input> 元素 |
|
|
input:checked |
选择每个被选中的 <input> 元素。 |
|
|
:not(p) |
选择非 <p> 元素的每个元素。 |
|
|
::selection |
选择被用户选取的元素部分。 |
C#自带的类库里不支持这个操作,所以需要用到三方库。这里用的是AngleSharp,使用Nuget搜索这个包就可以
这里以抓取https://technet-info.com/Main.aspx为例
页面源码如下:
<html xmlns="http://www.w3.org/1999/xhtml">
<head><meta http-equiv="Content-Type" content="text/html; charset=utf-8" /><meta name="description" content="Wandering the number of windows, stayed in the number of hotels, will feel that separation is not wronged, the feelings are used to browse or used to collect, so that the day had a memorable day" /><title>
Welcome To Technet-Info : Personal Gallery
</title><link rel="shortcut icon" type="image/x-icon" href="technet.ico" media="screen" /><link rel="stylesheet" href="Css/MainCss.css" /><link rel="stylesheet" href="Css/screen.css" />
<style>
#footer{
display: flex;
justify-content: center;
align-items: center;
position: fixed;
bottom: 0;
left: 0;
width: 100%;
}
</style>
<script type="text/javascript" src="js/jquery.js"></script>
<script type="text/javascript" src="js/easySlider1.7.js"></script>
<script type="text/javascript">
$(document).ready(function () {
$("#slider").easySlider({
auto: true,
pause:3000,
continuous: true,
numeric: true
});
});
</script>
</head>
<body>
<form method="post" action="./Main.aspx" id="form1">
<div class="aspNetHidden">
<input type="hidden" name="__VIEWSTATE" id="__VIEWSTATE" value="/wEPDwUKLTQyNjI2MTkwNmRkt331eyucv2SBluj0E2d+0haGV4exFHWtGQkZhNBnpHE=" />
</div> <div class="aspNetHidden"> <input type="hidden" name="__VIEWSTATEGENERATOR" id="__VIEWSTATEGENERATOR" value="202EA31B" />
</div>
<div id="main">
<div id="header">
<div class="musicarea"> <iframe frameborder="no" border="0" marginwidth="0" marginheight="0" width=150 height=52 src="http://music.163.com/outchain/player?type=0&id=516657278&auto=1&height=32"></iframe>
</div>
<div class="content"> <div class="logo"> <div class="logo_img">
<div class="logo_img"></div>
</div> <div class="logo_txt">
<div style="height: 50px;">
<p></p>
</div>
<div style="height: 50px;">
<p>我的freetime</p>
</div>
</div>
</div> <div class="menu"> </div>
</div> <div id="content"> </div> <div id="cards"> </div>
<div id="pin"> </div> </div> <div id="footer">
<div id="copyright">
<p style="margin: 3px">
<a href="http://www.miitbeian.gov.cn/">湘ICP备17816343号</a>
<span>|</span>
<span>Copyright © 2016, www.technet-info.com, All rights reserved.</span>
</p>
<p><a href="mailto:zhaotianff@163.com">Email:zhaotianff@163.com</a></p>
</div>
</div>
</div>
</form>
</body>
</html>
新建一个控制台工程,引用AngleSharp(由于在Main函数中使用了Async,所以需要Visual Studio 2017+,如果低于这个版本,可以把Main函数中的内容封装成一个函数执行,然后移除Main中的Async)
初始化
var config = Configuration.Default;
var context = BrowsingContext.New(config);
var source = Properties.Resources.HTML;
var document = await context.OpenAsync(req => req.Content(source));
建立CSS选择器并执行查询 ,查找class = content的节点
var cssSelector = ".content";
var cell = document.QuerySelector(cssSelector);
输出InnerHtml可以看到如下结果
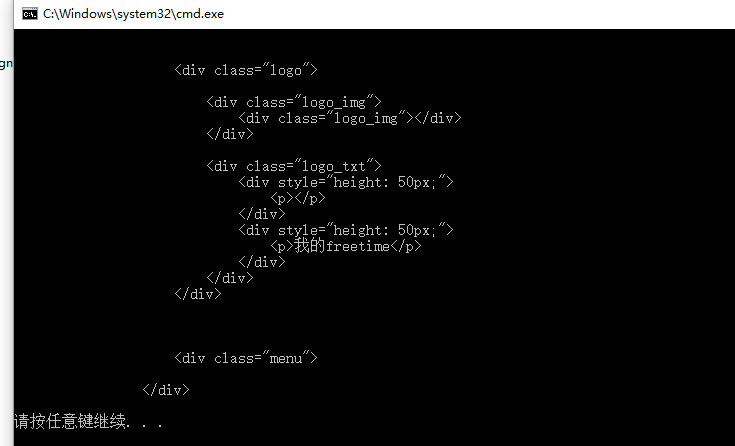
基本上到这里就可以愉快的使用CSS选择器进行元素选取了。如果需要上面表格中全部CSS选择器的示例,可以下载示例代码
这里还有一个实用功能,就是浏览器开发者工具提供了复制CSS选择器的功能

示例代码待上传。。。。
最后:
如果需要进行XPath查询,可以参考
https://www.cnblogs.com/zhaotianff/p/11319871.html
这篇文章。虽然示例是基于XML的,但HTML基本上也一样。同样也可以使用上面的浏览器工具复制元素的XPath。
有兴趣了解C#爬虫相关知识的小伙伴,可以参考
https://github.com/zhaotianff/CSharpCrawler
再附上一个详细介绍CSS选择器的链接
https://developer.mozilla.org/zh-CN/docs/Web/CSS/Attribute_selectors
≧◔◡◔≦
C#使用CSS选择器抓取页面内容的更多相关文章
- 【java】抓取页面内容,提取链接(此方法可以http get无需账号密码的请求)
package 网络编程; import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.FileOutpu ...
- 如何使用angularjs实现抓取页面内容
<html ng-app="myApp"> <head> <title>angularjs-ajax</title> <scr ...
- nodejs抓取页面内容,并分析有无某些内容的js文件
nodejs获取网页内容绑定data事件,获取到的数据会分几次相应,如果想全局内容匹配,需要等待请求结束,在end结束事件里把累积起来的全局数据进行操作! 举个例子,比如要在页面中找有没有www.ba ...
- PHP cURL库函数抓取页面内容
目录 1 为什么要用cURL? 2 启用cURL 3 基本结构 4 检查错误 5 获取信息 6 基于浏览器的重定向 7 用POST方法发送数据 8 文件上传 9 cURL批处理(multi cURL) ...
- 如何利用CSS选择器抓取京东网商品信息
前几天小编分别利用Python正则表达式.BeautifulSoup.Xpath分别爬取了京东网商品信息,今天小编利用CSS选择器来为大家展示一下如何实现京东商品信息的精准匹配~~ CSS选择器 目前 ...
- 基于puppeteer模拟登录抓取页面
关于热图 在网站分析行业中,网站热图能够很好的反应用户在网站的操作行为,具体分析用户的喜好,对网站进行针对性的优化,一个热图的例子(来源于ptengine) 上图中能很清晰的看到用户关注点在那,我们不 ...
- Java爬虫系列二:使用HttpClient抓取页面HTML
爬虫要想爬取需要的信息,首先第一步就要抓取到页面html内容,然后对html进行分析,获取想要的内容.上一篇随笔<Java爬虫系列一:写在开始前>中提到了HttpClient可以抓取页面内 ...
- 搭建谷歌浏览器无头模式抓取页面服务,laravel->php->python->docker !!!
背景: 公司管理系统需要获取企业微信页面的配置参数如企业名.logo.人数等信息并操作,来隐藏相关敏感信息并自定义简化企业号配置流程 第一版已经实现了扫码登录获取cookie,使用该cookie就能获 ...
- 用PHP抓取页面并分析
在做抓取前,记得把php.ini中的max_execution_time设置的大点,不然会报错的.
随机推荐
- MySQL避免插入重复记录:唯一性约束
mysql在存在主键冲突或者唯一键冲突的情况下,根据插入策略不同,一般有以下三种避免方法.1.insert ignore2.replace into3.insert on duplicate ke ...
- Fluent Meshing分离边界层网格
源视频链接: https://pan.baidu.com/s/1SYB7UdRuXOGYXYwmxKADdw 提取码: h7qj
- [Gamma阶段]第十次Scrum Meeting
Scrum Meeting博客目录 [Gamma阶段]第十次Scrum Meeting 基本信息 名称 时间 地点 时长 第十次Scrum Meeting 19/06/06 大运村寝室6楼 30min ...
- centos 7 U盘 uefi 模式装机
公司买了一台新的dell机器,因为装的是window ,所以想给改成Centos 的做服务器,但是问题来了,一上来装好,就完全进入不了引导系统,换了ubuntu 有一次意外装上了,但一直是什么原因,然 ...
- 在 Alpine Linux 中安装 bash shell
如何在我的 Alpine Linux LXD(Linux容器)虚拟机(VM)中安装 bash shell? Alpine Linux 自带 BusyBox 工具.它被评为“嵌入式 Linux 的瑞士军 ...
- NPU TPU
https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
- android ------ 高版本的 Tablayout 下划线宽度
前面呢,有写过TabLayout的博客,最近开发用到了高本版遇到一些问题,来总结一下 Android--------TabLayout实现新闻客户端顶部导航栏 Android中Tablayout设置下 ...
- Linux创建用户,SFTP只允许访问指定目录
首先创建用户 useradd lus1passwd lus1 我这里配置lus1这个用户目录,为sftp指向目录,即/home/lus1/ vim /etc/ssh/sshd_config //这个记 ...
- vue 专题 vue2.0各大前端移动端ui框架组件展示
Vue 专题 一个数据驱动的组件,为现代化的 Web 界面而生.具有可扩展的数据绑定机制,原生对象即模型,简洁明了的 API 组件化 UI 构建 多个轻量库搭配使用 请访问链接: https://ww ...
- elementui---表格拖动排序的问题
刚刚用elementui的表格,需要用到一个拖动排序的需求,简单弄了下,使用 Sorttable 来做还是挺快的,但是发现一个问题,拖动排序显示不正常. <el-table :data=&quo ...