requests关于Exceeded 30 redirects问题得出的结论
首先说结论,发送requests请求必须带上headers否则无法保持bs之间的会话。从而报上述的错误。
昨天一个朋友在爬网页时出现的一个问题,以及后续我对这个问题进行了简单的测试。
先说出现的问题的简单描述。
首先是使用urllib请求网页:
#urllib.request发起的请求
import urllib.request
response = urllib.request.urlopen("https://baike.baidu.com")
html = response.read().decode('utf8')
print(type(html))
print(html)
结果正常显示了百科的页面信息:

我们使用requests来请求这个https页面
#requests发起的请求
import requests
html = requests.get('https://baike.baidu.com')
print(type(html))
print(html)
然后报错了:

报错是重定向超过三十个,百度的结果是取消默认允许的重定向。
到这里我们得出第一条结论:
urllib和requests发送的请求默认会根据响应的location进行重定向。
百度了一下,根据众网友的一致推荐,我们关闭allow_redirects这个字段。
看一看源码里默认是允许重定向的。

关闭了重定向以后,页面不再跳转。
#requests发起的请求,关闭重定向
import requests
html = requests.get('https://baike.baidu.com', allow_redirects=False).text
print(type(html))
print(html)
禁止了重定向页面必然不能显示正常的百科主页了,这里我们得到的是302的跳转页面。

再次表明一下,百度里总有一些人只解决当前一个问题而不说明解决思路,或者试出来的结果就放上来当作回答的行为是很不负责的。
这里重定向的问题根本不在于页面跳转了,而是页面为什么会多次跳转。
我查到一篇关于请求亚马逊超出重定向限制的文章:http://www.it1352.com/330504.html。
简单来说就是没有与服务器建立会话,页面重定向成了环形的死循环。即你的原始URL重定向一个没有新的URL B,其重定向到C,它重定向到B,等等。
文章的结尾提到加请求头来保持会话的持久性。
#requests发起的请求,添加请求头
import requests
headers = {"User-Agent" : "User-Agent:Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"}
html = requests.get('https://baike.baidu.com', headers=headers).text
print(type(html))
print(html)
请求的页面应当是正确的,但是却出现了如下乱码:
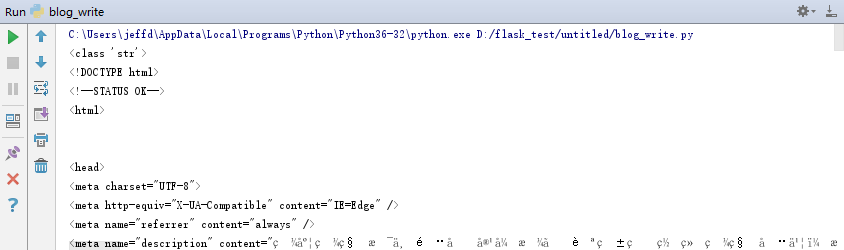
本文的第二个结论也出来了:http头部没有编码方式,requests默认使用自己的编码方式。也是很任性,具体关于requests的乱码行为的出现原因及解决方案,在这篇博客有详细介绍,可以看一下。https://www.cnblogs.com/billyzh/p/6148066.html。
#requests发起的请求,解决乱码问题
import requests
headers = {"User-Agent" : "User-Agent:Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"}
html = requests.get('https://baike.baidu.com', headers=headers).content.decode('utf8')
print(type(html))
print(html)
此时页面显示无异常,正确显示百科的地址。

#requests发起的请求,加上重定向禁止
import requests
headers = {"User-Agent" : "User-Agent:Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"}
html = requests.get('https://baike.baidu.com', headers=headers, allow_redirects=False).content.decode('utf8')
print(type(html))
print(html)

结果没有影响,所以前面提到的解决重定向问题解决方案,多数人提到的禁止重定向根本无效,根本在于保持会话,防止重定向进入死循环。
本文结论三:多Google少百度(只针对技术性问题)。
到这里我们到底在模拟发送请求时请求头带了哪些东西导致的出现上面的问题呢?只能一步步分析请求头的信息。
#urllib请求时发送的请求头
import urllib.request
request = urllib.request.Request("https://baike.baidu.com")
print(request.headers)#{}
print(request.get_header("User-agent"))#None

但实际上肯定是不能发送一个空的请求头的,所以我们抓包获取发送的请求信息。
urllib的响应头
#urllib请求时回应的响应头
import urllib.request
request = urllib.request.urlopen("https://baike.baidu.com")
print(request.headers)

urllib在请求的时候什么也没做,请求头也没东西,然而服务器对他温柔以待,响应了正确的跳转页面。
#requests请求超出30次重定向,暂时无法得到他的请求头
import requests
h=requests.get('https://baike.baidu.com')
print(h.request.headers)
同理响应头我也看不到。
#requests阻止重定向他的请求头
import requests
h=requests.get('https://baike.baidu.com', allow_redirects=False)
print(h.request.headers)
{'User-Agent': 'python-requests/2.18.4', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
User-Agent表示了自己是python解释器的请求。
#requests阻止重定向他的响应头
import requests
h=requests.get('https://baike.baidu.com', allow_redirects=False).headers
print(h)
{'Connection': 'keep-alive', 'Content-Length': '', 'Content-Type': 'text/html', 'Date': 'Wed, 31 Jan 2018 04:07:32 GMT', 'Location': 'https://baike.baidu.com/error.html?status=403&uri=/', 'P3p': 'CP=" OTI DSP COR IVA OUR IND COM "', 'Server': 'Apache', 'Set-Cookie': 'BAIDUID=C827DBDDF50E38C0C10F649F1DAAA462:FG=1; expires=Thu, 31-Jan-19 04:07:32 GMT; max-age=31536000; path=/; domain=.baidu.com; version=1'}
连接是keep alive,有location显示重定向地址。
#requests带上自己浏览器信息的请求头
import requests
headers = {"User-Agent" : "User-Agent:Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"}
h=requests.get('https://baike.baidu.com', allow_redirects=False,headers=headers)
print(h.request.headers)
{'User-Agent': 'User-Agent:Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
#requests带上自己浏览器信息的请求头,默认允许重定向
import requests
headers = {"User-Agent" : "User-Agent:Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"}
h=requests.get('https://baike.baidu.com',headers=headers)
print(h.request.headers)
与上面一样,再次验证阻不阻止页面重定向不是解决问题的关键点。
根据上面的测试,我有一个大胆的猜测,urllib请求会被服务器接受并响应了setcookie字段,有了cookie创建一个会话最后保证了重定向的正常请求到一个最终的页面,但是requests不加请求头并不会被服务器返回setcookie,产生环形的重定向,最终无法定位到跳转的页面,而加上请求头User-Agent字段,那么服务器默认会建立会话保证跳转到正常的页面。
补充一点,结论是不加请求头,requests无法保证与服务器之间的会话,每次连接服务器都被当作一条新请求直接让他跳转,不存在重定向环路的问题。
# #requests禁止跳转的请求头
import requests
h=requests.get('https://baike.baidu.com', allow_redirects=False,verify=False)
print(h.request.headers)
抓到的get的请求包:
# #requests带上自己浏览器信息的请求头
import requests
headers = {"User-Agent" : "User-Agent:Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"}
h=requests.get('https://baike.baidu.com', allow_redirects=False,headers=headers,verify=False)
print(h.request.headers)

所以使用requests记得一定加上请求头信息。
希望各位大神如果一不小心看完这篇文章请指出我说的不对的地方,或者哪些方面理解的还不够深刻。谢谢。
测试的时候没考虑太多,其实可以通过http://httpbin.org来查看请求响应信息更加直观方便,这个网址是专门用来测试http请求的。
requests关于Exceeded 30 redirects问题得出的结论的更多相关文章
- Python requests 301/302/303重定向(跨域/本域)cookie、Location问题
今天使用request的get方法获取一个网站的登录页信息,结果使用charles抓包的时候发现该网站登录页303(重定向的问题),网上查了很多资料,原因如下: 一.cookie 原因:利用reque ...
- python爬虫慕课基础2
实战演练:爬取百度百科1000个页面的数据 对于新手来说,可以把spider_main.py代码中的try和except去掉,运行报错就会在控制台出现,根据错误去调试自己的程序 发现以下错误: req ...
- python爬虫重定向次数过多问题
错误提示如下: raise TooManyRedirects('Exceeded %s redirects.' % self.max_redirects, response=resp)requests ...
- windows批处理执行图片爬取脚本
背景 由于测试时需要上传一些图片,而自己保存的图片很少. 为了让测试数据看起来不那么重复,所以网上找了一个爬虫脚本,以下是源码: 1 import requests 2 import os 3 4 c ...
- requests.session
# -*- coding: utf-8 -*- """requests.session~~~~~~~~~~~~~~~~ This module provides a Se ...
- 并发测试 java.lang.OutOfMemoryError: GC overhead limit exceeded Xms Xmx 阻塞请求 单节点 请求分发 负载均衡
at javax.servlet.http.HttpServlet.service(HttpServlet.java:705) at javax.servlet.http.HttpServlet.se ...
- Using Load-Balancers with Oracle E-Business Suite Release 12 (Doc ID 380489.1)
Using Load-Balancers with Oracle E-Business Suite Release 12 (Doc ID 380489.1) Modified: 12-Jun-20 ...
- PHP加速器
转http://www.vpser.net/opt/apc-eaccelerator-xcache.html 一.PHP加速器介绍 PHP加速器是一个为了提高PHP执行效率,从而缓存起 ...
- 关于PHP加速eAccelerator、Xcache、APC和Zend Optimizer
以前只关注过Zend Optimizer,因为高胖子的书就是这样教的,但是遇到奇葩公司的面试题提问你知道多少个php加速器/缓存,我一下子楞了,因为我所知道的php5.2.x只用过Zend Optim ...
随机推荐
- IDEA第六章----快捷键
第一节:解决快捷键冲突 idea支持很多快捷键,这样就导致了很多快捷键和其他应用冲突,所以需要把其他应用的快捷键去掉,下面以输入法和QQ为例. QQ我就留下了提取消息和截图,这个是个人习惯问题. 第二 ...
- Mongodb常规操作【一】
Mongodb是一种比较常见的NOSQL数据库,数据库排名第四,今天介绍一下Net Core 下,常规操作. 首先下C# 版的驱动程序 "MongoDB.Driver",相关依赖包 ...
- linux下的磁盘挂载
将新的磁盘安装在服务器上后,怎么挂载到现在的服务器上呢? 1.查询是否已经分配磁盘 fdisk -l 这里因为测试,只是挂载了10G的硬盘 2.发现有磁盘/dev/sdb.然后使用fdisk命令建立分 ...
- Java学习笔记20(String类应用、StringBuffer类、StringBuilder类)
1.获取指定字符串中大小写和数字的个数: package demo; public class StringTest { public static void main(String[] args) ...
- spark 1.6 完全分布式平台搭建
软件环境: scala-2.11.4.tgz spark-1.6.2-bin-hadoop2.6.tgz 操作步骤: 一. 安装scala 1. 解压scala (tar –zxvf filena ...
- 记录一次APP的转让流程
由于业务需要,需要将开发的App从一个账号(A账号)转移到另一个账号(B账号),这里简单介绍一下转让流程.主要包括两大步骤: 转让方(A账号)提出转让申请 接收方(B账号)接受转让App 如果不想看这 ...
- Python各类图像库的图片读写方式总结
最近在研究深度学习视觉相关的东西,经常需要写python代码搭建深度学习模型.比如写CNN模型相关代码时,我们需要借助python图像库来读取图像并进行一系列的图像处理工作.我最常用的图像库当然是op ...
- while100以内的偶数
#显示100以内的偶数 #声明i i = 1 #开始循环条件为i不等于100,执行while代码块 while i != 100: #给i加1 i +=1 #如果循环到此时i的取余运算为0则打印i i ...
- 5分钟了解MySQL5.7的undo log在线收缩新特性
Part1:写在最前 在MysQL5.6版本中,可以把undo log 回滚日志分离到一个单独的表空间里:其缺点是不能回收空间大小,until MysQL5.7,but MariadDB10.1暂不支 ...
- [整]swp文件的处理
报错 vim非正常关闭,再下次编辑打开文件时均为显示如下警告信息: Swap file "test.xml.swp" already exists! [O]pen Read-Onl ...