hive的排序,分組练习
hive的排序,分組练习
数据:
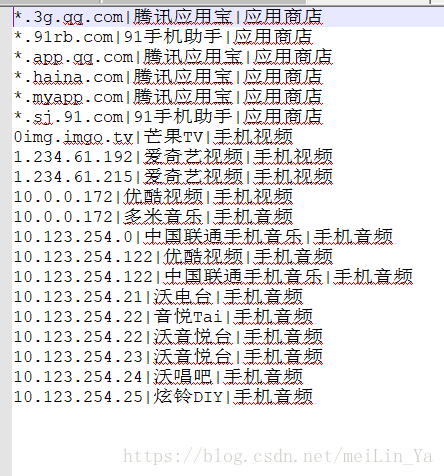
添加表和插入数据(数据在Linux本地中)
create table if not exists tab1(
IP string,
SOURCE string,
TYPE string
)
row format delimited fields terminated by '|'
stored as textfile;
load data local inpath '/home/data/data1.txt' into table tab1;
1.问题:(top10)按照来源排序,访问量高的排最上面
select source,count(*) num
from tab1
group by source
order by num desc;select 查询在order by 前

2.问题:(推荐系统)给一个用户ip地址,得到用户经常访问的应用类型后,推荐用户同种类型的其他应用

数据二:
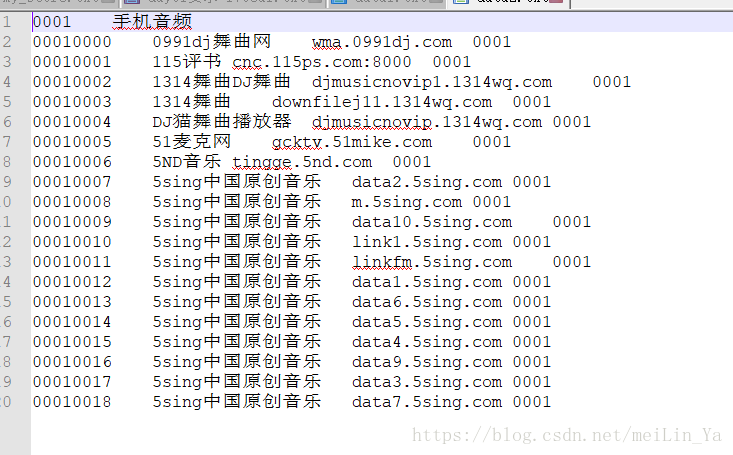
建表,填数据:
create table if not exists tab2(
id string,
name string,
url string,
pid string
)
row format delimited fields terminated by '\t'
stored as textfile;
load data local inpath '/home/data/data2.txt' into table tab2;
1.问题:(数据清洗)合并name与url,格式为 NAME:name|URL:url
select concat('NAME:',name,'|','URL:',url)
from tab2
where name is not null and url is not null;
数据三:
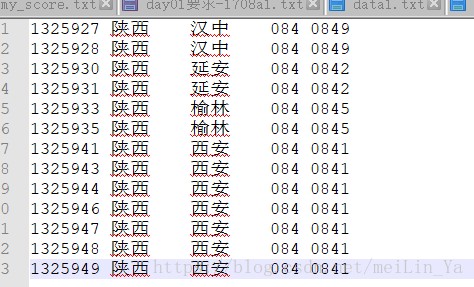
表的建立和数据插入
create table if not exists tab4(
no string,
province string,
city string,
pid string,
cid string
)
row format delimited fields terminated by '\t'
stored as textfile;
load data local inpath '/home/data/data4.txt' into table tab4;1.问题:从源数据中筛出pid与省份、cid与城市,并且创建新表保存 去重 distinct
这里使用加行键的方法,实行唯一标识。
select pid,province
from tab4
group by pid,province
limit 1
select t1.cid,t1.city,t1.rank
from(
select cid,city,row_number() over (partition by cid order city) rank
from tab4
group by cid,city) t1
where t1.rank=1;

数据四:
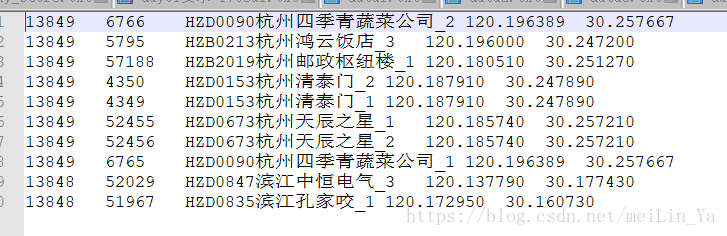
新建表以及添加数据
create table if not exists tab5(
lac string,
cellid string,
cell_name string,
longitude string,
latitude string
)
row format delimited fields terminated by '\t'
stored as textfile;
load data local inpath '/home/data/data5.txt' into table tab5;1.问题:从cell_name列中截取需要的部分,例如 HZD0090,截取D0090杭州四季青蔬菜公司,截取D0090

数据五:

建表+添加数据
create table if not exists tab6(
id string,
service string
)
row format delimited fields terminated by '\t'
stored as textfile;
load data local inpath '/home/data/data6.txt' into table tab6;问题:去除所有父类服务,只要子类服务(id 是字符串类型)
select * from tab6 where id>100

数据六:

添加数据:
create table if not exists tab7(
id string,
type string,
sagem string
)
row format delimited fields terminated by '\t'
stored as textfile;
load data local inpath '/home/data/data7.txt' into table tab7;
问题:按照设备类型,统计出现的频率
select type,count(*)
from tab7
group by type;
数据七:

问题:去重后存入到新表中
select col,row_number() over (partition by col order by col) rank
from tab10
group by col;hive的排序,分組练习的更多相关文章
- Hive为什么要分桶
对于每一个表(table)或者分区, Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分.Hive也是针对某一列进行桶的组织.Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记 ...
- Hive学习笔记——Hive中的分桶
对于每一个表(table)或者分区, Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分.Hive也是针对某一列进行桶的组织.Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记 ...
- Hive 学习之路(五)—— Hive 分区表和分桶表
一.分区表 1.1 概念 Hive中的表对应为HDFS上的指定目录,在查询数据时候,默认会对全表进行扫描,这样时间和性能的消耗都非常大. 分区为HDFS上表目录的子目录,数据按照分区存储在子目录中.如 ...
- Hive 系列(五)—— Hive 分区表和分桶表
一.分区表 1.1 概念 Hive 中的表对应为 HDFS 上的指定目录,在查询数据时候,默认会对全表进行扫描,这样时间和性能的消耗都非常大. 分区为 HDFS 上表目录的子目录,数据按照分区存储在子 ...
- 入门大数据---Hive分区表和分桶表
一.分区表 1.1 概念 Hive 中的表对应为 HDFS 上的指定目录,在查询数据时候,默认会对全表进行扫描,这样时间和性能的消耗都非常大. 分区为 HDFS 上表目录的子目录,数据按照分区存储在子 ...
- Crystal Report分組中的序號重新遞增
客戶要批次列印發票,也就是報表需要按照發票號碼(INV_NO)進行分組,每個發票里還有明細的item,之前因為直接抓RecordNumber,所以該欄位只能從1開始計數,遇到新的發票發號不會重新從1開 ...
- hive 分组排序,topN
hive 分组排序,topN 语法格式:row_number() OVER (partition by COL1 order by COL2 desc ) rankpartition by:类似hiv ...
- hive -- 分区,分桶(创建,修改,删除)
hive -- 分区,分桶(创建,修改,删除) 分区: 静态创建分区: 1. 数据: john doe 10000.0 mary smith 8000.0 todd jones 7000.0 boss ...
- laravel 路由分組
laravel 路由分組 Route::group(['prefix' => 'admin'], function () { $namespacePrefix="\\App\\Http ...
随机推荐
- 认识.net
.NET多指NET Framework,Visual Studio.NET及其开发的应用程序.NET Framework是一个开发和执行环境,允许不同的程序语言和库无缝结合基于Window的应用程序. ...
- 高校表白APP-冲刺第一天
今天我们开了第一次会议, 一.任务: 今日任务布局登录页面,注册页面,修改密码界面 明日任务完成基本的登录页面框架 二.遇到的困难: 布局文件里的一些标签,用法不清楚,页面跳转都得学习.
- spring-boot集成activiti的model遇到问题汇总
按照网上的七拼八凑整合网页版的部署将遇到的问题归置如下: 本人的springboot版本是:1.5.13.RELEASE 工作流相关: <!--工作流--> <dependency& ...
- springboot使用@data注解,减少不必要代码
一.idea安装lombok插件 二.重启idea 三.添加maven依赖 <dependency> <groupId>org.projectlombok</groupI ...
- 解析url成对象形式
请编写一个JavaScript函数parseQueryString,他的用途是把URL参数解析为一个对象 var url = "https://www.baidu.com/s?ie=utf- ...
- .NET平台常用的开发组件(csdn)
.NET平台常用的开发组件 原创 2017年02月24日 09:20:04 工欲善其事,必先利其器.学习.NET也10年有余,其优雅的编程风格,高效率的开发速度,极度简单的可扩展性,足够强大开发类库, ...
- Java集合与泛型中的陷阱
List,List<Object>区别 List<Integer> t1 = new ArrayList<>(); // 编译通过 List t2 = t1; // ...
- BZOJ-3208|记忆化搜索-花神的秒题计划Ⅰ
背景[backboard]: Memphis等一群蒟蒻出题中,花神凑过来秒题-- 描述[discribe]: 花花山峰峦起伏,峰顶常年被雪,Memphis打算帮花花山风景区的人员开发一个滑雪项目. 我 ...
- WEB API 系列(二) Filter的使用以及执行顺序
在WEB Api中,引入了面向切面编程(AOP)的思想,在某些特定的位置可以插入特定的Filter进行过程拦截处理.引入了这一机制可以更好地践行DRY(Don’t Repeat Yourself)思想 ...
- unittest用例执行的顺序
unittest在执行用例(test_xxx)时,并不是按从上到下的顺序执行,有特定的顺序. 示例: import unittest class TestBdd(unittest.TestCase): ...