为何要打印日志?C++在高并发下如何写日志文件(附源码)?
为何要打印日志?让程序裸奔不是一件很快乐的事么?
有些BUG就像薛定谔的猫,具有波粒二象性,当你试图去观察它时它就消失了,当你不去观察它时,它又会出现。当你在测试人员面前赌咒发誓,亲自路演把程序跑一遍的时候,这些bug就会神奇的消失;一旦离开你的骚操作重新回到测试人员手中,这些bug又会突然的出现。这就是开发人员和测试人员互相对天发誓自证清白的尬聊场面。
因为这些幽灵Bug破坏了团队的氛围,伤害了开发和测试人员的感情,从而导致了产品质量下降。 因此非常有必要找到这些bug发生的原因。
试图找到这些具备量子特性的bug发生的原因,通常的手段就是打印日志,因为你很难通过几次思想实验或几次尬聊就能自证清白。
打印日志是查找、分析、定位问题的一个非常有效的手段。尤其对后台程序而言更加重要,后台程序需要长期运行,运行期间会面临各种各样的情况,这些情况包括正常业务逻辑,非正常业务逻辑,甚至是异常情况。我们往往需要在不同情况下将这些发生的事情按时间轴记录下来,从而在系统出现问题或瓶颈时进行回溯分析。
Java中有现成的日志打印类log4j,并将日志定义了4个级别:ERROR、WARN、INFO、DEBUG。通常级别越高输出的日志越少,如果你的后台程序一天就能输出一个G的ERROR日志,那也是非常不容易的事,基本可以告别程序员生涯了,还打啥日志啊?还能让测试人员愉快的工作么?
通常在出现ERROR日志时,我们就需要定位问题,这就需要打印大量的DEBUG或INFO日志来进行问题回溯。这篇文章不是介绍Java如何打印日志,网络上的文章已经很多了。
这里说一下C++在高并发下如何打印日志,这里实现最基本功能(仅做抛砖引玉之用)。通常我们会写一个日志输出函数,如下:
void Logout(const char* pszLogFile, const char* pszLog)
{
// 参数检查
assert(pszLogFile);
assert(pszLog);
if(NULL == pszLogFile || NULL == pszLog)
return;
// 打开日志文件
FILE* pFile = fopen(pszLogFile, "ab+");
if(pFile)
{
// 写日志
fwrite((void*)pszLog, 1, strlen(pszLog), pFile);
fclose(pFile);
}
}
如果是不同级别的日志,可以定义不同日志文件名,你也可以丰富上面的日志函数,增加发生的时间、所在线程ID、所在文件名等辅助信息。
通常情况下这种方式没有问题,通过一次文件IO操作将信息记录下来。但如果是一个后台服务,当高并发发生的时候,问题就会出现了。此时将会有多个线程同时写日志的情况发生,尤其是那些INFO类型的日志,比如记录HTTP请求的request信息,这时你的日志将会成为系统的瓶颈。毕竟大量的文件IO操作也是一种负担,这些IO操作可能要超过你的正常业务逻辑,比如写数据库、网络IO等。
此时我们需要将日志先写入内存块中,当内存写满后在一次性Flush到磁盘中,这样就避免了大量的磁盘IO操作。下面是CFileMem封装类,很简单,里面注释的很详细就不解释了。
头文件.h
#include <windows.h> // for CRITICAL_SECTION
// 缺省内存块大小,大于该值时进行将缓存数据写入磁盘文件
#define SIZE_DEFAULT_MEM (1024*64) // 64K
class CFileMem
{
public:
CFileMem();
virtual ~CFileMem();
public:
// 打开内存文件,dwMemBlockSize为缓存块大小,大于该值时进行一次IO操作
BOOL Open(const char* pszPathFile, DWORD dwMemBlockSize = SIZE_DEFAULT_MEM);
/*
写数据到内存文件,dwFileSize将返回当前磁盘文件的大小,
该值可用于外部判断日志文件是否过大,比如当dwFileSize大于多少M时,可重命名文件
从而避免单个日志文件过大
*/
BOOL Write(const char* pszLog, DWORD& dwFileSize);
BOOL Write(const unsigned char* pData, DWORD dwDataSize, DWORD& dwFileSize);
// 将内存数据写入磁盘
BOOL Flush(DWORD& dwFileSize);
// 关闭内存文件
void Close();
// 重命名文件
void Rename(const char* pszOldPathFile, const char* pszNewPathFile);
protected:
CRITICAL_SECTION m_csMem; // 内存池锁
char m_szPathFile[256]; // 日志文件路径名
char* m_pMemBlock; // 内存块,用于存储文件数据
DWORD m_dwMemBlockSize; // 内存块大小
DWORD m_dwPos; // 内存块的当前位置
};
实现文件.cpp
#include "FileMem.h"
#include <stdio.h>
CFileMem::CFileMem()
{
m_pMemBlock = NULL;
m_dwMemBlockSize = 0;
m_dwPos = 0;
memset(m_szPathFile, 0, 256);
::InitializeCriticalSection(&m_csMem);
}
CFileMem::~CFileMem()
{
Close();
::DeleteCriticalSection(&m_csMem);
}
// 打开内存文件,dwMemBlockSize为缓存块大小,大于该值时进行一次IO操作
BOOL CFileMem::Open(const char* pszPathFile, DWORD dwMemBlockSize)
{
if(!pszPathFile)
return FALSE;
// 关闭之前已打开内存块
Close();
// 保存日志文件全路径名
strcpy(m_szPathFile, pszPathFile);
if(dwMemBlockSize <= 0)
return FALSE;
m_pMemBlock = (char*)malloc(dwMemBlockSize);
if(NULL == m_pMemBlock)
return FALSE;
memset(m_pMemBlock, 0, dwMemBlockSize);
m_dwMemBlockSize = dwMemBlockSize;
m_dwPos = 0;
return TRUE;
}
/*
写数据到内存文件,dwFileSize将返回当前磁盘文件的大小,
该值可用于外部判断日志文件是否过大,比如当dwFileSize大于多少M时,可重命名文件
从而避免单个日志文件过大
*/
BOOL CFileMem::Write(const char* pszLog, DWORD& dwFileSize)
{
return Write((const unsigned char*)pszLog, strlen(pszLog), dwFileSize);
}
BOOL CFileMem::Write(const unsigned char* pData, DWORD dwDataSize, DWORD& dwFileSize)
{
dwFileSize = 0;
if(NULL == pData || 0 == dwDataSize)
return FALSE;
// 如果内部没有开辟缓冲区,则直接写文件
if(NULL == m_pMemBlock || 0 == m_dwMemBlockSize)
{
FILE* pFile = ::fopen(m_szPathFile, "ab+");
if(NULL == pFile)
return FALSE;
::fwrite(pData, 1, dwDataSize, pFile);
// 获取磁盘文件大小
::fseek(pFile, 0L, SEEK_END);
dwFileSize = ::ftell(pFile);
::fclose(pFile);
return TRUE;
}
::EnterCriticalSection(&m_csMem);
// 如果内存块已满,则写入磁盘文件
DWORD dwTotalSize = m_dwPos + dwDataSize;
if(dwTotalSize >= m_dwMemBlockSize)
{
FILE* pFile = ::fopen(m_szPathFile, "ab+");
if(NULL == pFile)
{
::LeaveCriticalSection(&m_csMem);
return FALSE;
}
// 将当前内存中数据写入文件
::fwrite(m_pMemBlock, 1, m_dwPos, pFile);
::fwrite(pData, 1, dwDataSize, pFile);
// 获取磁盘文件大小
::fseek(pFile, 0L, SEEK_END);
dwFileSize = ::ftell(pFile);
::fclose(pFile);
// 清空内存块
memset(m_pMemBlock, 0, m_dwMemBlockSize);
m_dwPos = 0;
}
else
{
// 如果内存未满,将当前数据写入内存
memcpy(m_pMemBlock+m_dwPos, pData, dwDataSize);
m_dwPos += dwDataSize;
}
::LeaveCriticalSection(&m_csMem);
return TRUE;
}
// 将缓冲区的内容写入磁盘
BOOL CFileMem::Flush(DWORD& dwFileSize)
{
// 参数
dwFileSize = 0;
if(NULL == m_pMemBlock || 0 == m_dwMemBlockSize || 0 == m_dwPos)
return TRUE;
::EnterCriticalSection(&m_csMem);
FILE* pFile = ::fopen(m_szPathFile, "ab+");
if(NULL == pFile)
{
::LeaveCriticalSection(&m_csMem);
return FALSE;
}
// 内存数据写入磁盘文件
::fwrite(m_pMemBlock, 1, m_dwPos, pFile);
// 获取磁盘文件大小
::fseek(pFile, 0L, SEEK_END);
dwFileSize = ::ftell(pFile);
::fclose(pFile);
// 清空内存块
memset(m_pMemBlock, 0, m_dwMemBlockSize);
m_dwPos = 0;
::LeaveCriticalSection(&m_csMem);
return TRUE;
}
void CFileMem::Close()
{
// 将内存中文件写入磁盘
DWORD dwFileSize = 0;
Flush(dwFileSize);
// 释放内存块
free(m_pMemBlock);
m_pMemBlock = NULL;
m_dwMemBlockSize = 0;
m_dwPos = 0;
memset(m_szPathFile, 0, 256);
}
// 重命名文件
void CFileMem::Rename(const char* pszOldPathFile, const char* pszNewPathFile)
{
::EnterCriticalSection(&m_csMem);
::rename(pszOldPathFile, pszNewPathFile);
::LeaveCriticalSection(&m_csMem);
}
测试函数:
#include <assert.h>
#include <stdio.h>
#include <time.h> // for Clock
// 传统的日志输出函数
void Logout(const char* pszLogFile, const char* pszLog)
{
// 参数检查
assert(pszLogFile);
assert(pszLog);
if(NULL == pszLogFile || NULL == pszLog)
return;
// 打开日志文件
FILE* pFile = fopen(pszLogFile, "ab+");
if(pFile)
{
// 写日志
fwrite((void*)pszLog, 1, strlen(pszLog), pFile);
fclose(pFile);
}
}
static void TestFileMem()
{
const char* pszLogFile1 = "c:/test1.log";
const char* pszLogInfo = "Hello world\r\n";
int iCount = 10000;
// 循环写日志1万次
// 第一种方式:传统写日志方式
clock_t cStart = clock();
for(int i = 0; i < iCount; i++)
Logout(pszLogFile1, pszLogInfo);
clock_t cEnd = clock();
long lElapsed = cEnd - cStart;
printf("Logout Elpased time %d ms\r\n", lElapsed);
// 第二种方式:使用CFileMem写日志
const char* pszLogFile2 = "c:/test2.log";
CFileMem fm;
DWORD dwFileSize = 0;
fm.Open(pszLogFile2);
cStart = clock();
for(i = 0; i < iCount; i++)
fm.Write(pszLogInfo, dwFileSize);
fm.Close();
cEnd = clock();
lElapsed = cEnd - cStart;
printf("CFileMem Elpased time %d ms\r\n", lElapsed);
}
输出结果:
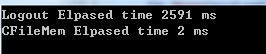
通过测试比较,第二种方式速度更加快速,而且是线程安全的。
我写的“HttpServer:一款Windows平台下基于IOCP模型的高并发轻量级web服务器”,就使用该类进行日志打印,效果不错。
感谢您的阅读!
为何要打印日志?C++在高并发下如何写日志文件(附源码)?的更多相关文章
- 日志组件Log2Net的介绍和使用(附源码开源地址)
Log2Net是一个用于收集日志到数据库或文件的组件,支持.NET和.NetCore平台. 此组件自动收集系统的运行日志(服务器运行情况.在线人数等).异常日志.程序员还可以添加自定义日志. 该组件支 ...
- 多线程高并发编程(12) -- 阻塞算法实现ArrayBlockingQueue源码分析(1)
一.前言 前文探究了非阻塞算法的实现ConcurrentLinkedQueue安全队列,也说明了阻塞算法实现的两种方式,使用一把锁(出队和入队同一把锁ArrayBlockingQueue)和两把锁(出 ...
- 仿酷狗音乐播放器开发日志十九——CTreeNodeUI的bug修复二(附源码)
转载请说明原出处,谢谢 今天本来打算把仿酷狗播放列表的子控件拖动插入功能做一下,但是仔细使用播放列表控件时发现了几个逻辑错误,由于我的播放 列表控件是基于CTreeViewUI和CTreeNodeUI ...
- Android 高仿 频道管理----网易、今日头条、腾讯视频 (可以拖动的GridView)附源码DEMO
距离上次发布(android高仿系列)今日头条 --新闻阅读器 (二) 相关的内容已经半个月了,最近利用空闲时间,把今日头条客户端完善了下.完善的功能一个一个全部实现后,就放整个源码.开发的进度就是按 ...
- 使用sqlserver搭建高可用双机热备的Quartz集群部署【附源码】
一般拿Timer和Quartz相比较的,简直就是对Quartz的侮辱,两者的功能根本就不在一个层级上,如本篇介绍的Quartz强大的序列化机制,可以序列到 sqlserver,mysql,当然还可以在 ...
- .Net高并发解决思路(附源码)
本文如有不对之处,欢迎各位拍砖扶正.另源码在文章最下面,大家下载过后先还原一下nuget包,需要改一下redis的配置,rabbitmq的配置以及Ef的连接字符串.另外使用的是CodeFirst,先u ...
- 2.NetDh框架之简单高效的日志操作类(附源码和示例代码)
前言 NetDh框架适用于C/S.B/S的服务端框架,可用于项目开发和学习.目前包含以下四个模块 1.数据库操作层封装Dapper,支持多种数据库类型.多库实例,简单强大: 此部分具体说明可参考博客: ...
- 基于DevExpress的SpreadsheetControl实现对Excel的打开、预览、保存、另存为、打印(附源码下载)
场景 Winform控件-DevExpress18下载安装注册以及在VS中使用: https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/1 ...
- 使用DevExpress的PdfViewer实现PDF打开、预览、另存为、打印(附源码下载)
场景 Winform控件-DevExpress18下载安装注册以及在VS中使用: https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/1 ...
随机推荐
- bugku--cookie欺骗
打开题目一看,是一串的东西,再看了一下filename发现不对劲了,明显是base64编码,拿去解码一下, 发现是这个,说明是filename,是需要解析的哪个文件名,把index.php编码一下,试 ...
- webpack 快速入门 系列 —— 性能
其他章节请看: webpack 快速入门 系列 性能 本篇主要介绍 webpack 中的一些常用性能,包括热模块替换.source map.oneOf.缓存.tree shaking.代码分割.懒加载 ...
- 关于高校表白App的NABCD项目分析
N(Need,需求) 首先,针对本校男多女少 的具体情况,为广大本校大学生提供一个更加宽广的平台: 其次,针对当前各高校均有校园表白墙的实际情况,各表白墙难以整合在一起,使得信息不够集中的现状,我们小 ...
- LeetCode 887. Super Egg Drop
题目链接:https://leetcode.com/problems/super-egg-drop/ 题意:给你K个鸡蛋以及一栋N层楼的建筑,已知存在某一个楼层F(0<=F<=N),在不高 ...
- uni-app&H5&Android混合开发三 || uni-app调用Android原生方法的三种方式
前言: 关于H5的调用Android原生方法的方式有很多,在该片文章中我主要简单介绍三种与Android原生方法交互的方式. 一.H5+方法调用android原生方法 H5+ Android开发规范官 ...
- 给你的Mac 整个好用的命令行iTerm2 + zsh + oh-my-zsh + powerlevel10k
给你的Mac 整个好用的命令行iTerm2 + zsh + oh-my-zsh + powerlevel10k 介绍 iTerm2 是一个MacOS 下的终端模拟器,和其他的终端本质上没啥大不同.但相 ...
- 使用宝塔配置laravel站点时,遇到open_basedir restriction in effect. 原因与解决方法
今天一位朋友在linux服务器部署thinkphp5的时候PHP报了这个错误,如下: Warning: require(): open_basedir restriction in effect. F ...
- 动态 WebApi 引擎使用教程(3行代码完成动态 WebApi 构建)
目录 什么是 WebApiEngine? 开源地址 使用方法 使用 [ApiBind] 标签让任何方法变成 WebApi 对 API 进行分类 自定义 API 名称 复制特性 为整个类配置 WebAp ...
- CF896D Nephren Runs a Cinema
CF896D Nephren Runs a Cinema 题意 售票员最开始没有纸币,每次来一个顾客可以给她一张.拿走她一张或不操作.求出不出现中途没钱给的情况 \(n\) 名顾客后剩余钱数在 \(l ...
- POJ3190 - 优先队列 贪心
POJ3190 将所有牛从小到大排序然后用优先队列(小根堆)依次记录插入的牛的结束时间,如果插入牛时起始时间大于首元素,ans不增加并弹出首元素. 挺简单的.那么为什么我会写(水)这篇博客呢? #in ...