CS229 2.深入梯度下降(Gradient Descent)算法
1 问题的引出
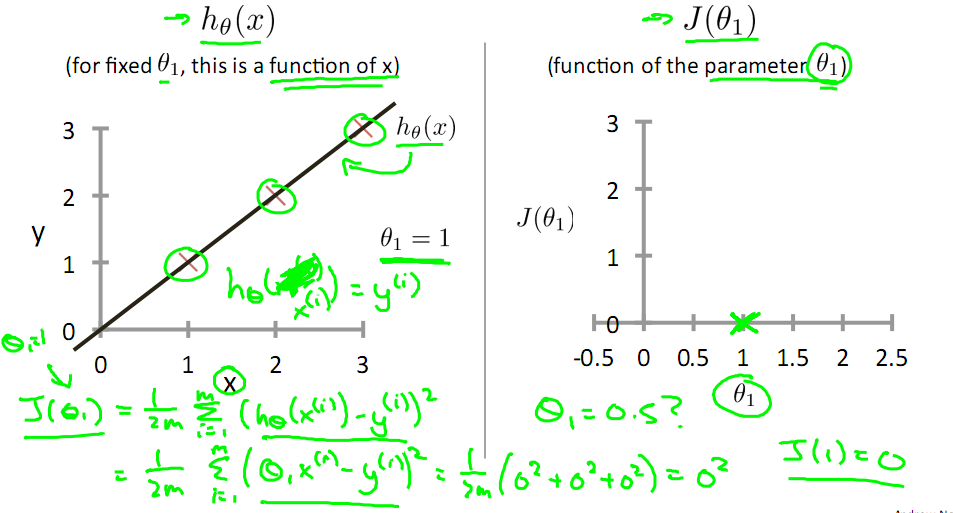
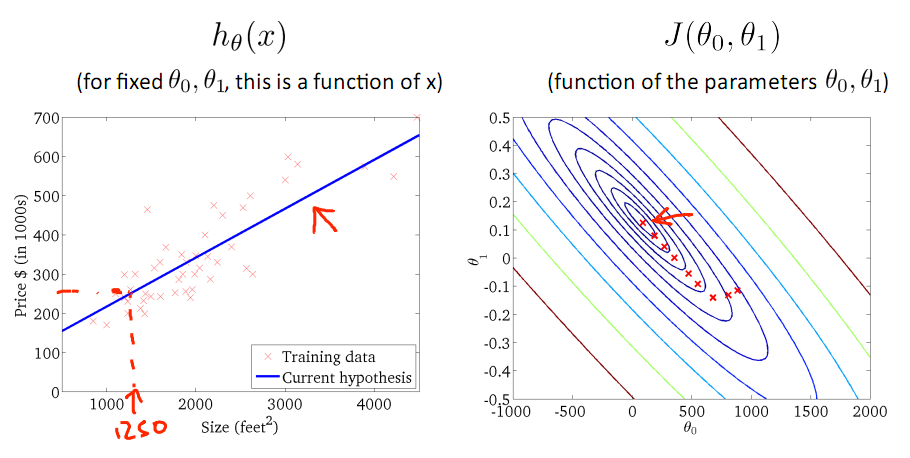
对于上篇中讲到的线性回归,先化一个为一个特征θ1,θ0为偏置项,最后列出的误差函数如下图所示:

手动求解
目标是优化J(θ1),得到其最小化,下图中的×为y(i),下面给出TrainSet,{(1,1),(2,2),(3,3)}通过手动寻找来找到最优解,由图可见当θ1取1时,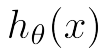 与y(i)完全重合,J(θ1) = 0
与y(i)完全重合,J(θ1) = 0
下面是θ1的取值与对应的J(θ1)变化情况
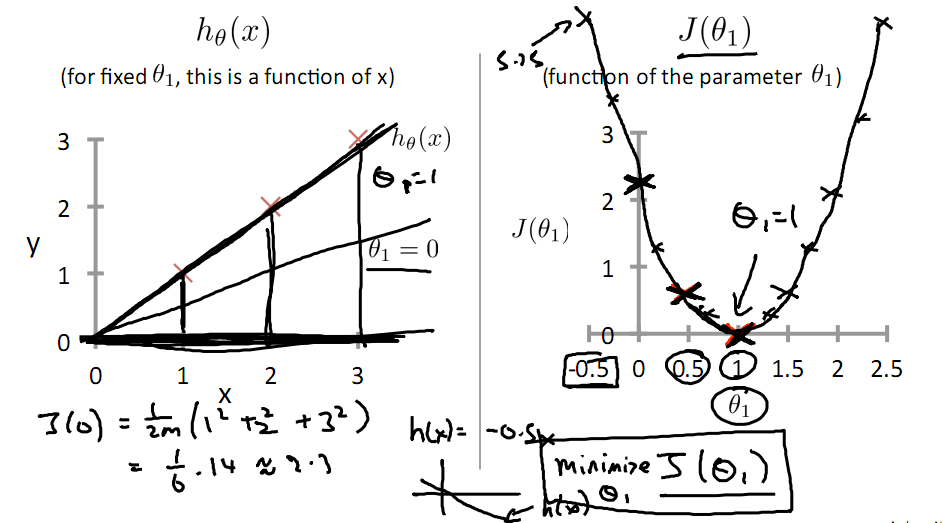
由此可见,最优解即为0,现在来看通过梯度下降法来自动找到最优解,对于上述待优化问题,下图给出其三维图像,可见要找到最优解,就要不断向下探索,使得J(θ)最小即可。
2 梯度下降的几何形式
下图为梯度下降的目的,找到J(θ)的最小值。
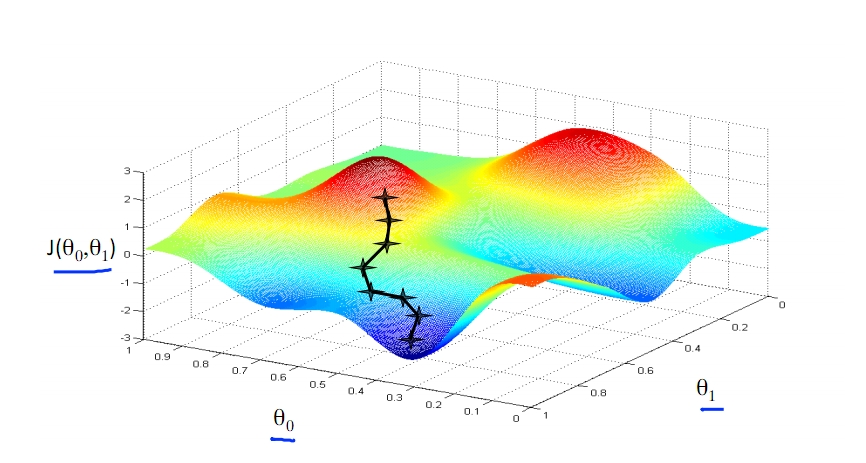
其实,J(θ)的真正图形是类似下面这样的,因为其是一个凸函数,只有一个全局最优解,所以不必担心像上图一样找到局部最优解

直到了要找到图形中的最小值之后,下面介绍自动求解最小值的办法,这就是梯度下降法

对参数向量θ中的每个分量θj,迭代减去速率因子a* (dJ(θ)/dθj)即可,后边一项为J(θ)关于θj的偏导数
3 梯度下降的原理
导数的概念
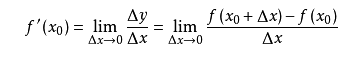
由公式可见,对点x0的导数反映了函数在点x0处的瞬时变化速率,或者叫在点x0处的斜度。推广到多维函数中,就有了梯度的概念,梯度是一个向量组合,反映了多维图形中变化速率最快的方向。
下图展示了对单个特征θ1的直观图形,起始时导数为正,θ1减小后并以新的θ1为基点重新求导,一直迭代就会找到最小的θ1,若导数为负时,θ1的就会不断增到,直到找到使损失函数最小的值。
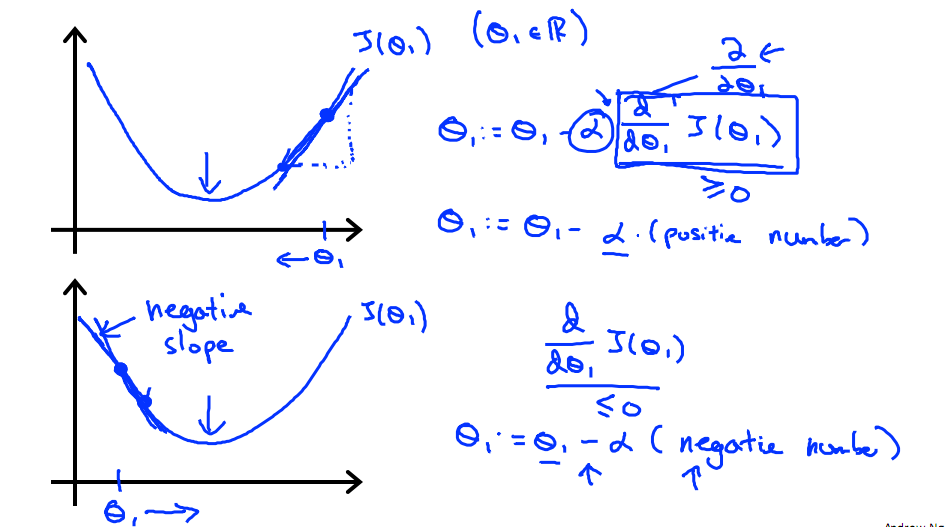
有一点需要注意的是步长a的大小,如果a太小,则会迭代很多次才找到最优解,若a太大,可能跳过最优,从而找不到最优解。
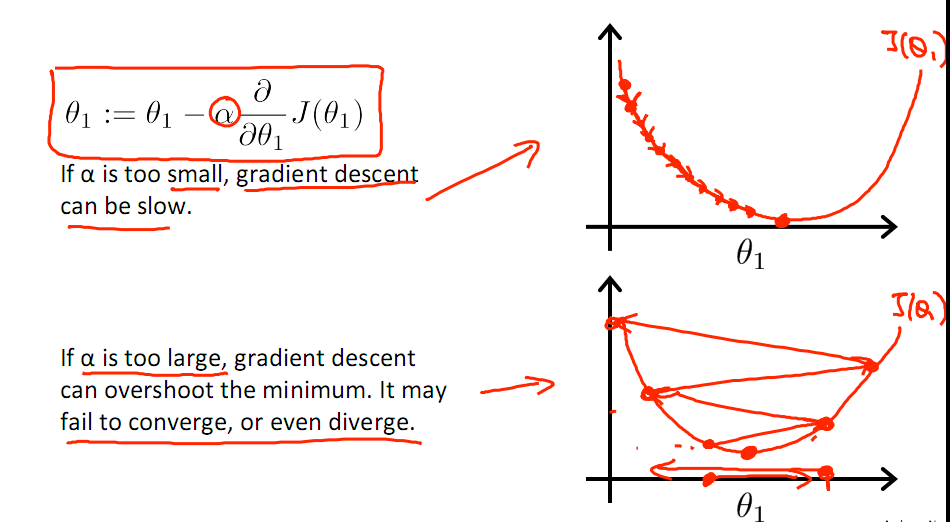
另外,在不断迭代的过程中,梯度值会不断变小,所以θ1的变化速度也会越来越慢,所以不需要使速率a的值越来越小
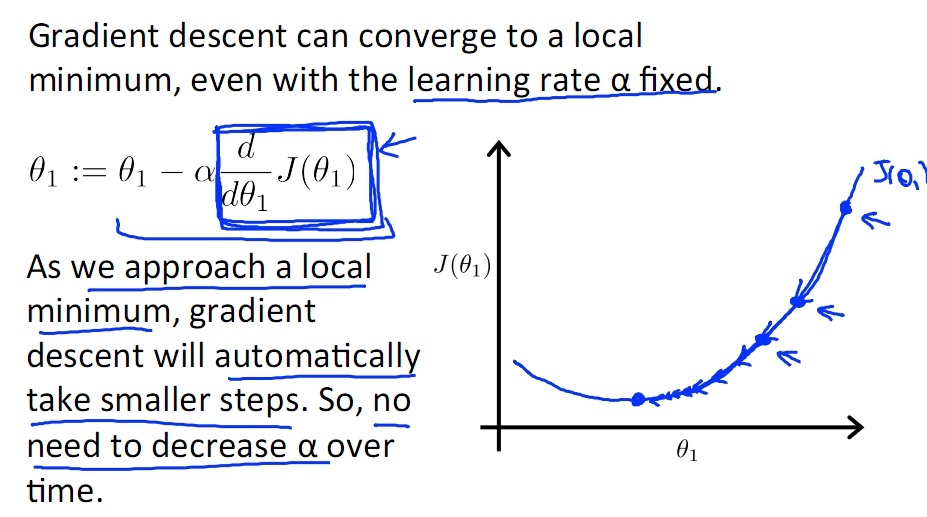
下图就是寻找过程
当梯度下降到一定数值后,每次迭代的变化很小,这时可以设定一个阈值,只要变化小鱼该阈值,就停止迭代,而得到的结果也近似于最优解。

若损失函数的值不断变大,则有可能是步长速率a太大,导致算法不收敛,这时可适当调整a值
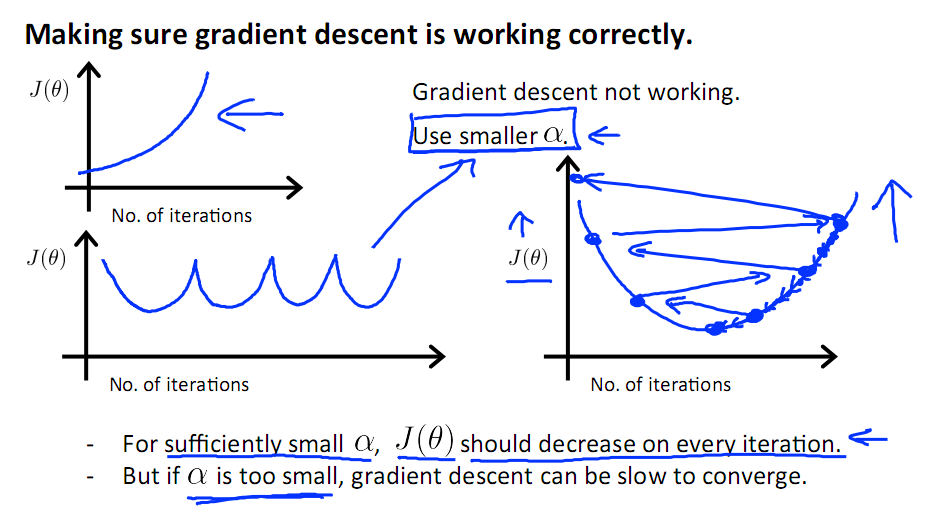
为了选择参数a,就需要不断测试,因为a太大太小都不太好。

如果想跳过的a与算法复杂的迭代,可以选择 Normal Equation。
4 随机梯度下降
对于样本数量额非常之多的情况,Batch Gradient Descent算法会非常耗时,因为每次迭代都要便利所有样本,可选用Stochastic Gradient Descent 算法,需要注意外层循环Loop,因为只遍历一次样本,不见得会收敛。

随机梯度算法就可以用作在线学习了,但是注意随机梯度的结果并非完全收敛,而是在收敛结果处波动的,可能由非线性可分的样本引起来的:
可以有如下解决办法:(来自MLIA)
1. 动态更改学习速率a的大小,可以增大或者减小
2. 随机选样本进行学习
CS229 2.深入梯度下降(Gradient Descent)算法的更多相关文章
- (二)深入梯度下降(Gradient Descent)算法
一直以来都以为自己对一些算法已经理解了,直到最近才发现,梯度下降都理解的不好. 1 问题的引出 对于上篇中讲到的线性回归,先化一个为一个特征θ1,θ0为偏置项,最后列出的误差函数如下图所示: 手动求解 ...
- 梯度下降(gradient descent)算法简介
梯度下降法是一个最优化算法,通常也称为最速下降法.最速下降法是求解无约束优化问题最简单和最古老的方法之一,虽然现在已经不具有实用性,但是许多有效算法都是以它为基础进行改进和修正而得到的.最速下降法是用 ...
- 机器学习(1)之梯度下降(gradient descent)
机器学习(1)之梯度下降(gradient descent) 题记:最近零碎的时间都在学习Andrew Ng的machine learning,因此就有了这些笔记. 梯度下降是线性回归的一种(Line ...
- 梯度下降(Gradient Descent)小结 -2017.7.20
在求解算法的模型函数时,常用到梯度下降(Gradient Descent)和最小二乘法,下面讨论梯度下降的线性模型(linear model). 1.问题引入 给定一组训练集合(training se ...
- 梯度下降(Gradient descent)
首先,我们继续上一篇文章中的例子,在这里我们增加一个特征,也即卧室数量,如下表格所示: 因为在上一篇中引入了一些符号,所以这里再次补充说明一下: x‘s:在这里是一个二维的向量,例如:x1(i)第i间 ...
- 机器学习中的数学(1)-回归(regression)、梯度下降(gradient descent)
版权声明: 本文由LeftNotEasy所有,发布于http://leftnoteasy.cnblogs.com.如果转载,请注明出处,在未经作者同意下将本文用于商业用途,将追究其法律责任. 前言: ...
- 回归(regression)、梯度下降(gradient descent)
本文由LeftNotEasy所有,发布于http://leftnoteasy.cnblogs.com.如果转载,请注明出处,在未经作者同意下将本文用于商业用途,将追究其法律责任. 前言: 上次写过一篇 ...
- 吴恩达深度学习:2.3梯度下降Gradient Descent
1.用梯度下降算法来训练或者学习训练集上的参数w和b,如下所示,第一行是logistic回归算法,第二行是成本函数J,它被定义为1/m的损失函数之和,损失函数可以衡量你的算法的效果,每一个训练样例都输 ...
- 机器学习数学基础- gradient descent算法(上)
为什么要了解点数学基础 学习大数据分布式计算时多少会涉及到机器学习的算法,所以理解一些机器学习基础,有助于理解大数据分布式计算系统(比如spark)的设计.机器学习中一个常见的就是gradient d ...
随机推荐
- Windows2008R2系统运行时间超过497天的bug
早上接到客户电话,说一台测试服务器tomcat服务无法访问,登录服务器查看tomcat连接数据库故障. 使用plsql develop工具登录,提示 ora-12560 TNS:protocol ad ...
- Jmeter之函数助手
本文转载自:心的开始 Emily0120 JMeter函数是一些能够转化在测试树中取样器或者其他配置元件的域的特殊值.一个函数的调用就像这样:${_functionName(var1,var2,va ...
- linux与Windows使用编译区别及makefile文件编写
一.Windows与:Linux嵌入式开发区别 Windows下编辑.编译.执行 编辑: sourceInsight:ADS: 编译:指定链接地址,指定链接顺序,编译 执行:烧写到单板再启动 Linu ...
- Vue--基本语法
Vue语法学习 引入:script的src中导入vue包 创建:在script中创建vue对象 双向绑定: el----选择器,锁定标签 data----定义变量,将标签内容绑定给变量 {{变量}}- ...
- 检索COML类工厂中 CLSID为 {00024500-0000-0000-C000-000000000046}的组件时失败,原因是出现以下错误: 80070005" 《终结篇》
可以看到报出的异常类型为:UnauthorizedAccessException,没有权限访问,表明我们需要配置执行操作账户的COM访问权限. 由于系统是Windows Server 2008 64位 ...
- spring cloud-前端跨域问题的解决方案
当我们需要将spring boot以restful接口的方式对外提供服务的时候,如果此时架构是前后端分离的,那么就会涉及到跨域的问题,那怎么来解决跨域的问题了,下面就来探讨下这个问题. 解决方案一: ...
- 微信小程序客服消息使用
客服消息使用 为丰富小程序的服务能力,提高服务质量,微信为小程序提供客服消息能力,以便小程序用户可以方便快捷地与小程序服务提供方进行沟通. xiaokefu.com.cn 功能介绍 用户可使用小程序客 ...
- 学习笔记之Sublime Text
Sublime Text - A sophisticated text editor for code, markup and prose https://www.sublimetext.com/ A ...
- 弹性势能,position,min用法,获取元素的宽
弹性势能: 网页div移动的mousemove的次数,跟div移动的距离没有关系,跟鼠标移动的快慢有关,浏览器自身有个计数事件,几毫秒 _this.seed*=0.95 //摩擦系数的写法 posit ...
- Scrapy实战篇(八)之Scrapy对接selenium爬取京东商城商品数据
本篇目标:我们以爬取京东商城商品数据为例,展示Scrapy框架对接selenium爬取京东商城商品数据. 背景: 京东商城页面为js动态加载页面,直接使用request请求,无法得到我们想要的商品数据 ...