用python做推荐系统(一)
一、简介:
推荐系统是最常见的数据分析应用之一,包含淘宝、豆瓣、今日头条都是利用推荐系统来推荐用户内容。推荐算法的方式分为两种,一种是根据用户推荐,一种是根据商品推荐,根据用户推荐主要是找出和这个用户兴趣相近的其他用户,再推荐其他用户也喜欢的东西给这个用户,而根据商品推荐则是根据喜欢这个商品的人也喜欢哪些商品区进行推荐,现在很多是基于这两种算法去进行混合应用。本文会用python演示第一种算法,目标是对用户推荐电影。
二、获取数据:
在movielens上,有许多的用户对电影评价数据,可以至(https://grouplens.org/datasets/movielens/)进行下载,下载完后打开资料夹,有个叫u.data的资料夹,打开会看到以下的数据
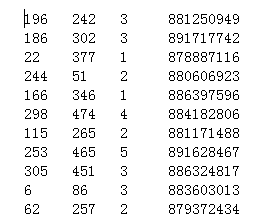
第一列代表用户ID,第二列代表电影的ID,第三列代表评分(1-5分),第四列是时间戳
三、数据预处理
拿到了原始数据后,我们会发现几个问题,就是1、我根本不需要时间戳。2、同一个用户的评价散落在不连续好几行,不好进行分析。这个时候我们就需要进行数据的预处理,首先观察这份数据发现由于每个用户评价的电影都不相同,可能在200部里随机挑了5-10部来评分,所以如果用表格来显示的话会有很多的空格,这个时候KV型数据储存方式就很好用,利用一个键(key)对应一个值(value),这个时候就可以利用python的字典(dict),他可以记录键值对应。举例来说,我用户ID为‘941’的用户,对电影ID为‘763’的评价是3分,那我只需要储存【941】【763】=3这样就可以了,并把user合并,让界面更美观,如下图

可以看到我把用户ID为‘941’评价的电影都列了出来,后面还跟了评分值,这样我后面在做分析的时候读取数据就比较方便了,下面是数据读取到处理的代码
def load_data():
f = open('u.data')
user_list={}
for line in f:
(user,movie,rating,ts) = line.split('\t')
user_list.setdefault(user,{})
user_list[user][movie] = float(rating)
return user_list
user_list就是我们建立用来分析的名单
三、算法:
这边是使用最简单的欧几里得距离算法,简单来说就是将两人对同一部电影的评价相减平方再开根号,比如A看了蝙蝠侠给了5分,B看了给了5分,但C看了给分,AB距离是0, AC距离是2,可以得知A和B的喜好比较相近,当然现在推荐系统算法很多,这边只是挑了一个比较简单的算法,下面是算法的代码
def calculate():
list = load_data()
user_diff = {}
for movies in list['']:
for people in list.keys():
user_diff.setdefault(people,{})
for item in list[people].keys():
if item == movies:
diff = sqrt(pow(list[''][movies] - list[people][item],2))
user_diff[people][item] = diff
return user_diff
这边挑了其中一位ID为7的用户,我的任务是帮他找出他可能会感兴趣的电影,所以先计算所有用户跟7的距离,由于7跟其他用户都看了不同的电影,所以要先找出共同看过的电影再将所有电影的距离列出来。
接下来再把所有电影的距离取平均值,由于我们想知道的是相似度,相似度与平均值成反比,所以我们将距离倒过来就是相似度,另外为了让相似度这个数介于0~1,所以用了1/(1+距离)这个算法,以下为代码
def people_rating():
user_diff = calculate()
rating = {}
for people in user_diff.keys():
rating.setdefault(people,{})
a = 0
b = 0
for score in user_diff[people].values():
a+=score
b+=1
rating[people] = float(1/(1+(a/b)))
return rating
可以看到虽然代码有点丑,不过还是可以跑出个结果,下面就是结果,可以看到跟所有用户的相似度,可以看到跟ID为12的用户相似度为0.58, 跟ID为258的用户相似度为0.333

现在就是要从这里面找出几个相似度比较高的用户,也很简单,利用sort排个序,再选出前五个,下面为代码
def top_list():
list = people_rating()
items = list.items()
top = [[v[1],v[0]] for v in items]
top.sort(reverse=True)
print(top[0:5])
下面为结果

可以看到第一名就是他自己,然后547和384也和他非常契合,不过45名的相似度就下降的非常的快,现在我们来检视547跟384的菜单吧

我们先来验证一下547跟384跟我们7号用户的相似度为什么这么高,下面代码可以找出547跟7号用户共同看过的电影跟评分
list = load_data()
for k,v in list[''].items():
for kk,vv in list[''].items():
if k == kk:
print(k,v,kk,vv)
跑出来的结果如下
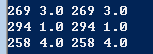
原来他们只共同看了三部电影,给的评分还一样,所以距离才为0
再用同样方法来看384跟7号
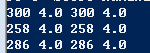
可以看到他们也是刚好看了3部一样的电影,给的分数也是一样,有趣的事他们三个都看了ID为258的电影,也都给了4分
接下来就是最后一步了,我们要找出547和384看过但7号没看过的电影,再从里面找出评分高的推荐给7号,下面为代码
def find_rec():
rec_list = top_list()
first = rec_list[1][1]
second = rec_list[2][1]
all_list = load_data()
for k,v in all_list[first].items():
if k not in all_list[''].keys() and v == 5:
print (k) for k,v in all_list[second].items():
if k not in all_list[''].keys() and v == 5:
print (k)
最后跑出来的结果为
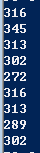
以上为547跟384的推荐名单,可以看到316/302/313都是两人共同推荐,代表这三部片应该是很好看,所以如果要推荐给7号用户的话可以选择这三片来推荐。
四、总结
在演练的过程里面我们可以看出这个算法的许多缺点,例如最高分的其实是因为他们共同看过的电影少,分数又刚好相同,很难说明这就是有共同的兴趣,然后相似度的落差太大,前两名都是1,三四名就掉到了0.75,可见三四名应该是与7号共同看过4部电影,但有其中一部的评分差了一分,导致分数骤降,而大部分的用户都集中在0.3-0,5之间,分数曲线极度不平滑。虽然有这些缺点,但这些算出来的推荐结果还是有代表了一定的意义,至少可以代表是与7号用户品味相似的人给出的高分电影,而7号尚未给过评分。
用python做推荐系统(一)的更多相关文章
- 用python做推荐系统(二)
一.简介 继上一篇基于用户的推荐算法,这一篇是要基于商品的,基于用户的好处是可以根据用户的评价记录找出跟他兴趣相似的用户,再推荐这些用户也喜欢的电影,但是万一这个用户是新用户呢?或是他还没有对任何电影 ...
- What exactly can you do with Python? Here are Python’s 3 main applications._你能用Python做什么?下面是Python的3个主要应用程序。
原文链接 Github地址 一.陈述 1,我到底能用Python做什么? 我观察注意到Python三个主要流行的应用: 网站开发: 数据科学——包括机器学习,数据分析和数据可视化: 做脚本语言. 二. ...
- 使用python做科学计算
这里总结一个guide,主要针对刚开始做数据挖掘和数据分析的同学 说道统计分析工具你一定想到像excel,spss,sas,matlab以及R语言.R语言是这里面比较火的,它的强项是强大的绘图功能以及 ...
- 12岁的少年教你用Python做小游戏
首页 资讯 文章 频道 资源 小组 相亲 登录 注册 首页 最新文章 经典回顾 开发 设计 IT技术 职场 业界 极客 创业 访谈 在国外 - 导航条 - 首页 最新文章 经典回顾 开发 ...
- [原创博文] 用Python做统计分析 (Scipy.stats的文档)
[转自] 用Python做统计分析 (Scipy.stats的文档) 对scipy.stats的详细介绍: 这个文档说了以下内容,对python如何做统计分析感兴趣的人可以看看,毕竟Python的库也 ...
- 这几天有django和python做了一个多用户博客系统(可选择模板)
这几天有django和python做了一个多用户博客系统(可选择模板) 没完成,先分享下 断断续续2周时间吧,用django做了一个多用户博客系统,现在还没有做完,做分享下,以后等完善了再慢慢说 做的 ...
- 用python做中文自然语言预处理
这篇博客根据中文自然语言预处理的步骤分成几个板块.以做LDA实验为例,在处理数据之前,会写一个类似于实验报告的东西,用来指导做实验,OK,举例: 一,实验数据预处理(python,结巴分词)1.对于爬 ...
- 《用Python做HTTP接口测试》学习感悟
机缘巧合之下,报名参加了阿奎老师发布在"好班长"的课程<用Python做HTTP接口测试>,报名费:15rmb,不到一杯咖啡钱,目前为止的状态:坚定不移的跟下去,自学+ ...
- 使用Python做简单的字符串匹配
由于需要在半结构化的文本数据中提取一些特定格式的字段.数据辅助挖掘分析工作,以往都是使用Matlab工具进行结构化数据处理的建模,matlab擅长矩阵处理.结构化数据的计算,Python具有与matl ...
随机推荐
- nio FileChannel中文乱码问题
最近用nio读取文件时,英文正常,读取中文时会出现乱码,经查可以用Charset类来解决: 代码如下: package com.example.demo; import java.io.FileNot ...
- 微信小程序 view中的image水平垂直居中
当 display: flex 配合 justify-content: center 使用时可以让view水平居中 而配合 align-items: center 用时可以实现垂直居中效果 .card ...
- log4js的简单配置
js记录日志工具log4js,参数请参考官网文档https://log4js-node.github.io/log4js-node/index.html const log4js = require( ...
- Codeforces Round #185 (Div. 1 + Div. 2)
A. Whose sentence is it? 模拟. B. Archer \[pro=\frac{a}{b}+(1-\frac{a}{b})(1-\frac{c}{d})\frac{a}{b}+( ...
- H3C PPP会话流程
- SpringSecurity登录原理(源码级讲解)
一.简单叙述 首先会进入UsernamePasswordAuthenticationFilter并且设置权限为null和是否授权为false,然后进入ProviderManager查找支持Userna ...
- CentOS yum有时出现“Could not retrieve mirrorlist ”的解决办法——resolv.conf的配置
国内服务器在运行命令yum -y install wget的时候,出现: Could not retrieve mirrorlist http://mirrorlist.centos.org/?rel ...
- springboot-aop日志打印
package com.cinc.ecmp.client; import com.cinc.ecmp.enums.BackResultEnum; import com.cinc.ecmp.except ...
- Online Classification
Another challenging trend in Internet evolution is the tremendous growth of the infrastructure in ev ...
- dotnet 控制台读写 Sqlite 提示 no such table 找不到文件
在使用 dotnet 读写 Sqlite 可以通过 EF Core 的方法,但是在 EF Core 创建的数据库可能和读写的数据库不是相同的文件 在我运行代码的时候发现在通过迁移创建数据库,创建的文件 ...