吴裕雄 python 机器学习——主成份分析PCA降维
# -*- coding: utf-8 -*- import numpy as np
import matplotlib.pyplot as plt from sklearn import datasets,decomposition def load_data():
'''
加载用于降维的数据
'''
# 使用 scikit-learn 自带的 iris 数据集
iris=datasets.load_iris()
return iris.data,iris.target #PCA降维
def test_PCA(*data):
X,y=data
# 使用默认的 n_components
pca=decomposition.PCA(n_components=None)
pca.fit(X)
print('explained variance ratio : %s'% str(pca.explained_variance_ratio_)) # 产生用于降维的数据集
X,y=load_data()
# 调用 test_PCA
test_PCA(X,y)
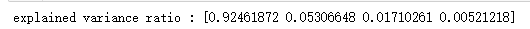
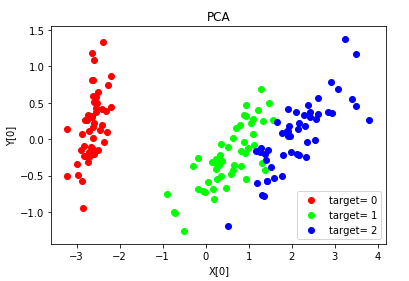
def plot_PCA(*data):
'''
绘制经过 PCA 降维到二维之后的样本点
'''
X,y=data
# 目标维度为2维
pca=decomposition.PCA(n_components=2)
pca.fit(X)
# 原始数据集转换到二维
X_r=pca.transform(X)
###### 绘制二维数据 ########
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
# 颜色集合,不同标记的样本染不同的颜色
colors=((1,0,0),(0,1,0),(0,0,1),(0.5,0.5,0),(0,0.5,0.5),(0.5,0,0.5),(0.4,0.6,0),(0.6,0.4,0),(0,0.6,0.4),(0.5,0.3,0.2))
for label ,color in zip( np.unique(y),colors):
position=y==label
ax.scatter(X_r[position,0],X_r[position,1],label="target= %d"%label,color=color)
ax.set_xlabel("X[0]")
ax.set_ylabel("Y[0]")
ax.legend(loc="best")
ax.set_title("PCA")
plt.show() # 调用 plot_PCA
plot_PCA(X,y)
吴裕雄 python 机器学习——主成份分析PCA降维的更多相关文章
- 吴裕雄 python 机器学习——线性判断分析LinearDiscriminantAnalysis
import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot ...
- 吴裕雄 python 机器学习——等度量映射Isomap降维模型
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datas ...
- 吴裕雄 python 机器学习——局部线性嵌入LLE降维模型
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datas ...
- 主成份分析PCA
Data Mining 主成分分析PCA 降维的必要性 1.多重共线性--预测变量之间相互关联.多重共线性会导致解空间的不稳定,从而可能导致结果的不连贯. 2.高维空间本身具有稀疏性.一维正态分布有6 ...
- 吴裕雄 python 机器学习——超大规模数据集降维IncrementalPCA模型
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datas ...
- 吴裕雄 python 机器学习——分类决策树模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_s ...
- 吴裕雄 python 机器学习——回归决策树模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_s ...
- 吴裕雄 python 机器学习——逻辑回归
import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot ...
- 吴裕雄 python 机器学习——ElasticNet回归
import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot ...
随机推荐
- jfinal 拦截器中判断是否为pjax请求
个人博客 地址:http://www.wenhaofan.com/article/20180926013919 public class PjaxInterceptor implements Inte ...
- 给阿里云主机添加swap分区,解决问题:c++: internal compiler error: Killed (program cc1plus)
前言 今天安装spdlog,一个快速得C++日志库,按照文档步骤,不料出现了一堆错误,像c++: internal compiler error: Killed (program cc1plus)等一 ...
- win10中批量新建文件夹
1.新建一个bat文件,如[批量新建.bat].或者新建txt文件,输入完内容后重命名为bat文件 2.建议用notepad软件打开文件,首先确定编码格式为ANSI编码 (否则最后出现的效果是乱码,不 ...
- Lumen 实现接口 Captcha图片验证码功能
安装 composer require youngyezi/captcha 使用 新版的包已经删除了 session 支持,完全交给业务自由选择存储方式 个人觉得这样更方便来解耦业务,尤其 Lumen ...
- 在MyEclipse中修改文件名出现问题
问题描述:An exception has been caught while processing the refactoring 'Rename Compilation Unit'. 问题原因:项 ...
- Cats and Fish(小猫分鱼吃吱吱吱!)(我觉得是要用贪心的样子!)
炎炎夏日,一堆
- 结合字符串常量池/String.intern()/String Table来谈一下你对java中String的理解
1.字符串常量池 每创建一个字符串常量,JVM会首先检查字符串常量池,如果字符串已经在常量池中存在,那么就返回常量池中的实例引用.如果字符串不在池中,就会实例化一个字符串放到字符串池中.常量池提高了J ...
- redis源码(八)redis-check-aof.c
/* * Copyright (c) 2009-2012, Pieter Noordhuis <pcnoordhuis at gmail dot com> * Copyright (c) ...
- java_获取指定ip的定位
因为自己网站后台做了一个进站ip统计,之前只是获取了ip,这次优化了下,把ip的大致区域弄出来了 废话不多说,进正题 首先要用到几个网络大头的api 淘宝API:http://ip.taobao.co ...
- CF1288F Red-Blue Graph
Link 考虑上下界+费用流. 对于左部点\(u\): 如果颜色为\(B\),连\((s,u,[1,+\infty),0)\). 如果颜色为\(R\),连\((u,t,[1,+\infty),0)\) ...