Spark常用函数讲解之Action操作
RDD:弹性分布式数据集,是一种特殊集合 ‚ 支持多种来源 ‚ 有容错机制 ‚ 可以被缓存 ‚ 支持并行操作,一个RDD代表一个分区里的数据集
RDD有两种操作算子:
Ation(执行):触发Spark作业的运行,真正触发转换算子的计算
本系列主要讲解Spark中常用的函数操作:
1.RDD基本转换
2.键-值RDD转换
3.Action操作篇
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("reduce")
val sc = new SparkContext(conf)
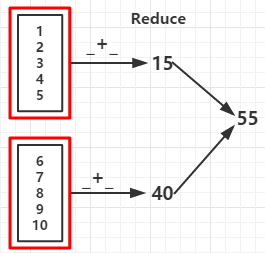
val rdd = sc.parallelize(1 to 10,2)
val reduceRDD = rdd.reduce(_ + _)
val reduceRDD1 = rdd.reduce(_ - _) //如果分区数据为1结果为 -53
val countRDD = rdd.count()
val firstRDD = rdd.first()
val takeRDD = rdd.take(5) //输出前个元素
val topRDD = rdd.top(3) //从高到底输出前三个元素
val takeOrderedRDD = rdd.takeOrdered(3) //按自然顺序从底到高输出前三个元素
println("func +: "+reduceRDD)
println("func -: "+reduceRDD1)
println("count: "+countRDD)
println("first: "+firstRDD)
println("take:")
takeRDD.foreach(x => print(x +" "))
println("\ntop:")
topRDD.foreach(x => print(x +" "))
println("\ntakeOrdered:")
takeOrderedRDD.foreach(x => print(x +" "))
sc.stop
}
func +:
func -: //如果分区数据为1结果为 -53
count:
first:
take: top: takeOrdered:

def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("KVFunc")
val sc = new SparkContext(conf)
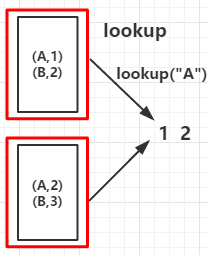
val arr = List(("A", 1), ("B", 2), ("A", 2), ("B", 3))
val rdd = sc.parallelize(arr,2)
val countByKeyRDD = rdd.countByKey()
val collectAsMapRDD = rdd.collectAsMap()
println("countByKey:")
countByKeyRDD.foreach(print)
println("\ncollectAsMap:")
collectAsMapRDD.foreach(print)
sc.stop
}
countByKey:
(B,)(A,)
collectAsMap:
(A,)(B,)

def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("Fold")
val sc = new SparkContext(conf)
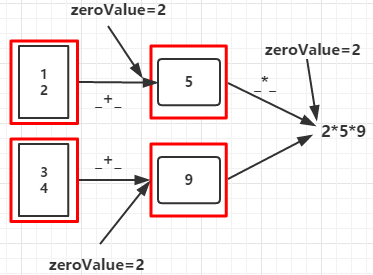
val rdd = sc.parallelize(List(1,2,3,4),2)
val aggregateRDD = rdd.aggregate(2)(_+_,_ * _)
println(aggregateRDD)
sc.stop
}

def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("Fold")
val sc = new SparkContext(conf)
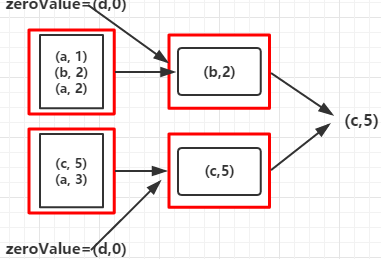
val rdd = sc.parallelize(Array(("a", 1), ("b", 2), ("a", 2), ("c", 5), ("a", 3)), 2)
val foldRDD = rdd.fold(("d", 0))((val1, val2) => { if (val1._2 >= val2._2) val1 else val2
})
println(foldRDD)
}
c,5

Spark常用函数讲解之Action操作的更多相关文章
- Spark常用函数讲解之键值RDD转换
摘要: RDD:弹性分布式数据集,是一种特殊集合 ‚ 支持多种来源 ‚ 有容错机制 ‚ 可以被缓存 ‚ 支持并行操作,一个RDD代表一个分区里的数据集RDD有两种操作算子: Trans ...
- spark 常用函数介绍(python)
以下是个人理解,一切以官网文档为准. http://spark.apache.org/docs/latest/api/python/pyspark.html 在开始之前,我先介绍一下,RDD是什么? ...
- Spark RDD概念学习系列之action操作
不多说,直接上干货! action操作
- Spark常用函数(源码阅读六)
源码层面整理下我们常用的操作RDD数据处理与分析的函数,从而能更好的应用于工作中. 连接Hbase,读取hbase的过程,首先代码如下: def tableInitByTime(sc : SparkC ...
- CI框架常用函数(AR数据库操作的常用函数)
用户手册地址:http://codeigniter.org.cn/user_guide/index.html 1.查询表记录$this->db->select(); //选择查询的字段$t ...
- 四、spark常用函数说明学习
1.parallelize 并行集合,切片数.默认为这个程序所分配到的资源的cpu核的个数. 查看大小:rdd.partitions.size sc.paraliel ...
- Opencv常用函数讲解
1.approxPolyDP(Mat(ps), poly, 5, true);//根据点集,拟合出多边形 2.fillConvexPoly(mask, Mat(ps), Scalar(255));根据 ...
- Spark RDD、DataFrame原理及操作详解
RDD是什么? RDD (resilientdistributed dataset),指的是一个只读的,可分区的分布式数据集,这个数据集的全部或部分可以缓存在内存中,在多次计算间重用. RDD内部可以 ...
- Spark Streaming中的操作函数讲解
Spark Streaming中的操作函数讲解 根据根据Spark官方文档中的描述,在Spark Streaming应用中,一个DStream对象可以调用多种操作,主要分为以下几类 Transform ...
随机推荐
- getInitParameter()
getInitParameter()方法是在GenericServlet接口中新定义的一个方法,用来调用初始化在web.xml中存放的参量.在web.xml配置文件中一个servlet中参量的初始 ...
- Some good iOS questions
这里,我列举了一些在Stackoverflow中一些比较好的关于iOS的问题.大部分我列举的问题都是关于Objective C.所有问题中,我比较喜欢“为什么”这一类型的问题. 问题 1. What’ ...
- Javascript进阶篇——(DOM—认识DOM、ByName、ByTagName)—笔记整理
认识DOM文档对象模型DOM(Document Object Model)定义访问和处理HTML文档的标准方法.DOM 将HTML文档呈现为带有元素.属性和文本的树结构(节点树). 将HTML代码分解 ...
- javascript 模仿 html5 placeholder
<form action="?action=deliver" method="post" class="deliver-form"&g ...
- vs2012快捷键失效解决办法
快速解决vs开发工具快捷键失效,看图
- Android下按钮的使用方法
package com.hangsheng.button; import android.app.Activity; import android.os.Bundle; import android. ...
- 点击推送消息跳转处理(iOS)
当用户点击收到的推送消息时候,我希望打开APP,并且跳转到对应的界面,这就需要在AppDelegate里面对代理方法进行处理. 当用户点击推送消息打开APP的时候会调用 - (BOOL)applica ...
- 整理 C#(同步调用、异步调用、异步回调)
//闲来无事,巩固同步异步方面的知识,以备后用,特整理如下: class Program { static void Main(string[] args) { //同步调用 会阻塞当前线程,一步一步 ...
- C语言中的静态局部变量
代码: 0x601070 0x7ffcf44243fc 0x60106c 0x60106c 0x60106c [hu@localhost test]$ cat test.cpp #include &l ...
- Jlink仿真器下载程序时出现Invalid ROM table!
原因:仿真器时钟设置不对,应该将时间改低一点.