Spark常用函数讲解之键值RDD转换
RDD:弹性分布式数据集,是一种特殊集合 ‚ 支持多种来源 ‚ 有容错机制 ‚ 可以被缓存 ‚ 支持并行操作,一个RDD代表一个分区里的数据集
RDD有两种操作算子:
Ation(执行):触发Spark作业的运行,真正触发转换算子的计算
本系列主要讲解Spark中常用的函数操作:
1.RDD基本转换
2.键-值RDD转换
3.Action操作篇
object MapValues {
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("map")
val sc = new SparkContext(conf)
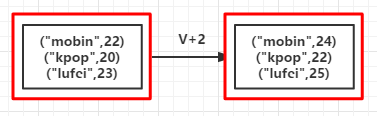
val list = List(("mobin",22),("kpop",20),("lufei",23))
val rdd = sc.parallelize(list)
val mapValuesRDD = rdd.mapValues(_+2)
mapValuesRDD.foreach(println)
}
}
(mobin,)
(kpop,)
(lufei,)

//省略
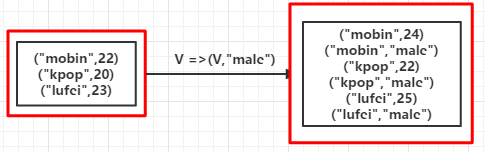
val list = List(("mobin",22),("kpop",20),("lufei",23))
val rdd = sc.parallelize(list)
val mapValuesRDD = rdd.flatMapValues(x => Seq(x,"male"))
mapValuesRDD.foreach(println)
(mobin,)
(mobin,male)
(kpop,)
(kpop,male)
(lufei,)
(lufei,male)
(mobin,List(, male))
(kpop,List(, male))
(lufei,List(, male))

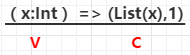





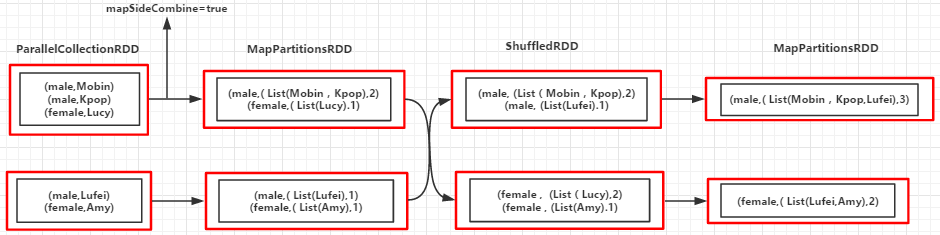
object CombineByKey {
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("combinByKey")
val sc = new SparkContext(conf)
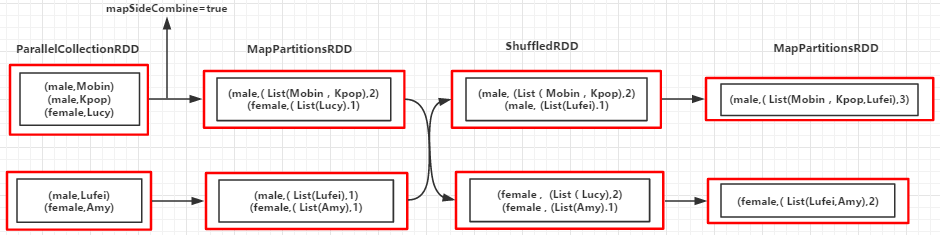
val people = List(("male", "Mobin"), ("male", "Kpop"), ("female", "Lucy"), ("male", "Lufei"), ("female", "Amy"))
val rdd = sc.parallelize(people)
val combinByKeyRDD = rdd.combineByKey(
(x: String) => (List(x), 1),
(peo: (List[String], Int), x : String) => (x :: peo._1, peo._2 + 1),
(sex1: (List[String], Int), sex2: (List[String], Int)) => (sex1._1 ::: sex2._1, sex1._2 + sex2._2))
combinByKeyRDD.foreach(println)
sc.stop()
}
}
(male,(List(Lufei, Kpop, Mobin),))
(female,(List(Amy, Lucy),))
Partition1:
K="male" --> ("male","Mobin") --> createCombiner("Mobin") => peo1 = ( List("Mobin") , )
K="male" --> ("male","Kpop") --> mergeValue(peo1,"Kpop") => peo2 = ( "Kpop" :: peo1_1 , + ) //Key相同调用mergeValue函数对值进行合并
K="female" --> ("female","Lucy") --> createCombiner("Lucy") => peo3 = ( List("Lucy") , ) Partition2:
K="male" --> ("male","Lufei") --> createCombiner("Lufei") => peo4 = ( List("Lufei") , )
K="female" --> ("female","Amy") --> createCombiner("Amy") => peo5 = ( List("Amy") , ) Merger Partition:
K="male" --> mergeCombiners(peo2,peo4) => (List(Lufei,Kpop,Mobin))
K="female" --> mergeCombiners(peo3,peo5) => (List(Amy,Lucy))

//省略
val people = List(("Mobin", 2), ("Mobin", 1), ("Lucy", 2), ("Amy", 1), ("Lucy", 3))
val rdd = sc.parallelize(people)
val foldByKeyRDD = rdd.foldByKey(2)(_+_)
foldByKeyRDD.foreach(println)
(Amy,)
(Mobin,)
(Lucy,)
//省略
val arr = List(("A",3),("A",2),("B",1),("B",3))
val rdd = sc.parallelize(arr)
val reduceByKeyRDD = rdd.reduceByKey(_ +_)
reduceByKeyRDD.foreach(println)
sc.stop
(A,)
(A,)

//省略
val arr = List(("A",1),("B",2),("A",2),("B",3))
val rdd = sc.parallelize(arr)
val groupByKeyRDD = rdd.groupByKey()
groupByKeyRDD.foreach(println)
sc.stop
(B,CompactBuffer(, ))
(A,CompactBuffer(, ))
//省略sc
val arr = List(("A",1),("B",2),("A",2),("B",3))
val rdd = sc.parallelize(arr)
val sortByKeyRDD = rdd.sortByKey()
sortByKeyRDD.foreach(println)
sc.stop
(A,)
(A,)
(B,)
(B,)
//省略
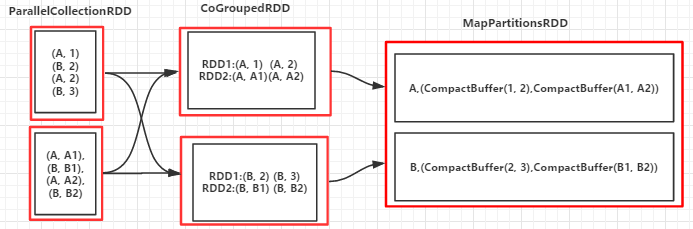
val arr = List(("A", 1), ("B", 2), ("A", 2), ("B", 3))
val arr1 = List(("A", "A1"), ("B", "B1"), ("A", "A2"), ("B", "B2"))
val rdd1 = sc.parallelize(arr, 3)
val rdd2 = sc.parallelize(arr1, 3)
val groupByKeyRDD = rdd1.cogroup(rdd2)
groupByKeyRDD.foreach(println)
sc.stop
(B,(CompactBuffer(, ),CompactBuffer(B1, B2)))
(A,(CompactBuffer(, ),CompactBuffer(A1, A2)))

//省略
val arr = List(("A", 1), ("B", 2), ("A", 2), ("B", 3))
val arr1 = List(("A", "A1"), ("B", "B1"), ("A", "A2"), ("B", "B2"))
val rdd = sc.parallelize(arr, 3)
val rdd1 = sc.parallelize(arr1, 3)
val groupByKeyRDD = rdd.join(rdd1)
groupByKeyRDD.foreach(println)
(B,(,B1))
(B,(,B2))
(B,(,B1))
(B,(,B2)) (A,(,A1))
(A,(,A2))
(A,(,A1))
(A,(,A2)

//省略
val arr = List(("A", 1), ("B", 2), ("A", 2), ("B", 3),("C",1))
val arr1 = List(("A", "A1"), ("B", "B1"), ("A", "A2"), ("B", "B2"))
val rdd = sc.parallelize(arr, 3)
val rdd1 = sc.parallelize(arr1, 3)
val leftOutJoinRDD = rdd.leftOuterJoin(rdd1)
leftOutJoinRDD .foreach(println)
sc.stop
(B,(,Some(B1)))
(B,(,Some(B2)))
(B,(,Some(B1)))
(B,(,Some(B2))) (C,(,None)) (A,(,Some(A1)))
(A,(,Some(A2)))
(A,(,Some(A1)))
(A,(,Some(A2)))
//省略
val arr = List(("A", 1), ("B", 2), ("A", 2), ("B", 3))
val arr1 = List(("A", "A1"), ("B", "B1"), ("A", "A2"), ("B", "B2"),("C","C1"))
val rdd = sc.parallelize(arr, 3)
val rdd1 = sc.parallelize(arr1, 3)
val rightOutJoinRDD = rdd.rightOuterJoin(rdd1)
rightOutJoinRDD.foreach(println)
sc.stop
(B,(Some(),B1))
(B,(Some(),B2))
(B,(Some(),B1))
(B,(Some(),B2)) (C,(None,C1)) (A,(Some(),A1))
(A,(Some(),A2))
(A,(Some(),A1))
(A,(Some(),A2))
Spark常用函数讲解之键值RDD转换的更多相关文章
- Spark常用函数讲解之Action操作
摘要: RDD:弹性分布式数据集,是一种特殊集合 ‚ 支持多种来源 ‚ 有容错机制 ‚ 可以被缓存 ‚ 支持并行操作,一个RDD代表一个分区里的数据集RDD有两种操作算子: Trans ...
- Spark之键值RDD转换(转载)
1.mapValus(fun):对[K,V]型数据中的V值map操作(例1):对每个的的年龄加2 object MapValues { def main(args: Array[String]) { ...
- Spark学习笔记3:键值对操作
键值对RDD通常用来进行聚合计算,Spark为包含键值对类型的RDD提供了一些专有的操作.这些RDD被称为pair RDD.pair RDD提供了并行操作各个键或跨节点重新进行数据分组的操作接口. S ...
- spark 常用函数介绍(python)
以下是个人理解,一切以官网文档为准. http://spark.apache.org/docs/latest/api/python/pyspark.html 在开始之前,我先介绍一下,RDD是什么? ...
- spark入门(三)键值对操作
1 简述 Spark为包含键值对类型的RDD提供了一些专有的操作.这些RDD被称为PairRDD. 2 创建PairRDD 2.1 在sprk中,很多存储键值对的数据在读取时直接返回由其键值对数据组成 ...
- Spark常用函数(源码阅读六)
源码层面整理下我们常用的操作RDD数据处理与分析的函数,从而能更好的应用于工作中. 连接Hbase,读取hbase的过程,首先代码如下: def tableInitByTime(sc : SparkC ...
- 四、spark常用函数说明学习
1.parallelize 并行集合,切片数.默认为这个程序所分配到的资源的cpu核的个数. 查看大小:rdd.partitions.size sc.paraliel ...
- Opencv常用函数讲解
1.approxPolyDP(Mat(ps), poly, 5, true);//根据点集,拟合出多边形 2.fillConvexPoly(mask, Mat(ps), Scalar(255));根据 ...
- Spark函数详解系列之RDD基本转换
摘要: RDD:弹性分布式数据集,是一种特殊集合 ‚ 支持多种来源 ‚ 有容错机制 ‚ 可以被缓存 ‚ 支持并行操作,一个RDD代表一个分区里的数据集 RDD有两种操作算子: ...
随机推荐
- hibernate-4.3.5安装配置
起初照着官方文档配,一直出错,貌似官方的文档时错的,查了非常多资料,综合整理了一个可行的方案,例如以下: 0.1包结构 test.demo test.domain //实体类 test.util// ...
- ibatis使用--SqlMapClient对象
SqlMapClient对象 这个对象是iBatis操作数据库的接口(执行CRUD等操作),它也可以执行事务管理等操作.这个类是我们使用iBATIS的最主要的类.它是线程安全的.通常,将它定义为单例. ...
- C#工厂模式代码实例
此处示例为一个简易计算器工厂模式的实现. 创建类库,名为CalcLib,我把计算功能全部放在这个类库中. 首先,创建一个抽象的计算器算法父类,如下: /// <summary> /// 计 ...
- 支持多QQ登录的软件
支持多QQ登录,批量加好友,批量回复QQ消息,当然也能接收 下载链接:多QQ登录软件
- Curl命令使用方法
Curl是Linux下一个很强大的http命令行工具,其功能十分强大.1) 读取网页$ curl http://www.linuxidc.com2) 保存网页$ curl http://www.lin ...
- document 例子
<!DOCTYPE html> <html> <head> <title></title> <script type="te ...
- StartService与BindService
效果图 MainActivity.java package com.wangzhen.servicedemo; import com.lidroid.xutils.ViewUtils; import ...
- web并发访问的问题
一般的webapplication,可能会遇到这样的问题,你可以这样模拟:用浏览器开一个窗口,选中一条记录,编辑之,但是先不要保存,新开一个浏览器窗口,找到这条记录,删除之,然后再回到第一个窗口点击保 ...
- linux虚拟机centos64位_6.5+VM10安装oracle11g图文详解
注意: vi基本命令:i--编辑状态 退出编辑并保存时先按ESC键,再按符合“:wq”或者":x"即可注意每个步骤时的当前用户,是root还是oracle 以root用户登录虚机 ...
- 图文混排——用表情代替"[文字]"
1.简单设置带属性的字符串 定义一个NSMutableAttributedString带属性的字符串 NSMutableAttributedString *str = [[NSMutableAttri ...