Storm学习笔记 - Storm初识
Storm学习笔记 - Storm初识
1. Strom是什么?
Storm是一个开源免费的分布式计算框架,可以实时处理大量的数据流。
2. Storm的特点
- 高性能,低延迟。
- 分布式:可解决数据量大,单机搞不定的场景。
- 可扩展:随着业务的发展,数据量越来越大,系统可以水平扩展。
容错:单个节点挂了,不影响整个应用。
3. Storm与其他框架的比较
3.1 Storm和Hadoop的比较
- Storm用于实时计算,Hadoop用于离线计算。
- Storm处理的数据保存在内存中,源源不断。Hadoop处理的数据保存在文件系统中,一批一批。
Storm与Hadoop的编程模型相似。
3.2 Storm与Spark streaming的比较
- Spark streaming采用小批量的方式,提高了吞吐性能。
处理数据的粒度变大,导致Spark streaming的数据延时不如Storm,Spark streaming是秒级返回结果(与设置的batch间隔有关),Storm则是毫秒级。
4. Storm集群架构
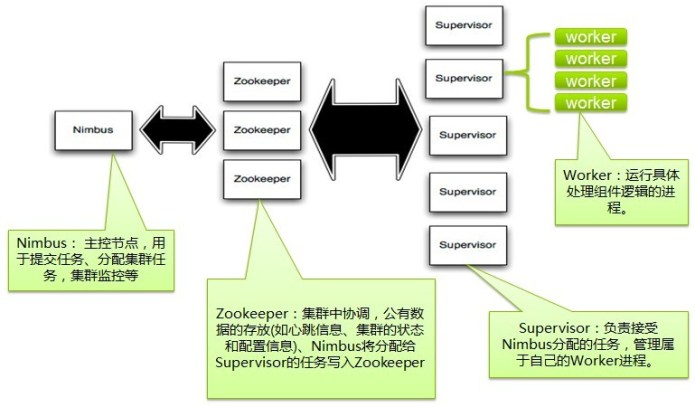
- Nimbus:Storm集群的主节点,负责分发用户代码,指派给具体的Supervisor节点上的Worker节点,去运行Topology对应的组件(Spout/Bolt)的Task。
- Supervisor,Storm集群的从节点,负责管理运行在Supervisor节点上的每一个Worker的启动和终止。可以通过配置项决定在一个Supervisor上最大可以运行多少个Slot,每个Slot通过端口号来唯一标识,一个端口号对应一个Worker进程。
- Worker:运行处理具体组件逻辑的进程,Worker运行的进程只有两种,一种是Spout进程,一种是Bolt进程。
- Task:Worker中每一个Spout/bolt的线程称为一个Task。
Zookeeper:用来协调Nimbus和Supervisor,如果Supervisor因故障出现问题而无法运行Topology,Nimbus会第一时间感知到,并重新分配Topology到其他可用的Supervisor上运行。
5. Storm编程模型
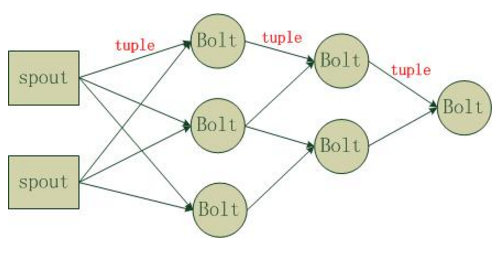
- Topology:Storm中运行的一个实时应用程序的名称。将 Spout、 Bolt整合起来的拓扑图。定义了 Spout和Bolt的结合关系、并发数量、配置等等。
- Spout:在一个topology中获取源数据流的组件。通常情况下spout会从外部数据源中读取数据,然后转换为topology内部的源数据。
- Bolt:接受数据然后执行处理的组件,用户可以在其中执行自己想要的操作。
- Tuple:一次消息传递的基本单元,理解为一组消息就是一个Tuple。
Stream:Tuple的集合。表示数据的流向。
6. 总结
- 拓扑(Topology):打包好的实时应用计算任务,同Hadoop的MapReduce任务相似。
- 元组(Tuple):是Storm提供的一个轻量级的数据格式,可以用来包装你需要实际处理的数据。
- 流(Streams):数据流(Stream)是Storm中对数据进行的抽象,它是时间上无界的tuple元组序列(无限的元组序列)。
- Spout(喷嘴):Storm中流的来源。Spout从外部数据源,如消息队列中读取元组数据并吐到拓扑里。
- Bolts:在拓扑中所有的计算逻辑都是在Bolt中实现的。
- 任务(Tasks):每个Spout和Bolt会以多个任务(Task)的形式在集群上运行。
- 组件(Component):是对Bolt和Spout的统称。
- 流分组(Stream groupings):流分组定义了一个流在一个消费它的Bolt内的多个任务(task)之间如何分组。
- 可靠性(Reliability):Storm保证了拓扑中Spout产生的每个元组都会被处理。
- Workers(工作进程):拓扑以一个或多个Worker进程的方式运行。每个Worker进程是一个物理的Java虚拟机,执行拓扑的一部分任务。
- Executor(线程):是1个被worker进程启动的单独线程。每个executor只会运行1个topology的1个component。
- Nimbus:Storm集群的Master节点,负责分发用户代码,指派给具体的Supervisor节点上的Worker节点,去运行Topology对应的组件(Spout/Bolt)的Task。
Supervisor:Storm集群的从节点,负责管理运行在Supervisor节点上的每一个Worker进程的启动和终止。
Storm学习笔记 - Storm初识的更多相关文章
- Storm学习笔记 - 消息容错机制
Storm学习笔记 - 消息容错机制 文章来自「随笔」 http://jsynk.cn/blog/articles/153.html 1. Storm消息容错机制概念 一个提供了可靠的处理机制的spo ...
- LevelDB学习笔记 (1):初识LevelDB
LevelDB学习笔记 (1):初识LevelDB 1. 写在前面 1.1 什么是levelDB LevelDB就是一个由Google开源的高效的单机Key/Value存储系统,该存储系统提供了Key ...
- Twitter Storm学习笔记
官方英文文档:http://storm.apache.org/documentation/Documentation.html 本文是学习笔记,转载整合加翻译,主要是为了便于学习. 一.基本概念 参考 ...
- Storm学习笔记——简介
1. 简介 流式计算的历史 早在7.8年前诸如UC伯克利.斯坦福等大学就开始了对流式数据处理的研究,但是由于更多的关注于金融行业的业务场景或者互联网流量监控的业务场景,以及当时互联网数据场景的限制,造 ...
- Java学习笔记心得——初识Java
初识Java 拿到这本厚厚的<Java学习笔记>,翻开目录:Java平台概论.从JDK到TDE.认识对象.封装.继承与多态...看着这些似懂非懂的术语名词,心里怀着些好奇与担忧,就这样我开 ...
- Storm学习笔记——高级篇
1. Storm程序的并发机制 1.1 概念 Workers (JVMs): 在一个物理节点上可以运行一个或多个独立的JVM 进程.一个Topology可以包含一个或多个worker(并行的跑在不同的 ...
- Storm学习笔记
1.如何让一个spout并行读取多个流? 方法:任何spout.bolts组件都可以访问TopologyContext.利用这个特性可以让Spouts的实例之间划分流. 示例:获取到storm集群sp ...
- Storm学习笔记六
1 Storm的通信机制 说明:1.worker与worker之间跨进程通信: 2.worker内部中各个executor间的通信,Task对象--->输入队列queue--->执行--- ...
- storm学习笔记(一)
1.storm介绍 storm是一种用于事件流处理的分布式计算框架,它是有BackType公司开发的一个项目,于2014年9月加入了Apahche孵化器计划并成为其旗下的顶级项目之一. ...
随机推荐
- Postman测试上传文件
postman测试上传文件 输入url:http://127.0.0.1:8081/uploadfile 选择post方式 选择body 选择form-data,text改为file 输入key: ...
- 基于flask+gunicorn+nginx来部署web App
基于flask+gunicorn&&nginx来部署web App WSGI协议 Web框架致力于如何生成HTML代码,而Web服务器用于处理和响应HTTP请求.Web框架和Web服务 ...
- Codeforces 677E Vanya and Balloons
Vanya and Balloons 枚举中心去更新答案, 数字过大用log去比较, 斜着的旋转一下坐标, 然后我旋出来好多bug.... #include<bits/stdc++.h> ...
- 【redis】在dotnet core下的redis的使用
1.Install-Package Microsoft.Extensions.Caching.Redis -Version 2.2.0 2.注入 services.AddDistributedRedi ...
- 快速安装puppeteer (跳过安装Chromium)
npm i --save puppeteer --ignore-scripts
- python爬虫实践(二)——爬取张艺谋导演的电影《影》的豆瓣影评并进行简单分析
学了爬虫之后,都只是爬取一些简单的小页面,觉得没意思,所以我现在准备爬取一下豆瓣上张艺谋导演的“影”的短评,存入数据库,并进行简单的分析和数据可视化,因为用到的只是比较多,所以写一篇博客当做笔记. 第 ...
- vector的用法小结(待补全
1.vector的好处 支!持!删!除! 节!省!内!存! 2.一点基础的小操作 ①插入操作:v.push_back(x) 在尾部插入元素x: ②删除操作 : v.erase(x)删除地址为x的元素 ...
- VB使用API进行RC4加密解密(MD5密钥)
根据网络资料整改,来源未知,已调试通过. Option Explicit Private Declare Function CryptAcquireContext Lib "advapi32 ...
- IIS 设置
解决办法:1. 1).通过webconfig中增加模拟,加入管理员权限, <identity impersonate="true" userName="系统管理员& ...
- Autograd:自动微分
Autograd 1.深度学习的算法本质上是通过反向传播求导数,Pytorch的Autograd模块实现了此功能:在Tensor上的所有操作,Autograd都能为他们自动提供微分,避免手动计算导数的 ...