MySQL全连接(Full Join)实现,union和union all用法
下面是一个简单测试,可以看看:
mysql> CREATE TABLE a(id int,name char(1));
Query OK, 0 rows affected (0.00 sec)
mysql> CREATE TABLE b(id int,name char(1));
Query OK, 0 rows affected (0.00 sec)
mysql> INSERT INTO a VALUES(1,'a'),(2,'b');
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> INSERT INTO b VALUES(2,'b'),(3,'c');
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> SELECT * FROM a LEFT JOIN b ON a.id=b.id
-> UNION
-> SELECT * FROM a RIGHT JOIN b ON a.id=b.id;
+------+------+------+------+
| id | name | id | name |
+------+------+------+------+
| 1 | a | NULL | NULL |
| 2 | b | 2 | b |
| NULL | NULL | 3 | c |
+------+------+------+------+
3 rows in set (0.00 sec)
mysql>
MySQL UNION 语法
MySQL UNION 用于把来自多个 SELECT 语句的结果组合到一个结果集合中。语法为:
SELECT column,... FROM table1
UNION [ALL]
SELECT column,... FROM table2
...
在多个 SELECT 语句中,对应的列应该具有相同的字段属性,且第一个 SELECT 语句中被使用的字段名称也被用于结果的字段名称。
UNION 与 UNION ALL 的区别
当使用 UNION 时,MySQL 会把结果集中重复的记录删掉,而使用 UNION ALL ,MySQL 会把所有的记录返回,且效率高于 UNION。
MySQL UNION 用法实例
UNION 常用于数据类似的两张或多张表查询,如不同的数据分类表,或者是数据历史表等。下面是用于例子的两张原始数据表:
| aid | title | content |
|---|---|---|
| 1 | 文章1 | 文章1正文内容... |
| 2 | 文章2 | 文章2正文内容... |
| 3 | 文章3 | 文章3正文内容... |
| bid | title | content |
|---|---|---|
| 1 | 日志1 | 日志1正文内容... |
| 2 | 文章2 | 文章2正文内容... |
| 3 | 日志3 | 日志3正文内容... |
上面两个表数据中,aid=2 的数据记录与 bid=2 的数据记录是一样的。
使用 UNION 查询
查询两张表中的文章 id 号及标题,并去掉重复记录:
SELECT aid,title FROM article UNION SELECT bid,title FROM blog
返回查询结果如下:
| aid | title |
|---|---|
| 1 | 文章1 |
| 2 | 文章2 |
| 3 | 文章3 |
| 1 | 日志1 |
| 3 | 日志3 |
UNION 查询结果说明
- 重复记录是指查询中各个字段完全重复的记录,如上例,若 title 一样但 id 号不一样算作不同记录。
- 第一个 SELECT 语句中被使用的字段名称也被用于结果的字段名称,如上例的 aid。
- 各 SELECT 语句字段名称可以不同,但字段属性必须一致。
使用 UNION ALL 查询
查询两张表中的文章 id 号及标题,并返回所有记录:
SELECT aid,title FROM article UNION ALL SELECT bid,title FROM blog
返回查询结果如下:
| aid | title |
|---|---|
| 1 | 文章1 |
| 2 | 文章2 |
| 3 | 文章3 |
| 1 | 日志1 |
| 2 | 文章2 |
| 3 | 日志3 |
显然,使用 UNION ALL 的时候,只是单纯的把各个查询组合到一起而不会去判断数据是否重复。因此,当确定查询结果中不会有重复数据或者不需要去掉重复数据的时候,应当使用 UNION ALL 以提高查询效率。
 我要投稿
我要投稿-
连接就是将两个表按照某个公共字段来拼成一个大表。
左连接就是在做连接是以左边这个表为标准,来遍历右边的表。
1、引子
左连接,自连接
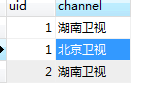
结果:
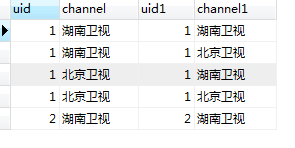
2、问题 例子:
用户访问记录:
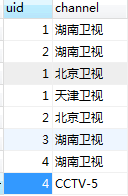
问题:查出看了湖南卫视但没有看北京卫视的用户信息
逻辑:先通过左连接将看了湖南卫视和北京卫视的查出来,然后再将看了湖南卫视但不在刚才查出的结果中的用户查出来。
123SELECT*FROMtest_visitWHEREchannel='湖南卫视'ANDuidNOTIN(SELECTDISTINCTt1.uidFROMtest_visit t1LEFTJOINtest_visit t2ONt1.uid = t2.uidWHEREt1.channel='湖南卫视'ANDt2.channel='北京卫视')SELECT语句中的自连接。
到目前为止,我们连接的都是两张不同的表,那么能不能对一张表进行自我连接呢?答案是肯定的。
有没有必要对一张表进行自我连接呢?答案也是肯定的。表的别名:
一张表可以自我连接。进行自连接时我们需要一个机制来区分一个表的两个实例。
在FROM clause(子句)中我们可以给这个表取不同的别名, 然后在语句的其它需要使用到该别名的地方
用dot(点)来连接该别名和字段名。我们在这里同样给出两个表来对自连接进行解释。
爱丁堡公交线路,车站表:
stops(id, name)公交线路表:
route(num, company, pos, stop)一、对公交线路表route进行自连接。
SELECT * FROM route R1, route R2
WHERE R1.num=R2.num AND R1.company=R2.company我们route表用字段(num, company)来进行自连接. 结果是什么意思呢?
你可以知道每条公交线路的任意两个可联通的车站。二、用stop字段来对route(公交线路表)进行自连接。
SELECT * FROM route R1, route R2
WHERE R1.stop=R2.stop;查询的结果就是共用同一车站的所有公交线。这个结果对换乘是不是很有意义呢。
从这两个例子我们可以看出,自连接的语法结构很简单,但语意结果往往不是
那么容易理解。就我们这里所列出的两个表,如果运用得当,能解决很多实际问题,
例如,任意两个站点之间如何换乘。SELECT R1.company, R1.num
FROM route R1, route R2, stops S1, stops S2
WHERE R1.num=R2.num AND R1.company=R2.company
AND R1.stop=S1.id AND R2.stop=S2.id
AND S1.name='Craiglockhart'
AND S2.name='Tollcross'
MySQL全连接(Full Join)实现,union和union all用法的更多相关文章
- mysql 全连接 报错1051的原因
由于mysql 不支持 直接写full outer join 或者 full join来表示全外连接但是可以用left right union right 代替 下面是例子: select * fro ...
- mysql 全连接和 oracle 全连接查询、区别
oracle的全连接查询可以直接用full on,但是在mysql中没有full join,mysql使用union实现全连接. oracle的全连接 select * from a full joi ...
- mysql全连接
Oracle数据库支持full join,mysql是不支持full join的,但仍然可以同过左外连接+ union+右外连接实现 SELECT * FROM t1 LEFT JOIN t2 ON ...
- mysql之左连接、右连接、内连接、全连接、等值连接、交叉连接等
mysql中的各种jion的记录,以备用时查 1.等值连接和内连接, a.内连接与等值连接效果是相同的,执行效率也相同,只是书写方式不一样,内连接是由SQL 1999规则定的书写方式 比如: sele ...
- SQL 连接 JOIN 例解。(左连接,右连接,全连接,内连接,交叉连接,自连接)
SQL 连接 JOIN 例解.(左连接,右连接,全连接,内连接,交叉连接,自连接) 最近公司在招人,同事问了几个自认为数据库可以的应聘者关于库连接的问题,回答不尽理想-现在在这写写关于它们的作用假设有 ...
- oracle 内连接(inner join)、外连接(outer join)、全连接(full join)
转自:https://premier9527.iteye.com/blog/1659689 建表语句: create table EMPLOYEE(EID NUMBER,DEPTID NUMBER,E ...
- MySQL的连接类型
首先我们来创建两个数据表: 结构: 我们用内连接来查看一下: select * from test1 join test2 on test1.aid=test2.aid; 由于内连接是等值连接,所 ...
- 图解SQL inner join、left join、right join、full outer join、union、union all的区别
转于:http://justcoding.iteye.com/blog/2006487 这是一篇来自Coding Horror的文章. SQL的Join语法有很多:有inner的,有outer的,有l ...
- MySQL内连接和外连接
INNER JOIN(内连接,或等值连接):获取两个表中字段匹配关系的记录. LEFT JOIN(左连接):获取左表所有记录,即使右表没有对应匹配的记录. RIGHT JOIN(右连接): 与 LEF ...
随机推荐
- vue实现一个移动端屏蔽滑动的遮罩层
在扯废话浪费大家的时间之前,先上个代码好了,使用vue实现起来很简单-- <div class="overlayer" @touchmove.stop > </d ...
- 限制 UITextField 输入长度
限制 UITextField 输入长度 标签(空格分隔): UITextField UITextField 是 iOS 中最经常使用的组件之中的一个.关于它也有各种各样的需求,这些需求是它本身没有提供 ...
- digoal -阿里云postgrel大神
https://yq.aliyun.com/users/1384833841157402?spm=5176.100239.blogrightarea51131.3.T5LRsF
- Qt国际化详细介绍,中文乱码以及解决方案
Qt国际化的一般步骤 运行 lupdate,从应用程序的代码中提取所有界面上的可见字符. 这些可见字符必须被 tr() .QCoreApplication::translate().Qt ...
- Java基础知识强化之集合框架笔记10:Collection集合使用的步骤
集合使用的步骤: (1)创建集合对象 (2)创建元素对象 (3)把元素添加到集合 (4)遍历集合: • 通过集合对象获取迭代器对象 • 通过迭代器对象的hasnext()方法判断是否有元素 ...
- HDU 5040 Instrusive(BFS+优先队列)
题意比较啰嗦. 就是搜索加上一些特殊的条件,比如可以在原地不动,也就是在原地呆一秒,如果有监控也可以花3秒的时间走过去. 这种类型的题目还是比较常见的.以下代码b[i][j][x]表示格子i行j列在x ...
- Android 静默安装/后台安装
Android实现静默安装其实很简单,今天在网上找资料找半天都说的很复杂,什么需要系统安装权限.调用系统隐藏的api.需要系统环境下编译.需要跟systemUI同进程什么的.我不知道他们真的实现了静默 ...
- frontpage 正则 查找与替换
frontpage正则查找替换 frontpage查找用{}[不是() ]来匹配pattern, 并获取这一匹配 替换时匹配的字符用\1 \2 \3表示 第 N 个标记表达式 \N 在“替换”表达式中 ...
- jQuery创建ajax关键词数据搜索
在web开发过程当中,我们经常需要在前台页面输入关键词进行数据的搜索,我们通常使用的搜索方式是将搜索结果用另一个页面显示,这样的方式对于搭建高性能网站来说不是最合适的,今天给大家分享一下如何使用 jQ ...
- Overload和Override的区别?
Overload和Override的区别? Override是重写:方法名称.参数个数,类型,顺序,返回值类型都是必须和父类方法一致的.它的关系是父子关系Overload是重载:方法名称不变,其余的都 ...