Scrapy-Redis分布式策略
Scrapy-Redis分布式策略
原理图:
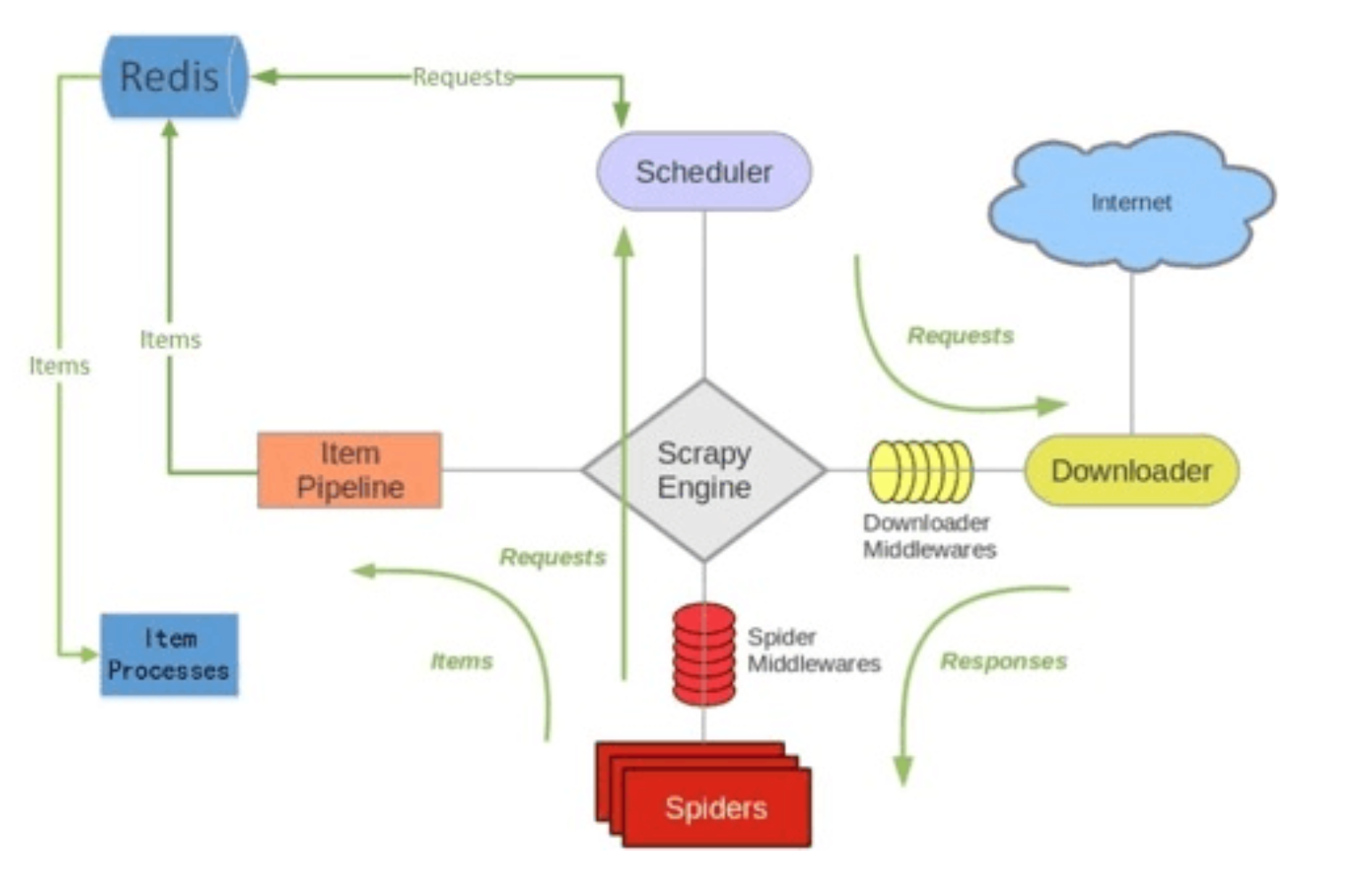
假设有四台电脑:Windows 10、Mac OS X、Ubuntu 16.04、CentOS 7.2,任意一台电脑都可以作为 Master端 或 Slaver端,比如:
Master端(核心服务器) :使用 Windows 10,搭建一个Redis数据库,不负责爬取,只负责url指纹判重、Request的分配,以及数据的存储
Slaver端(爬虫程序执行端) :使用 Mac OS X 、Ubuntu 16.04、CentOS 7.2,负责执行爬虫程序,运行过程中提交新的Request给Master
首先Slaver端从Master端拿任务(Request、url)进行数据抓取,Slaver抓取数据的同时,产生新任务的Request便提交给 Master 处理;
Master端只有一个Redis数据库,负责将未处理的Request去重和任务分配,将处理后的Request加入待爬队列,并且存储爬取的数据。
Scrapy-Redis默认使用的就是这种策略,我们实现起来很简单,因为任务调度等工作Scrapy-Redis都已经帮我们做好了,我们只需要继承RedisSpider、指定redis_key就行了。
缺点是,Scrapy-Redis调度的任务是Request对象,里面信息量比较大(不仅包含url,还有callback函数、headers等信息),可能导致的结果就是会降低爬虫速度、而且会占用Redis大量的存储空间,所以如果要保证效率,那么就需要一定硬件水平。
环境准备
安装scrapy
pip install scrapy
安装scrapy-redis
pip install scrapy-redis
安装redis
windows版redis软件下载
密码:oopq
创建项目
scrapy startproject 项目名称
拉勾网实战
向原有settings.py文件中添加
# url指纹过滤器
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 设置爬虫是否可以中断
SCHEDULER_PERSIST = True # 设置请求队列类型
# SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue" # 按优先级入队列
# SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderQueue" # 按照队列模式先进先出
SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderStack" # 按照栈进行请求的调度先进后出 # 配置redis管道文件,权重数字相对最大
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 999, # redis管道文件,自动把数据加载到redis
} # redis 连接配置
REDIS_HOST = '127.0.0.1'
REDIS_PORT = 6379
REDIS_PARAMS = {
'password' : '', # 密码
'db' : 1 # 指定使用哪个数据库
}
并修改settings.py文件ROBOTSTXT_OBEY = False
Spider文件
本爬虫实现了将所有爬虫请求获取的数据写入到Redis服务器中
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy_redis.spiders import RedisCrawlSpider
from scr_redis.items import LaGouItem
import re
import time
from datetime import datetime
from datetime import timedelta class BaiduSpider(RedisCrawlSpider): #继承RedisCrawlSpider 类
name = 'lagou'
allowed_domains = ['lagou.com']
# start_urls = ['http://www.baidu.com/']
redis_key = 'start_url' #设置redis键名启动 rules = (
# Rule(LinkExtractor(allow=r''), callback='parse_item', follow=True),
# #搜索
Rule(LinkExtractor(allow=(r'lagou.com/jobs/list_',), tags=('form',), attrs=('action',)), follow=True),
# #公司招聘
Rule(LinkExtractor(allow=(r'lagou\.com/gongsi/',), tags=('a',), attrs=('href',)), follow=True),
# 公司列表
Rule(LinkExtractor(allow=(r'/gongsi/j\d+\.html',), tags=('a',), attrs=('href',)), follow=True),
# 校园招聘
Rule(LinkExtractor(allow=(r'xiaoyuan\.lagou\.com',), tags=('a',), attrs=('href',)), follow=True),
# 匹配校园分类
Rule(LinkExtractor(allow=(r'isSchoolJob',), tags=('a',), attrs=('href',)), follow=True),
# # 详情页
Rule(LinkExtractor(allow=(r'jobs/\d+\.html',), tags=('a',), attrs=('href',)), callback='parse_item',
follow=False),
) num_pattern = re.compile(r'\d+') # 提取数字正则
custom_settings = {
'DEFAULT_REQUEST_HEADERS' : {
"Host": "www.lagou.com",
"Connection": "keep-alive",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36",
"Content-type": "application/json;charset=utf-8",
"Accept": "*/*",
"Referer": "https://www.lagou.com",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cookie": "user_trace_token=20171116192426-b45997e2-cac0-11e7-98fd-5254005c3644; LGUID=20171116192426-b4599a6d-cac0-11e7-98fd-5254005c3644; index_location_city=%E5%85%A8%E5%9B%BD; JSESSIONID=ABAAABAAAGFABEFC0E3267F681504E5726030548F107348; _gat=1; X_HTTP_TOKEN=d8b7e352a862bb108b4fd1b63f7d11a7; _gid=GA1.2.1718159851.1510831466; _ga=GA1.2.106845767.1510831466; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1510836765,1510836769,1510837049,1510838482; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1510839167; LGSID=20171116204415-da8c7971-cacb-11e7-930c-525400f775ce; LGRID=20171116213247-a2658795-cad2-11e7-9360-525400f775ce",
},
'COOKIES_ENABLED' : False,
'CONCURRENT_REQUESTS' : 5,
} def parse_item(self, response):
item = LaGouItem()
title = response.css('span.name::text').extract()[0]
url = response.url
spans = response.xpath('//dd[@class="job_request"]//span')
salary = spans[0].css('span::text').extract()[0] #薪资
city =self.splits(spans[1].css('span::text').extract()[0])#工作城市
start,end= self.asks(self.splits(spans[2].css('span::text').extract()[0] ))#经验
edu = self.splits(spans[3].css("span::text").extract()[0] ) #学历
job_type = spans[4].css('span::text').extract()[0] #工作类型 label = "-".join(response.xpath('//ul[@class="position-label clearfix"]//li/text()').extract()) #标签
publish_time =self.times(response.xpath('//p[@class="publish_time"]//text()').extract()[0].strip('\xa0 发布于拉勾网')) #发布时间
tempy = response.xpath('//dd[@class="job-advantage"]//p/text()').extract()[0] #在职业诱惑
discription =''.join([''.join(i.split()) for i in response.xpath('//dd[@class="job_bt"]//div//text()').extract()]) #岗位职责
addr = '-'.join(response.xpath('//div[@class="work_addr"]//a/text()').extract()[:-1])
address = ''.join( ''.join(i.split()) for i in response.xpath('//div[@class="work_addr"]/text()').extract())
loction= addr+address #详细工作地址 #装载数据
item["title"] = title
item["url"] = url
item["salary"] = salary
item["city"] = city
item["start"] = start
item["end"] = end
item["edu"] = edu
item["job_type"] = job_type
item["label"] = label
item["publish_time"] = publish_time
item["tempy"] = tempy
item["discription"] = discription
item["loction"] = loction
return item #去斜杠
def splits(self,value):
result =value.strip('/')
return result def asks(self,value):
if '不限' in value:
start = 0
end = 0
elif '以下' in value :
res = self.num_pattern.search(value)
start = res.group()
end = res.group()
else:
res = self.num_pattern.findall(value)
start = res[0]
end = res[1]
return start,end
#统一日期格式
def times(self,value):
if ':' in value:
times=datetime.now().strftime('%Y-%m-%d')
elif '天前' in value:
res = self.num_pattern.search(value).group()
times = (datetime.now() - timedelta(days=int(res))).strftime('%Y-%m-%d')
else :
times = value
return times
在项目同级目录下创建main.py文件,用来启用爬虫
from scrapy.cmdline import execute
import os
os.chdir('scr_redis/spiders')
# execute('scrapy crawl baidu'.split()) #原启动方式
execute('scrapy runspider lagou.py'.split())
item.py文件
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class ScrRedisItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass class LaGouItem(scrapy.Item):
title = scrapy.Field()
url = scrapy.Field()
salary = scrapy.Field()
city = scrapy.Field()
start = scrapy.Field()
end = scrapy.Field()
edu = scrapy.Field()
job_type = scrapy.Field()
label = scrapy.Field()
publish_time = scrapy.Field()
tempy = scrapy.Field()
discription = scrapy.Field()
loction = scrapy.Field()
在项目目录下创建做持久化保存的文件
本文件实现了将写入redis的数据读取出来保存到mysql数据库
# -*- coding: utf-8 -*-
import json
import redis # pip install redis
import pymysql def main():
# 指定redis数据库信息
rediscli = redis.StrictRedis(host='127.0.0.1', port = 6379,db = 1,password=123456)
# 指定mysql数据库
mysqlcli = pymysql.connect(host='127.0.0.1', user='root', passwd='', db='neihan', charset='utf8') # 无限循环
while True:
source, data = rediscli.blpop(["lagou:items"]) # 从redis里提取数据 item = json.loads(data.decode('utf-8')) # 把 json转字典
try:
# 使用execute方法执行SQL INSERT语句
sql = "insert into lagou(title,url,salary,city,start,end,edu,job_type,label,publish_time,tempy,discription,loction) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
data =[item["title"], item['url'], item["salary"], item["city"], item["start"], item["end"], item["edu"],item["job_type"], item["label"], item["publish_time"], item["tempy"], item["discription"],item["loction"]]
# 使用cursor()方法获取操作游标
cur = mysqlcli.cursor()
cur.execute(sql,data)
# 提交sql事务
mysqlcli.commit()
#关闭本次操作
cur.close()
print ("插入 %s" % item['title'])
except pymysql.Error as e:
# 插入失败则将主键自增设置为1,否则插入数据失败id也会自增,就会出现主键增长不连续的情况
cur.execute('alter table haowaiauto_increment=1')
mysqlcli.rollback()
print ("插入错误" ,str(e))
if __name__ == '__main__':
main()
Scrapy-Redis分布式策略的更多相关文章
- 爬虫--scrapy+redis分布式爬取58同城北京全站租房数据
作业需求: 1.基于Spider或者CrawlSpider进行租房信息的爬取 2.本机搭建分布式环境对租房信息进行爬取 3.搭建多台机器的分布式环境,多台机器同时进行租房数据爬取 建议:用Pychar ...
- scrapy基础知识之 Scrapy-Redis分布式策略:
Scrapy-Redis分布式策略: 假设有四台电脑:Windows 10.Mac OS X.Ubuntu 16.04.CentOS 7.2,任意一台电脑都可以作为 Master端 或 Slaver端 ...
- Redis分布式集群几点说道
原文地址:http://www.cnblogs.com/verrion/p/redis_structure_type_selection.html Redis分布式集群几点说道 Redis数据量日益 ...
- 基于redis分布式缓存实现(新浪微博案例)
第一:Redis 是什么? Redis是基于内存.可持久化的日志型.Key-Value数据库 高性能存储系统,并提供多种语言的API. 第二:出现背景 数据结构(Data Structure)需求越来 ...
- 一致性Hash算法在Redis分布式中的使用
由于redis是单点,但是项目中不可避免的会使用多台Redis缓存服务器,那么怎么把缓存的Key均匀的映射到多台Redis服务器上,且随着缓存服务器的增加或减少时做到最小化的减少缓存Key的命中率呢? ...
- 基于redis分布式缓存实现
Redis的复制功能是完全建立在之前我们讨论过的基 于内存快照的持久化策略基础上的,也就是说无论你的持久化策略选择的是什么,只要用到了Redis的复制功能,就一定会有内存快照发生,那么首先要注意你 的 ...
- Redis分布式锁
Redis分布式锁 分布式锁是许多环境中非常有用的原语,其中不同的进程必须以相互排斥的方式与共享资源一起运行. 有许多图书馆和博客文章描述了如何使用Redis实现DLM(分布式锁管理器),但是每个库都 ...
- springboot+redis分布式锁-模拟抢单
本篇内容主要讲解的是redis分布式锁,这个在各大厂面试几乎都是必备的,下面结合模拟抢单的场景来使用她:本篇不涉及到的redis环境搭建,快速搭建个人测试环境,这里建议使用docker:本篇内容节点如 ...
- Redis 分布式缓存 Java 框架
为什么要在 Java 分布式应用程序中使用缓存? 在提高应用程序速度和性能上,每一毫秒都很重要.根据谷歌的一项研究,假如一个网站在3秒钟或更短时间内没有加载成功,会有 53% 的手机用户会离开. 缓存 ...
随机推荐
- CSS----学习2
CSS2属性 文本 1 水平对齐方式 text-align:left/right/center 也可以让img.input等有水平方向的对齐方式 2 垂直对齐方式 vertical-align:top ...
- lunux开放80端口(本地访问不了linux文件可能是这个原因)
/sbin/iptables -I INPUT -p tcp --dport 80 -j ACCEPT #开启80端口 /etc/rc.d/init.d/iptables save #保存配置 / ...
- MySql介绍
MySql介绍 标签(空格分隔): MySql MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗下公司.MySQL 最流行的关系型数据库管理系统,在 ...
- pycharm破解版
- elastic search 查询
eelastic search主要有两种查询方式,一种是查询字符串,一种是请求体(json格式)查询. 查询字符串: 查询字符串的功能相对简单,使用容易. 比如GET http://localhost ...
- java面试题:网络通信
网络分层 Q:OSI网络七层模型. Http Q:http协议的状态码有哪些?含义是什么? 200,服务器已成功处理了请求. 302,重定向. 400,错误请求. 401,未授权,请求要求身份验证. ...
- poj1984(带权并查集)
题目链接:http://poj.org/problem?id=1984 题意:给定n个farm,m条边连接farm,k组询问,询问根据前t3条边求t1到t2的曼哈顿距离,若不可求则输出-1. 思路:类 ...
- Date 时间 日期 常用方法函数
转载自https://www.cnblogs.com/lcngu/p/5154834.html 一.java.util.Date对象用来表示时间,基本方法如下: Date mDate = new Da ...
- laravel中的模型关联之(一对多)
一对多 一对多就相当于,一个用户有多篇文章,这多篇文章都对应一个用户 这是一张文章表,一个用户有多篇文章,这里是在用户模型里面获取用户的所有文章, 第二个参数就是获取的模型文章表(post)里面的用户 ...
- spring-mvc.xml 和 application-context.xml的区别
转自:https://www.cnblogs.com/binlin1987/p/7053016.html application-context.xml是全局的,应用于多个serverlet,配合li ...