吴裕雄 python 机器学习——超大规模数据集降维IncrementalPCA模型
# -*- coding: utf-8 -*- import numpy as np
import matplotlib.pyplot as plt from sklearn import datasets,decomposition def load_data():
'''
加载用于降维的数据
'''
# 使用 scikit-learn 自带的 iris 数据集
iris=datasets.load_iris()
return iris.data,iris.target #超大规模数据集降维IncrementalPCA模型
def test_IncrementalPCA(*data):
X,y=data
# 使用默认的 n_components
pca=decomposition.IncrementalPCA(n_components=None,batch_size=10)
pca.partial_fit(X)
aa = pca.transform(X)
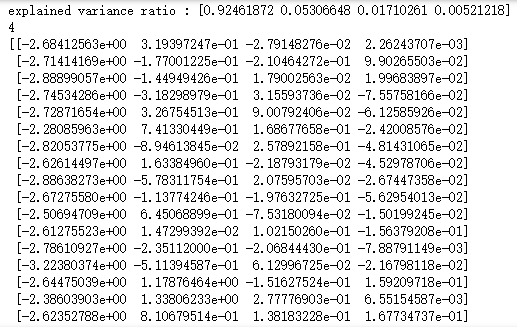
print('explained variance ratio : %s'% str(pca.explained_variance_ratio_))
print(pca.n_components_)
print(aa) # 产生用于降维的数据集
X,y=load_data()
# 调用 test_IncrementalPCA
test_IncrementalPCA(X,y)
吴裕雄 python 机器学习——超大规模数据集降维IncrementalPCA模型的更多相关文章
- 吴裕雄 python 机器学习——K均值聚类KMeans模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
- 吴裕雄 python 机器学习——混合高斯聚类GMM模型
import numpy as np import matplotlib.pyplot as plt from sklearn import mixture from sklearn.metrics ...
- 吴裕雄 python 机器学习——支持向量机线性分类LinearSVC模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- 吴裕雄 python 机器学习——数据预处理流水线Pipeline模型
from sklearn.svm import LinearSVC from sklearn.pipeline import Pipeline from sklearn import neighbor ...
- 吴裕雄 python 机器学习——数据预处理正则化Normalizer模型
from sklearn.preprocessing import Normalizer #数据预处理正则化Normalizer模型 def test_Normalizer(): X=[[1,2,3, ...
- 吴裕雄 python 机器学习——数据预处理标准化MaxAbsScaler模型
from sklearn.preprocessing import MaxAbsScaler #数据预处理标准化MaxAbsScaler模型 def test_MaxAbsScaler(): X=[[ ...
- 吴裕雄 python 机器学习——数据预处理标准化StandardScaler模型
from sklearn.preprocessing import StandardScaler #数据预处理标准化StandardScaler模型 def test_StandardScaler() ...
- 吴裕雄 python 机器学习——数据预处理标准化MinMaxScaler模型
from sklearn.preprocessing import MinMaxScaler #数据预处理标准化MinMaxScaler模型 def test_MinMaxScaler(): X=[[ ...
- 吴裕雄 python 机器学习——数据预处理字典学习模型
from sklearn.decomposition import DictionaryLearning #数据预处理字典学习DictionaryLearning模型 def test_Diction ...
随机推荐
- [Python]python对csv去除重复行 python 2020.2.11
用pandas库的.drop_duplicates函数 代码如下: import shutil import pandas as pd frame=pd.read_csv('E:/bdbk.csv', ...
- pytest参数化 parametrize
pytest.mark.parametrize装饰器可以实现测试用例参数化 parametrizing 1.这里是一个实现检查一定的输入和期望输出测试功能的典型例子 # content of test ...
- Pytest学习7-参数化
在测试过程中,参数化是必不可少的功能,本文就讨论下pytest的几种参数化方法 @pytest.mark.parametrize:参数化测试函数 1.内置的pytest.mark.parametriz ...
- linux 安装 Django
安装django的命令 pip install Django ## 这样运行默认安装的是最新版 备注 根据测试在python3.4基础上安装Django 1.8.9正式版是没有问题的,所以要执行下面命 ...
- liunx 中设置zookeeper 自启动(service zookeeper does not support chkconfig)
在liunx 上设置zookeeper 自启动 1.进入目录 cd /etc/init.d 2.创建一个文件 vim zookeeper 3.编辑zookeepr 文件 连接liunx使用的软件是fi ...
- 《深入理解Java虚拟机》读书笔记九
第十章 早期(编译期)优化 1.Javac的源码与调试 编译期的分类: 前端编译期:把*.java文件转换为*.class文件的过程.例如sun的javac.eclipseJDT中的增量编译器. JI ...
- 杭电oj 2072————统计单词数(java)
problem:统计单词数 思路:利用HashMap的特性——不能反复存储同一个键得数据,所以可以保证map里边儿的元素都是不重复的,存储完毕之后直接输出size就好了 注意事项: 1.利用strin ...
- OrCAD 16.6 自建仿真模型
今天仿真用到一个三极管,NXP的MMBT2222A,OdCAD自带的库里没找到,于是打算学着自己建立一个仿真模型 http://www.nxp.com/documents/spice_model/MM ...
- Binary Number(位运算)
#include<bits/stdc++.h> using namespace std; int n; int getBits1(int n)//求取一个数的二进制形式中1的个数. { i ...
- django--关于部署scrapyd项目报错问题
首先在同步两篇之前写过的博客,可能能用得到 1.https://www.cnblogs.com/lutt/p/10893192.html2.https://www.cnblogs.com/lutt/p ...