一次 ElasticSearch 搜索优化
一次 ElasticSearch 搜索优化
1. 环境
ES6.3.2,索引名称 user_v1,5个主分片,每个分片一个副本。分片基本都在11GB左右,GET _cat/shards/user
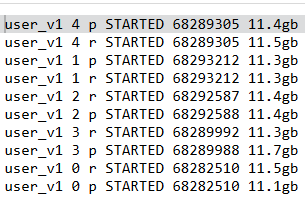
一共有3.4亿文档,主分片总共57GB。
Segment信息:curl -X GET "221.228.105.140:9200/_cat/segments/user_v1?v" >> user_v1_segment
user_v1索引一共有404个段:
cat user_v1_segment | wc -l
404
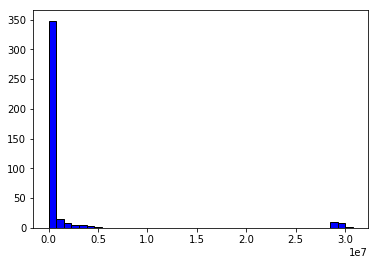
处理一下数据,用Python画个直方图看看效果:
sed -i '1d' file # 删除文件第一行
awk -F ' ' '{print $7}' user_v1_segment >> docs_count # 选取感兴趣的一列(docs.count 列)
with open('doc_count.txt') as f:
data=f.read()
docList = data.splitlines()
docNums = list(map(int,docList))
import matplotlib.pyplot as plt
plt.hist(docNums,bins=40,normed=0,facecolor='blue',edgecolor='black')
大概看一下每个Segment中包含的文档的个数。横坐标是:文档数量,纵坐标是:segment个数。可见:大部分的Segment中只包含了少量的文档(\(0.5*10^7\))
修改refresh_interval为30s,原来默认为1s,这样能在一定程度上减少Segment的数量。然后先force merge将404个Segment减少到200个:
POST /user_v1/_forcemerge?only_expunge_deletes=false&max_num_segments=200&flush=true
但是一看,还是有312个Segment。这个可能与merge的配置有关了。有兴趣的可以了解一下 force merge 过程中这2个参数的意义:
- merge.policy.max_merge_at_once_explicit
- merge.scheduler.max_merge_count
执行profile分析:
1,Collector 时间过长,有些分片耗时长达7.9s。关于Profile 分析,可参考:profile-api
2,采用HanLP 分词插件,Analyzer后得到Term,居然有"空格Term",而这个Term的匹配长达800ms!
来看看原因:
POST /_analyze
{
"analyzer": "hanlp_standard",
"text":"人生 如梦"
}
分词结果是包含了空格的:
{
"tokens": [
{
"token": "人生",
"start_offset": 0,
"end_offset": 2,
"type": "n",
"position": 0
},
{
"token": " ",
"start_offset": 0,
"end_offset": 1,
"type": "w",
"position": 1
},
{
"token": "如",
"start_offset": 0,
"end_offset": 1,
"type": "v",
"position": 2
},
{
"token": "梦",
"start_offset": 0,
"end_offset": 1,
"type": "n",
"position": 3
}
]
}
那实际文档被Analyzer了之后是否存储了空格呢?
于是先定义一个索引,开启term_vector。参考store term-vector
PUT user
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"profile": {
"properties": {
"nick": {
"type": "text",
"analyzer": "hanlp_standard",
"term_vector": "yes",
"fields": {
"raw": {
"type": "keyword"
}
}
}
}
}
}
}
然后PUT一篇文档进去:
PUT user/profile/1
{
"nick":"人生 如梦"
}
查看Term Vector:docs-termvectors
GET /user/profile/1/_termvectors
{
"fields" : ["nick"],
"offsets" : true,
"payloads" : true,
"positions" : true,
"term_statistics" : true,
"field_statistics" : true
}
发现存储的Terms里面有空格。
{
"_index": "user",
"_type": "profile",
"_id": "1",
"_version": 1,
"found": true,
"took": 2,
"term_vectors": {
"nick": {
"field_statistics": {
"sum_doc_freq": 4,
"doc_count": 1,
"sum_ttf": 4
},
"terms": {
" ": {
"doc_freq": 1,
"ttf": 1,
"term_freq": 1
},
"人生": {
"doc_freq": 1,
"ttf": 1,
"term_freq": 1
},
"如": {
"doc_freq": 1,
"ttf": 1,
"term_freq": 1
},
"梦": {
"doc_freq": 1,
"ttf": 1,
"term_freq": 1
}
}
}
}
}
然后再执行profile 查询分析:
GET user/profile/_search?human=true
{
"profile":true,
"query": {
"match": {
"nick": "人生 如梦"
}
}
}
发现Profile里面居然有针对 空格Term 的查询!!!(注意 nick 后面有个空格)
"type": "TermQuery",
"description": "nick: ",
"time": "58.2micros",
"time_in_nanos": 58244,
profile结果如下:
"profile": {
"shards": [
{
"id": "[7MyDkEDrRj2RPHCPoaWveQ][user][0]",
"searches": [
{
"query": [
{
"type": "BooleanQuery",
"description": "nick:人生 nick: nick:如 nick:梦",
"time": "642.9micros",
"time_in_nanos": 642931,
"breakdown": {
"score": 13370,
"build_scorer_count": 2,
"match_count": 0,
"create_weight": 390646,
"next_doc": 18462,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 2,
"score_count": 1,
"build_scorer": 220447,
"advance": 0,
"advance_count": 0
},
"children": [
{
"type": "TermQuery",
"description": "nick:人生",
"time": "206.6micros",
"time_in_nanos": 206624,
"breakdown": {
"score": 942,
"build_scorer_count": 3,
"match_count": 0,
"create_weight": 167545,
"next_doc": 1493,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 2,
"score_count": 1,
"build_scorer": 36637,
"advance": 0,
"advance_count": 0
}
},
{
"type": "TermQuery",
"description": "nick: ",
"time": "58.2micros",
"time_in_nanos": 58244,
"breakdown": {
"score": 918,
"build_scorer_count": 3,
"match_count": 0,
"create_weight": 46130,
"next_doc": 964,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 2,
"score_count": 1,
"build_scorer": 10225,
"advance": 0,
"advance_count": 0
}
},
{
"type": "TermQuery",
"description": "nick:如",
"time": "51.3micros",
"time_in_nanos": 51334,
"breakdown": {
"score": 888,
"build_scorer_count": 3,
"match_count": 0,
"create_weight": 43779,
"next_doc": 1103,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 2,
"score_count": 1,
"build_scorer": 5557,
"advance": 0,
"advance_count": 0
}
},
{
"type": "TermQuery",
"description": "nick:梦",
"time": "59.1micros",
"time_in_nanos": 59108,
"breakdown": {
"score": 3473,
"build_scorer_count": 3,
"match_count": 0,
"create_weight": 49739,
"next_doc": 900,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 2,
"score_count": 1,
"build_scorer": 4989,
"advance": 0,
"advance_count": 0
}
}
]
}
],
"rewrite_time": 182090,
"collector": [
{
"name": "CancellableCollector",
"reason": "search_cancelled",
"time": "25.9micros",
"time_in_nanos": 25906,
"children": [
{
"name": "SimpleTopScoreDocCollector",
"reason": "search_top_hits",
"time": "19micros",
"time_in_nanos": 19075
}
]
}
]
}
],
"aggregations": []
}
]
}
而在实际的生产环境中,空格Term的查询耗时480ms,而一个正常词语("微信")的查询,只有18ms。如下在分片[user_v1][3]上的profile分析结果:
"profile": {
"shards": [
{
"id": "[8eN-6lsLTJ6as39QJhK5MQ][user_v1][3]",
"searches": [
{
"query": [
{
"type": "BooleanQuery",
"description": "nick:微信 nick: nick:黄色",
"time": "888.6ms",
"time_in_nanos": 888636963,
"breakdown": {
"score": 513864260,
"build_scorer_count": 50,
"match_count": 0,
"create_weight": 93345,
"next_doc": 364649642,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 5063173,
"score_count": 4670398,
"build_scorer": 296094,
"advance": 0,
"advance_count": 0
},
"children": [
{
"type": "TermQuery",
"description": "nick:微信",
"time": "18.4ms",
"time_in_nanos": 18480019,
"breakdown": {
"score": 656810,
"build_scorer_count": 62,
"match_count": 0,
"create_weight": 23633,
"next_doc": 17712339,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 7085,
"score_count": 5705,
"build_scorer": 74384,
"advance": 0,
"advance_count": 0
}
},
{
"type": "TermQuery",
"description": "nick: ",
"time": "480.5ms",
"time_in_nanos": 480508016,
"breakdown": {
"score": 278358058,
"build_scorer_count": 72,
"match_count": 0,
"create_weight": 6041,
"next_doc": 192388910,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 5056541,
"score_count": 4665006,
"build_scorer": 33387,
"advance": 0,
"advance_count": 0
}
},
{
"type": "TermQuery",
"description": "nick:黄色",
"time": "3.8ms",
"time_in_nanos": 3872679,
"breakdown": {
"score": 136812,
"build_scorer_count": 50,
"match_count": 0,
"create_weight": 5423,
"next_doc": 3700537,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 923,
"score_count": 755,
"build_scorer": 28178,
"advance": 0,
"advance_count": 0
}
}
]
}
],
"rewrite_time": 583986593,
"collector": [
{
"name": "CancellableCollector",
"reason": "search_cancelled",
"time": "730.3ms",
"time_in_nanos": 730399762,
"children": [
{
"name": "SimpleTopScoreDocCollector",
"reason": "search_top_hits",
"time": "533.2ms",
"time_in_nanos": 533238387
}
]
}
]
}
],
"aggregations": []
},
由于我采用的是HanLP分词,用的这个分词插件elasticsearch-analysis-hanlp,而采用ik_max_word分词却没有相应的问题,这应该是分词插件的bug,于是去github上提了一个issue,有兴趣的可以关注。看来我得去研究一下ElasticSearch Analyze整个流程的源码以及加载插件的源码了 :
一次 ElasticSearch 搜索优化的更多相关文章
- ElasticSearch搜索介绍四
ElasticSearch搜索 最基础的搜索: curl -XGET http://localhost:9200/_search 返回的结果为: { "took": 2, &quo ...
- ElasticSearch性能优化策略【转】
ElasticSearch性能优化主要分为4个方面的优化. 一.服务器部署 二.服务器配置 三.数据结构优化 四.运行期优化 一.服务器部署 1.增加1-2台服务器,用于负载均衡节点 elasticS ...
- 亿级 Elasticsearch 性能优化
前言 最近一年使用 Elasticsearch 完成亿级别日志搜索平台「ELK」,亿级别的分布式跟踪系统.在设计这些系统的过程中,底层都是采用 Elasticsearch 来做数据的存储,并且数据量都 ...
- Elasticsearch搜索调优权威指南 (2/3)
本文首发于 vivo互联网技术 微信公众号 https://mp.weixin.qq.com/s/AAkVdzmkgdBisuQZldsnvg 英文原文:https://qbox.io/blog/el ...
- Elasticsearch搜索调优权威指南 (1/3)
本文首发于 vivo互联网技术 微信公众号 https://mp.weixin.qq.com/s/qwkZKLb_ghmlwrqMkqlb7Q英文原文:https://qbox.io/blog/ela ...
- Elasticsearch搜索资料汇总
Elasticsearch 简介 Elasticsearch(ES)是一个基于Lucene 构建的开源分布式搜索分析引擎,可以近实时的索引.检索数据.具备高可靠.易使用.社区活跃等特点,在全文检索.日 ...
- 【随笔】Android应用市场搜索优化(ASO)
参考了几篇网上的关于Android应用市场搜索优化(ASO)的分析,总结几点如下: 优化关键字:举例目前美团酒店在各Android市场上的关键字有“美团酒店.钟点房.团购.7天”等等,而酒店类竞对在“ ...
- Elasticsearch搜索结果返回不一致问题
一.背景 这周在使用Elasticsearch搜索的时候遇到一个,对于同一个搜索请求,会出现top50返回结果和排序不一致的问题.那么为什么会出现这样的问题? 后来通过百度和google,发现这是因为 ...
- 针对TianvCms的搜索优化文章源码(无版权, 随便用)
介绍: 搜索优化虽然不是什么高深的技术, 真正实施起来却很繁琐, 后台集成搜索优化的文章可以便于便于管理, 也让新手更明白优化的步奏以及优化的日常. 特点: 根据自己的经验和查阅各种资料整理而成, 相 ...
随机推荐
- 20年硅谷技术牛人到访DataPipeline谈:技术如何与业务平衡发展
导读:技术人员的常态是“左手支持业务签单,右手提升系统性能”,却经常陷入技术和业务该如何平衡发展的困惑?今天,且听一位硅谷牛人分享他的平衡之道. 以个人名誉申请31个国内外技术和产品专利,中国最佳CT ...
- 在chrome 怎么通过ajax请求加载本地文件
在chrome下面用Jquery 的load方法加载本地的html文件时会报错 我百度了一下是因为 谷歌浏览器内核为了安全机制,不允许这样方式访问其他页面,但是可以通过加 --enable-file- ...
- Raneto中文搜索支持
背景 因业务部门需要在线软件使用说明文档,但我们资源不足,故我想找一个开源的知识库,发现 Raneto不错,决定使用. 官方文档相当清晰,部署完成,发布一些文章,启动项目,交由业务同事测试使用,于是我 ...
- Django ORM 使用原生 SQL
使用原生sql的 方法 : raw # row方法:(掺杂着原生sql和orm来执行的操作) res = CookBook.objects.raw('select id as nid from epo ...
- centos6.5搭建hadoop完整教程
https://blog.csdn.net/hanzl1/article/details/79040380 博客地址http://blog.csdn.net/pucao_cug/article/det ...
- Host Only、NAT和Bridge三种网络连接
Host Only.NAT和Bridge三种网络连接 在安装好了Linux镜像之后,如何连接物理机和虚拟机呢?这就需要网络连接,网络连接有三种:HostOnly.NAT.Bridge,它们都可用于Gu ...
- 【故障公告】SendCloud 邮件发送服务故障造成大量 QQ 邮箱收不到邮件
抱歉,由于我们所使用的搜狐旗下的 SendCloud 邮件发送服务出现故障,今天上午大量发往 @qq.com 邮箱的邮件无法正常发送,从 SendCloud 管理控制台看这些邮件一直处于“请求中”的状 ...
- MATLAB GUI界面设计------“轴”组件配置
1> Fontsize 10 %字体大小 2> FontUnits normalized %采用相对度量单位,缩放时保持 ...
- zcu102 hdmi example(一)
1,概述 有一个计划是打算做一个摄像头的驱动与显示. 但是实际上手上只有一个zcu102开发板,没有摄像头,也没有上位机,自己也不会写.所以就将方案阉割成将录制好的视频放在SD卡里面,然后从SD卡里面 ...
- XML的几种转换
package com.qbskj.project.util; import java.io.ByteArrayOutputStream; import java.util.ArrayList; im ...