【C# 集合】Hash哈希函数 |散列函数|摘要算法
希函数定义
哈希函数(英語:Hash function)又称散列函数、散列函数、摘要算法、单向散列函数。散列函数把消息或数据压缩成摘要,使得数据量变小,将数据的格式固定下来。该函数将数据打乱混合,重新创建一个(哈希函数返回的值)称为指纹、哈希值、哈希代码、摘要或散列值(hash values,hash codes,hash sums,或hashes)的指纹。散列值通常用一个短的随机字母和数字组成的字符串来代表。[1]好的散列函数在输入域中很少出现散列冲突。
完美哈希函数 就是指没有冲突的哈希函数。
如今,散列算法也被用来加密存在数据库中的密码(password)字符串,由于散列算法所计算出来的散列值(Hash Value)具有不可逆(无法逆向演算回原本的数值)的性质,因此可有效的保护密码。
使用哈希函数为哈希表编制索引称为哈希或分散存储寻址。
哈希函数的特性:
- 单向散列函数(one-wayhash function),也就是通俗叫的哈希函数。
- 第一个特点:输入可以任意长度,输出是固定长度
- 第二个特点:计算hash值的速度比较快
- 第三个特点,冲突特性(Collision resistance):找出任意两个不同的输入值 x、y,使得 H (x)= H (y)是困难的。(这里称为「困难」的原因,是消息空间是无穷的,而哈希值空间是有限的,因此一定会存在碰撞,只是对寻找碰撞的算力需要有难度上的约束以哈希函数 SHAI (输出为 160-bit)为例:其输出空间为(0,2^160),假设输出范围一万亿个哈希值,发生碰撞的概率仅为 3×10-25。被碰撞的概率太低,几乎不可能。
- 第四个特点:隐藏性(Hiding)或者叫做单向性(one-way):哈希函数的单向性意味着,给定一个哈希值,我们无法(很难)逆向计算出其原像输入。
- 第五点:谜题友好(puzzlefriendly)
HashTable
定义
哈希表时保存数据的表。通过哈希函数使得数据和存储位置之间建立一一对应的映射关系。在查找时,通过哈希函数可以直接找到该元素。
HashTable负载因子
负载因子 = 填入表中的元素个数 / 哈希表的长度
负载因子是哈希表装满的标志因子,由于表长是定值,负载因子与填入标志元素的个数成正比,所以负载因子越大,填入表中的元素个数越多,产生冲突的可能性越大,反之,负载因子越小,填入表中的元素个数越少,产生冲突的可能性越小。
对于闭散列,负载因子是一个很重要的因素,因该严格控制在07~0.8左右。超过0.8,CPU缓存命中率降低。所以,在闭散列中,一般负载因子超过0.7就会进行扩容处理。
为什么在散列表中不在负载因子等于1时扩容?
因为当哈希表快满了的时候,插入数据,冲突的概率很大,然后需要查找插入位置。会导致效率降低。
HashTable中避免哈希函数冲突的方法
哈希函数的目标是尽量减少冲突,但实际应用中冲突是无法避免的,所以在HashTable 中哈希函数冲突发生时,必须有相应的解决方案。而发生冲突的可能性又跟以下两个因素有关:
(1) 装填因子α(用于判断何时扩容hashtable .net core 是0.72 java是0.75):所谓装填因子是指合希表中已存入的记录数n与哈希地址空间大小m的比值,即 α=n / m ,α越小,冲突发生的可能性就越小;α越大(最大可取1),冲突发生的可能性就越大。这很容易理解,因为α越小,哈希表中空闲单元的比例就越大,所以待插入记录同已插入的记录发生冲突的可能性就越小;反之,α越大,哈希表中空闲单元的比例就越小,所以待插入记录同已插入记录冲突的可能性就越大;另一方面,α越小,存储窨的利用率就越低;反之,存储窨的利用率就越高。为了既兼顾减少冲突的发生,又兼顾提高存储空间的利用率,通常把α控制在0.6~0.9的范围之内,C#的HashTable类把α的最大值定为0.72。
(2) 与所采用的哈希函数有关。若哈希函数选择得当,就可使哈希地址尽可能均匀地分布在哈希地址空间上,从而减少冲突的发生;否则,就可能使哈希地址集中于某些区域,从而加大冲突发生的可能性。
HashTable中哈希函数冲突解决方法
冲突解决技术可分为两大类:开散列法(又称为链地址法)和闭散列法(又称为开放地址法)。哈希表是用数组实现的一片连续的地址空间,两种冲突解决技术的区别在于发生冲突的元素是存储在这片数组的空间之外还是空间之内:
(1) 开散列法也叫链地址法、拉链法(JAVA采用这种方式)发生冲突的元素存储于数组空间之外。可以把“开”字理解为需要另外“开辟”空间存储发生冲突的元素。
开散列又叫链地址法(开链法),哈希表中的数组是一个指针数组。数据是以链表的形式保存,数组的元素指向链表的头节点。
首先,数据通过哈希函数计算出保存位置,计算出来相同位置的数据归于同一个集合中,每一个子集和称为一个桶,每一个桶中的元素通过链表连接起来,链表的头结点保存在哈希表中。
将哈希冲突的数据一链表的方式保存在一个位置。不会占用其它数据的位置。

开散列增容:
开散列增容看的也是负载因子。
桶的数量是一定的,因为数组的数量一定。随着元素的不断插入,桶中元素的数量会不断增多,极端情况下,可能会导致一个桶中数量链表结点非常多,在查找元素时,会影响哈希表的效率。
因此在一定情况下要对哈希表进行增容。该条件怎么确认呢?最好的情况下,是每一个桶正好一个结点,在插入数据会发生哈希冲突,。
因当插入元素个数正好等于桶的个数时,即负载因子等于1时,可以给哈希表增容。
增容时,会按照哈希函数重新改变位置,减少冲突。
(2) 闭散列法/开放定址法(.net core 采用这种方式)发生冲突的元素存储于数组空间之内。可以把“闭”字理解为所有元素,不管是否有冲突,都“关闭”于数组之中。闭散列法又称开放地址法,意指数组空间对所有元素,不管是否冲突都是开放的。
线性探测
插入
通过哈希函数获取插入位置
如果该位置没有元素,直接插入新元素。如果有元素,发生哈希冲突,在冲突位置顺序往后找下一个空位置,插入新元素。
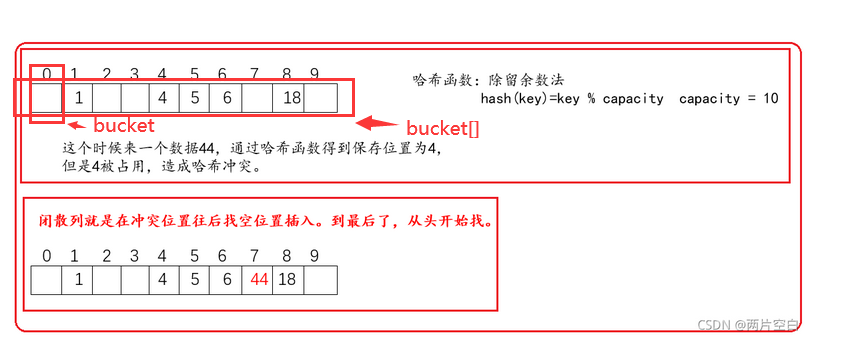
删除
通过线性探测插入元素,我们知道哈希冲突的元素,一定会保存在保存位置的连续且不为空的位置,意思就是找哈希冲突的数据时,往哈希冲突位置往后找到为空位置截至。所以删除数据时,不能随便删除数据。如下: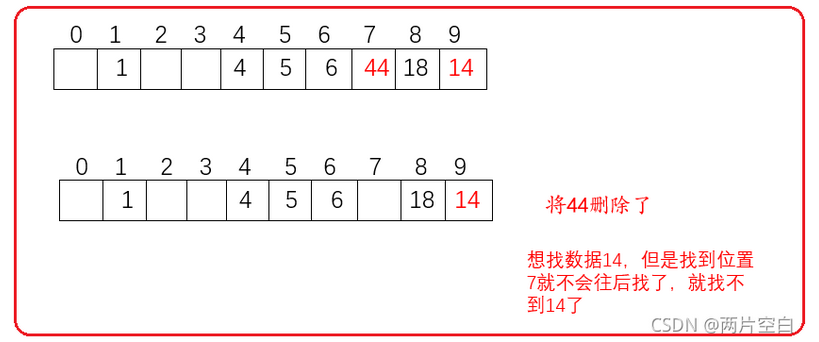
因此线性探测采用标记的伪删除来删除一个元素,就是哈希表中保存的是一个结构体,结构以里有一个变量保存数据,一个变量了代表当前位置的状态。
//状态
enum State{
EXIT,//存在元素
DELETE,//该位置为删除状态
EMPTY,//该位置为空,不存在元素
};
//保存的元素类型
struct Ele{
T _data;//数据
State _state = EMPTY;//状态
};
【来源:https://python.iitter.com/other/68944.html,转载请注明】
线性探测缺点:一旦发生哈希冲突,所有冲突的数据都会连在一起保存,容易产生数据堆积,此时插入一数据时,可能一段位置全被占用了,一直要找空位置,导致效率降低。
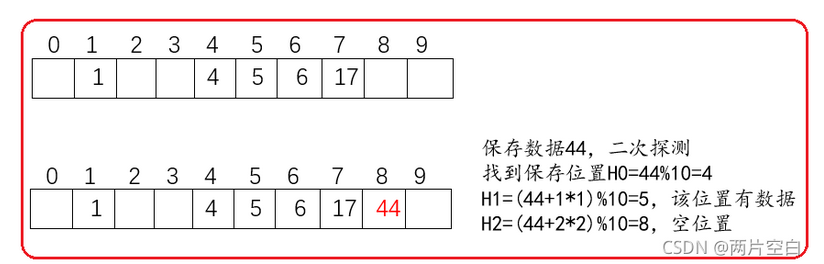
二次探测
针对线性探测导致冲突数据堆积的缺点,二次探测找空位置的方法是:
Hi = (H0 + i * i) % capacity,H0是一开始数据保存的位置,也就是冲突位置,Hi查找的空位置。这样查找可以使得冲突数据位置的错开的。
哈希函数算法「家族」
从哈希(Hash)函数这一概念诞生至今,已经提出了几十种哈希算法
,每类算法对应不同的参数又会形成不同的算法实现。众多的哈希函数如同一个江湖,其中 MD 家族和 SHA 家族是「哈希江湖」中最具声望的两大家族。
国际: MD4、MD5、SHA-1、SHA-256、SHA-3。(MD 系列、SHA-1 已被破解)
国内:国产自主研发的商用密码哈希算法,即 SM3。

【C# 集合】Hash哈希函数 |散列函数|摘要算法的更多相关文章
- Java集合(八)哈希表及哈希函数的实现方式
Java集合(八)哈希表及哈希函数的实现方式 一.哈希表 非哈希表的特点:关键字在表中的位置和它之间不存在一个确定的关系,查找的过程为给定值一次和各个关键字进行比较,查找的效率取决于和给定值进行比较的 ...
- 字符串哈希函数(String Hash Functions)
哈希函数举例 http://www.cse.yorku.ca/~oz/hash.html Node.js使用的哈希函数 https://www.npmjs.org/package/string-has ...
- python hash 哈希值
自增知识点 1,哈希 什么是可哈希(hashable)? 简要的说可哈希的数据类型,即不可变的数据结构(字符串str.元组tuple.对象集objects). 哈希有啥作用? 它是一个将大体量数据转化 ...
- 左神算法第五节课:认识哈希函数和哈希表,设计RandomPool结构,布隆过滤器,一致性哈希,岛问题,并查集结构
认识哈希函数和哈希表 MD5Hash值的返回范围:0~9+a~f,是16位,故范围是0~16^16(2^64)-1, [Hash函数],又叫散列函数: Hash的性质: 1) 输入域无穷大: 2) ...
- Hash哈希(一)
Hash哈希(一) 哈希是大家比较常见一个词语,在编程中也经常用到,但是大多数人都是知其然而不知其所以然,再加上这几天想写一个一致性哈希算法,突然想想对哈希也不是很清楚,所以,抽点时间总结下Hash知 ...
- Python 字典和集合基于哈希表实现
哈希表作为基础数据结构我不多说,有兴趣的可以百度,或者等我出一篇博客来细谈哈希表.我这里就简单讲讲:哈希表不过就是一个定长数组,元素找位置,遇到哈希冲突则利用 hash 算法解决找另一个位置,如果数组 ...
- 算法初级面试题05——哈希函数/表、生成多个哈希函数、哈希扩容、利用哈希分流找出大文件的重复内容、设计RandomPool结构、布隆过滤器、一致性哈希、并查集、岛问题
今天主要讨论:哈希函数.哈希表.布隆过滤器.一致性哈希.并查集的介绍和应用. 题目一 认识哈希函数和哈希表 1.输入无限大 2.输出有限的S集合 3.输入什么就输出什么 4.会发生哈希碰撞 5.会均匀 ...
- 第二百九十六节,python操作redis缓存-Hash哈希类型,可以理解为字典类型
第二百九十六节,python操作redis缓存-Hash哈希类型,可以理解为字典类型 Hash操作,redis中Hash在内存中的存储格式如下图: hset(name, key, value)name ...
- hash 哈希查找复杂度为什么这么低?
hash 哈希查找复杂度为什么这么低? (2017-06-23 21:20:36) 转载▼ 分类: c from: 作者:jillzhang 出处:http://jillzhang.cnblogs ...
随机推荐
- Choregraphe 2.8.6.23虚拟Nao机器人Socket is not connected
Traceback (most recent call last): File "c:/Users/fengmao/OneDrive - University of Wollongong/J ...
- c#重写和多态
多态是基于重写的 继承:向子类中添加父类没有的成员,子类对父类的横向扩展 重写:纵向扩展,成员没有增加,但成员的版本增加了 引言 Rider JetBrains:Rider.ReSharper.dot ...
- 【简记】SpringBoot禁用Swagger
楔子 Swagger 是 Java Web 开发中常用的接口文档生成类库,在开发和前后端联调时使用它来模拟接口调用能提高开发效率.但是,在生产环境可能并不需要它,一个原因是启用它会延长程序启动时间(动 ...
- python浮点数计算--5
#!/usr/bin/python #coding=utf-8 i=1.0 j=3 print(i*j) print(i+j) print(i**j) 备注:无论是哪种运算,只要有操作数是浮点数,py ...
- 学习JAVAWEB第四天
# 今日内容 1. JDBC基本概念 2. 快速入门 3. 对JDBC中各个接口和类详解 ## JDBC: 1. 概念:Java DataBase Connectivity Java 数据库连接, J ...
- 计算机网络再次整理————socket[一]
前言 以前也整理过吧,写了几篇之后,感觉没啥整理的必要了然后就放弃了,最近又想整理一下. 正文 这篇对应的是:https://www.cnblogs.com/aoximin/p/12235333.ht ...
- C++ POD 类型
POD 是 C++ 中一个比较重要的概念,POD 是英文 Plain Old Data 的缩写(通俗讲就是类或结构体通过二进制拷贝后还能保持其数据不变),用来描述一个类型(包括 class.union ...
- ApacheCN 编程/大数据/数据科学/人工智能学习资源 2019.12
公告 我们的所有非技术内容和活动,从现在开始会使用 iBooker 这个名字. "开源互助联盟"已终止,我们对此表示抱歉和遗憾.除非特地邀请,我们不再推广他人的任何项目. 公众号自 ...
- Properties打印流
简介 java.util.Properties 继承于 Hashtable ,来表示一个持久的属性集.它使用键值结构存储数据,每个键及其对应值都是一个字符串.该类也被许多Java类使用,比如获取系统属 ...
- Entity Framework Core的坑,Select后再对导航属性进行查询或Select前进行Skip/Take
把asp.net core的项目发布到ubuntu上了,运行的时候出现了如下警告: warn: Microsoft.EntityFrameworkCore.Query[20500] The LINQ ...