如何搭建Zookeeper集群
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。其部署方式有单机部署和集群部署,单机部署意义不大,下面主要介绍集群部署。
因硬件环境的限制,本次搭建Zookeeper集群是在Windows且是单机的环境下搭建的,也就是伪集群;不过伪集群跟集群区别不大,往下看就知道啦。
一、去Zookeeper官网http://zookeeper.apache.org/把安装包下载下来,给个3.4.10版本的链接:http://mirrors.hust.edu.cn/apache/zookeeper/stable/zookeeper-3.4.10.tar.gz。解压缩安装包。
二,在单机环境下部署集群。
1、 准备节点。弄三个zookeeper节点,将安装包拷贝三份,分别命名为zookeeper-3.4.10_1,zookeeper-3.4.10_2,zookeeper-3.4.10_3。如下图:

2、修改zoo.cfg配置文件。以zookeeper-3.4.10_1节点为例,在conf文件夹下,将zoo_sample.cfg重命名为zoo.cfg,同时增加以下配置信息:
tickTime=2000
initLimit=5
syncLimit=2
dataDir=E:\\zookeeper-3.4.10_1\\server1\\data
dataLogDir=E:\\zookeeper-3.4.10_1\\server1\\dataLog
clientPort=2181
server.1=127.0.0.1:2888:3888
server.2=127.0.0.1:2889:3889
server.3=127.0.0.1:2890:3890
标红的几个配置官网讲得很清楚了,就不做讲解了。需要注意的是clientPort这个端口,如果你是在1台机器上部署多个server,那么每台机器都要不同的clientPort,比如我server1是2181,server2是2182,server3是2183,dataDir和dataLogDir也需要区分下,
dataDir和dataLogDir这两个目录需要我们手动创建 。
最后几行唯一需要注意的地方就是 server.X 这个数字就是对应 data/myid中的数字。你在3个server的myid文件中分别写入了1,2,3,那么每个server中的zoo.cfg都配server.1,server.2,server.3就OK了。因为在同一台机器上,后面连着的2个端口3个server都不要 一样,否则端口冲突,其中第一个端口用来集群成员的信息交换,第二个端口是在leader挂掉时专门用来进行选举leader所用。
如果将集群的每个节点布置到不同的机器上的话,那么所有节点的配置文件都是一样的,这也就是伪集群跟集群的区别所在。下面给出配置信息:
tickTime=2000
initLimit=5
syncLimit=2
dataDir=E:\\zookeeper-3.4.10\\server\\data
dataLogDir=E:\\zookeeper-3.4.10\\server\\dataLog
clientPort=2181
server.1=192.168.10.8:2888:3888
server.2=192.168.10.15:2888:3888
server.3=192.168.10.22:2888:3888
注意:dataDir和dataLogDir的路径要用\\分隔,要不然启动的时候会报错
3、启动Zookeeper。进入到bin目录下,点击 zkServer.cmd命令或者通过cmd命令行方式来运行这个命令(这样最好,启动报错了能看到),即可完成启动。
启动过程中如果报 “$dataDir/myid file is missing” 错误,是因为没有在dataDir目录下创建myid文件导致的,zk集群中的节点需要获取myid文件内容来标识该节点,缺失则无法启动;往myid里面写的数字也就是配置文件zoo.cfg里 server.1=192.168.10.8:2888:3888,server后面这个数字。
如果报Connection refused 链接类的错误的话不用管,这是zookeeper节点试图链接其他节点报的错误,等所有节点都启动完毕就不会报错了。启动顺序如果是1、2、3的话,那么2节点是Leader哈。关于Leader的选举算法大家去好好研究一下,后续我再出博文。
注意:这个myid文件是不带任何扩展类型的文件,在windows下创建的文本文件,需要手动将扩展类型去掉,要不然启动也会报上面那个错误。
三,Zookeeper数据模型。
Zookeeper 会维护一个具有层次关系的数据结构,它非常类似于一个标准的文件系统,如下图所示
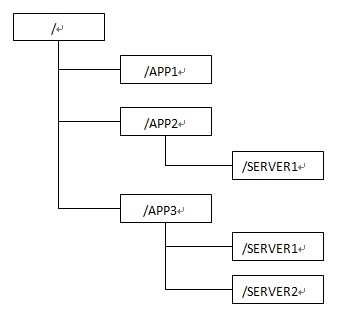
(1) 每个节点在zookeeper中叫做znode,并且其有一个唯一的路径标识,如/SERVER2节点的标识就为/APP3/SERVER2
(2) Znode 可以有子znode,并且znode里可以存数据,但是EPHEMERAL类型的节点不能有子节点
(3) Znode中的数据可以有多个版本,比如某一个路径下存有多个数据版本,那么查询这个路径下的数据就需要带上版本。
(4) znode 可以是临时节点,一旦创建这个 znode 的客户端与服务器失去联系,这个 znode 也将自动删除,Zookeeper 的客户端和服务器通信采用长连接方式,每个客户端和 服务器通过心跳来保持连接,这个连接状态称为 session,如果 znode 是临时节点这个 session 失效,znode 也就删除了
(5) znode 的目录名可以自动编号,如 App1 已经存在,再创建的话,将会自动命名为 App2
(6) znode 可以被监控,包括这个目录节点中存储的数据的修改,子节点目录的变化等,一旦变化可以通知设置监控的客户端,这个功能是zookeeper对于应用最重要的特性,通过这个特性可以实现的功能包括配置的集中管理,集群管理,分布式锁等等。
下面我们通过zookeeper自带的客户端交互程序来创建、修改、删除节点来探索zookeeper的数据结构。
进入任意一台zookeeper节点,到bin目录下,运行zkCli.cmd命令。出现如下图界面:

1、ls path [watch]查看命令。 ls /

有两个节点zookeeper,APP1
2、get path [watch]查看节点数据命令。get /APP1

3、create [-s] [-e] path data acl 创建节点命令

4、delete path [version] 删除节点命令

注意:zookeeper集群所有节点的数据都是一致的,如果在这个节点创建的znode在其他节点同样也会创建,因为zookeeper的数据是一致性的,原理请自行百度zookeeper运行原理。
四、通过Zookeeper四字命令来获取集群服务的当前状态及相关信息。
ZooKeeper支持某些特定的四字命令字母与其交互。它们大多是查询命令,用来获取 ZooKeeper 服务的当前状态及相关信息。用户在客户端可以通过 telnet 或 nc 向 ZooKeeper 提交相应的命令。 其中stat、srvr、cons三个命令比较类似:"stat"提供服务器 统计和客户端连接的一般信息;"srvr"只有服务的统计信息,"cons"提供客户端连接的更加详细的信息。 命令详细介绍如下:

在windows下,我们来演示一个命令吧,mntr命令。
1、打开cmd命令行模式
2、运行,telnet 127.0.0.1 2183

3、输入:mntr命令

输入的命令看不到,尽情输入即可。
4、结果:

根据zk_server_state:leader 知道该节点为Leader节点
注意:如果运行telnet 127.0.0.1 2183命令报“无法打开主机的连接,在端口23连接失败”错误的话,请将windows的telnet服务打开。打开方法请参考:http://jingyan.baidu.com/article/cdddd41c7dd85253ca00e14e.html
在linux下部署集群跟windows部署步骤和操作都差不多,大家有机器的话可以到linux环境下部署一下。
如何搭建Zookeeper集群的更多相关文章
- centos 6.5 搭建zookeeper集群
为什么使用Zookeeper? 大部分分布式应用需要一个主控.协调器或控制器来管理物理分布的子进程(如资源.任务分配等)目前,大部分应用需要开发私有的协调程序,缺乏一个通用的机制协调程序的反复编写浪费 ...
- docker-compose搭建zookeeper集群
搭建zookeeper集群 创建docker-compose.yml文件 ``` version: '3.1' services: zoo1: image: zookeeper restart: al ...
- docker-compose搭建zookeeper集群环境 CodingCode
docker-compose搭建zookeeper集群环境 使用docker-compose搭建zookeeper集群环境 zookeeper是一个集群环境,用来管理微服务架构下面的配置管理功能. 这 ...
- 使用Cloudera Manager搭建zookeeper集群及HDFS HA实战篇
使用Cloudera Manager搭建zookeeper集群及HDFS HA实战篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.使用Cloudera Manager搭建zo ...
- docker 搭建zookeeper集群和kafka集群
docker 搭建zookeeper集群 安装docker-compose容器编排工具 Compose介绍 Docker Compose 是 Docker 官方编排(Orchestration)项目之 ...
- 搭建zookeeper集群_其中一个报Mode: standalone,另外两个分别是leader和follower
用3个zookeeper搭建一个zookeeper集群,首先配置好一个zookeeper1,其余两个都是按照zookeeper1复制过来,然后稍微修改 运行集群成功,查看zookeeper状态 可以看 ...
- 大数据平台搭建-zookeeper集群的搭建
本系列文章主要阐述大数据计算平台相关框架的搭建,包括如下内容: 基础环境安装 zookeeper集群的搭建 kafka集群的搭建 hadoop/hbase集群的搭建 spark集群的搭建 flink集 ...
- Docker中搭建zookeeper集群
1.获取官方镜像 从dockerhub获取官方的zookeeper镜像: docker pull zookeeper 2.了解镜像内容 拉取完镜像后,通过 docker inspect zookeep ...
- Zookeeper介绍 Zookeeper搭建 Zookeeper集群搭建
关键字:分布式 背景 随着互联网技术的高速发展,企业对计算机系统的技术.存储能力要求越来越高,最简单的证明就是出现了一些诸如:高并发.海量存储这样的词汇.在这样的背景 下,单纯依靠少量 ...
随机推荐
- 基于Vivado调用ROM IP core设计DDS
DDS直接数字式频率合成器(Direct Digital Synthesizer) 下面是使用MATLAB生成正弦波.三角波.方波的代码,直接使用即可. t=:*pi/^:*pi y=0.5*sin ...
- mysql常用sql命令
一.连接MYSQL. 格式: mysql -h主机地址 -u用户名 -p用户密码 1.连接到本机上的MYSQL. 首先打开DOS窗口,然后进入目录mysql\bin,再键入命令mysql -u roo ...
- 兔子与樱花[HEOI2015]
题目描述 很久很久之前,森林里住着一群兔子.有一天,兔子们突然决定要去看樱花.兔子们所在森林里的樱花树很特殊.樱花树由n个树枝分叉点组成,编号从0到n-1,这n个分叉点由n-1个树枝连接,我们可以把它 ...
- grunt+bower依赖管理
安装bower(必须安装git) npm install bower -g bower按照插件命令 初始化配置 bower init 生成bower.json //如果有bower.json 直接输入 ...
- Javascript DOM 编程艺术———总结-2
第三章: 一,DOM: Document(文档) Object(对象):用户定义对象,内建对象,宿主对象. Model(模型) 二,节点: 元素节点:诸如:<body> <p> ...
- JavaScript数组遍历(迭代)方法 8种
最近工作中经常涉及到数据的处理,数组尤其常见,经常需要对其进行遍历.转换操作,网上的文章零零散散,不得已自己又找出红宝书来翻出来看,顺便记一笔,便于以后查询. 数组常用的方法 ECMAScript5为 ...
- Section 1.1 Greedy Gift Givers
Greedy Gift Givers A group of NP (2 ≤ NP ≤ 10) uniquely named friends hasdecided to exchange gifts o ...
- js数组去重方法分析与总结
数组去重经常被人拿来说事,虽然在工作中不常用,但他能够很好的考察js基础知识掌握的深度和广度,下面从js的不同阶段总结一下去重的方法. ES3阶段 该阶段主要通过循环遍历数组从而达到去重的目的 多次循 ...
- 【Spring】浅谈ContextLoaderListener及其上下文与DispatcherServlet的区别
一般在使用SpingMVC开发的项目中,一般都会在web.xml文件中配置ContextLoaderListener监听器,如下: <listener> <listener-clas ...
- adb shell screenrecord命令行使用说明
一.查看帮助命令,参数 --help D:\>adb shell screenrecord --help Usage: screenrecord [options] <filename&g ...