Spark常用函数讲解之Action操作
RDD:弹性分布式数据集,是一种特殊集合 ‚ 支持多种来源 ‚ 有容错机制 ‚ 可以被缓存 ‚ 支持并行操作,一个RDD代表一个分区里的数据集
RDD有两种操作算子:
Ation(执行):触发Spark作业的运行,真正触发转换算子的计算
本系列主要讲解Spark中常用的函数操作:
1.RDD基本转换
2.键-值RDD转换
3.Action操作篇
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("reduce")
val sc = new SparkContext(conf)
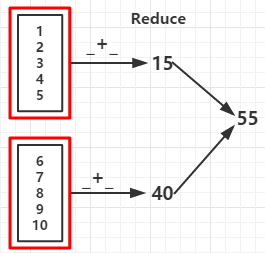
val rdd = sc.parallelize(1 to 10,2)
val reduceRDD = rdd.reduce(_ + _)
val reduceRDD1 = rdd.reduce(_ - _) //如果分区数据为1结果为 -53
val countRDD = rdd.count()
val firstRDD = rdd.first()
val takeRDD = rdd.take(5) //输出前个元素
val topRDD = rdd.top(3) //从高到底输出前三个元素
val takeOrderedRDD = rdd.takeOrdered(3) //按自然顺序从底到高输出前三个元素
println("func +: "+reduceRDD)
println("func -: "+reduceRDD1)
println("count: "+countRDD)
println("first: "+firstRDD)
println("take:")
takeRDD.foreach(x => print(x +" "))
println("\ntop:")
topRDD.foreach(x => print(x +" "))
println("\ntakeOrdered:")
takeOrderedRDD.foreach(x => print(x +" "))
sc.stop
}
func +:
func -: //如果分区数据为1结果为 -53
count:
first:
take: top: takeOrdered:

def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("KVFunc")
val sc = new SparkContext(conf)
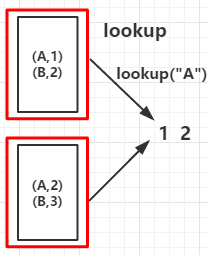
val arr = List(("A", 1), ("B", 2), ("A", 2), ("B", 3))
val rdd = sc.parallelize(arr,2)
val countByKeyRDD = rdd.countByKey()
val collectAsMapRDD = rdd.collectAsMap()
println("countByKey:")
countByKeyRDD.foreach(print)
println("\ncollectAsMap:")
collectAsMapRDD.foreach(print)
sc.stop
}
countByKey:
(B,)(A,)
collectAsMap:
(A,)(B,)

def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("Fold")
val sc = new SparkContext(conf)
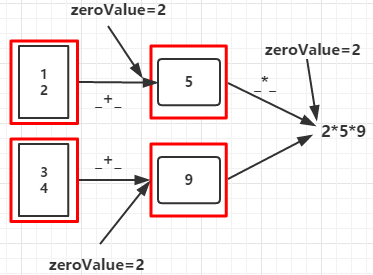
val rdd = sc.parallelize(List(1,2,3,4),2)
val aggregateRDD = rdd.aggregate(2)(_+_,_ * _)
println(aggregateRDD)
sc.stop
}

def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("Fold")
val sc = new SparkContext(conf)
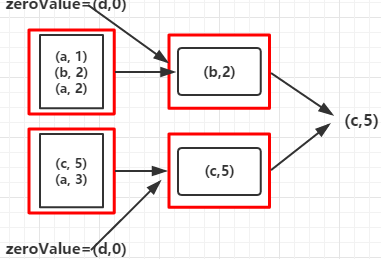
val rdd = sc.parallelize(Array(("a", 1), ("b", 2), ("a", 2), ("c", 5), ("a", 3)), 2)
val foldRDD = rdd.fold(("d", 0))((val1, val2) => { if (val1._2 >= val2._2) val1 else val2
})
println(foldRDD)
}
c,5

Spark常用函数讲解之Action操作的更多相关文章
- Spark常用函数讲解之键值RDD转换
摘要: RDD:弹性分布式数据集,是一种特殊集合 ‚ 支持多种来源 ‚ 有容错机制 ‚ 可以被缓存 ‚ 支持并行操作,一个RDD代表一个分区里的数据集RDD有两种操作算子: Trans ...
- spark 常用函数介绍(python)
以下是个人理解,一切以官网文档为准. http://spark.apache.org/docs/latest/api/python/pyspark.html 在开始之前,我先介绍一下,RDD是什么? ...
- Spark RDD概念学习系列之action操作
不多说,直接上干货! action操作
- Spark常用函数(源码阅读六)
源码层面整理下我们常用的操作RDD数据处理与分析的函数,从而能更好的应用于工作中. 连接Hbase,读取hbase的过程,首先代码如下: def tableInitByTime(sc : SparkC ...
- CI框架常用函数(AR数据库操作的常用函数)
用户手册地址:http://codeigniter.org.cn/user_guide/index.html 1.查询表记录$this->db->select(); //选择查询的字段$t ...
- 四、spark常用函数说明学习
1.parallelize 并行集合,切片数.默认为这个程序所分配到的资源的cpu核的个数. 查看大小:rdd.partitions.size sc.paraliel ...
- Opencv常用函数讲解
1.approxPolyDP(Mat(ps), poly, 5, true);//根据点集,拟合出多边形 2.fillConvexPoly(mask, Mat(ps), Scalar(255));根据 ...
- Spark RDD、DataFrame原理及操作详解
RDD是什么? RDD (resilientdistributed dataset),指的是一个只读的,可分区的分布式数据集,这个数据集的全部或部分可以缓存在内存中,在多次计算间重用. RDD内部可以 ...
- Spark Streaming中的操作函数讲解
Spark Streaming中的操作函数讲解 根据根据Spark官方文档中的描述,在Spark Streaming应用中,一个DStream对象可以调用多种操作,主要分为以下几类 Transform ...
随机推荐
- 使用Gradle构建Android应用内测版本
在开发应用的过程中,有时候需要比较当前线上版本和正在开发中的版本差异,目前的做法只能是在两个不同的设备上面安装线上版本和开发中的版本,因为当前版本在调试过程中会覆盖旧版本.本文通过使用gradle来构 ...
- Hacker(23)----破解常见文件密码
Win7中,office文档.压缩文件等都是常见的文件,这些文档含有重要的信息,即使用户为这些文件设置了密码,黑客也会有办法破解. 一.破解office文档密码 破解office文档密码常用工具是Ad ...
- <.net>委托初探
最近在学<.net深入体验与实战精要>. 今天就来初步讲解下委托. 一句话:委托定义了方法类型,可以将方法当做另一个方法的参数进行传递.委托包涵的只是方法的地址,而不是数据.类似于c指针. ...
- repeater截取字数
<%# Eval("ArticleName").ToString().Length > 14 ? Eval("ArticleName").ToStr ...
- 《第一行代码》学习笔记6-活动Activity(4)
1.SecondActivity不是主活动,故不需要配置标签里的内容. 2.Intent是Android程序中各组件之间进行交互的一种重要方式,一般可被用于 启动活动,启动服务,以及发送广播等.Int ...
- C# 将对象序列化为Json格式
public static string JsonSerializer<T>(T t) { DataContractJsonSerializer ser = new DataContrac ...
- 关于java WEB下载
web.xml配置mapping 页面直接配置路径就可下载 <mime-mapping> <extension>doc</extension> <mim ...
- 初识数据字典【weber出品必属精品】
数据字典结构 有两部分组成: 1. 基表:以$结尾的系统表,在创建数据库的时候,oracle自动创建的表 2. 用户可以访问的视图 数据字典的种类 DICTIONARY:简称DICT,所有的数据字典, ...
- 慕课linux学习笔记(四)常用命令(1)
Root 表示当前登录用户 Localhost 主机名 ~ 当前所在位置(~表示/root) # 超级用户 $ 普通用户 命令 1.pwd 显示当前所在位置 2.ls 查询目录中的内容 -a 显示所有 ...
- JavaScript高级程序设计第14章表单脚本 (学习笔记)
第十四章 表单脚本 1.阻止默认表单提交 1.提交表单数据 1.使用type=submit提交按钮 2.使用submit():方法 注意:当用户点击提交按钮时,会触发submit事件,从而在这里我们有 ...