python学习(23)requests库爬取猫眼电影排行信息
本文介绍如何结合前面讲解的基本知识,采用requests,正则表达式,cookies结合起来,做一次实战,抓取猫眼电影排名信息。
用requests写一个基本的爬虫
排行信息大致如下图
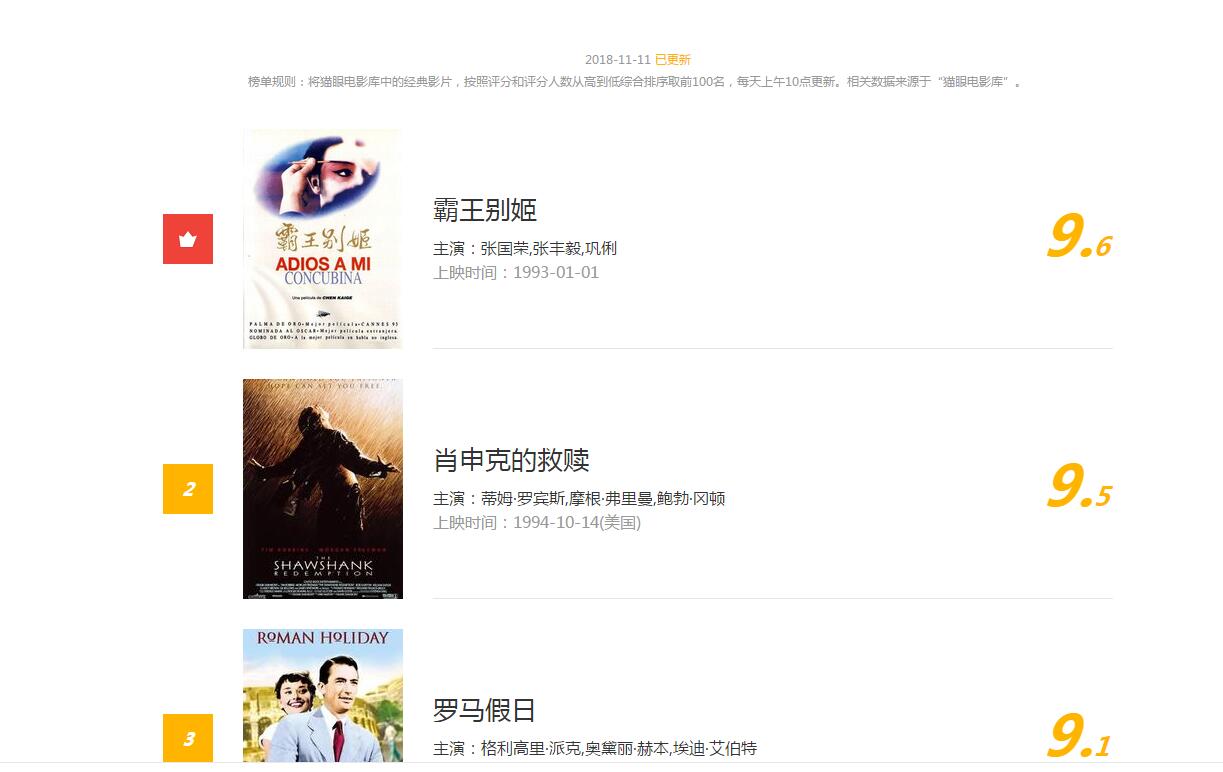
网址链接为http://maoyan.com/board/4?offset=0
我们通过点击查看源文件,可以看到网页信息
每一个电影的html信息都是下边的这种结构
<i class="board-index board-index-3">3</i>
<a href="/films/2641" title="罗马假日" class="image-link" data-act="boarditem-click" data-val="{movieId:2641}">
<img src="//ms0.meituan.net/mywww/image/loading_2.e3d934bf.png" alt="" class="poster-default" />
<img data-src="http://p0.meituan.net/movie/54617769d96807e4d81804284ffe2a27239007.jpg@160w_220h_1e_1c" alt="罗马假日" class="board-img" />
</a>
<div class="board-item-main">
<div class="board-item-content">
<div class="movie-item-info">
<p class="name"><a href="/films/2641" title="罗马假日" data-act="boarditem-click" data-val="{movieId:2641}">罗马假日</a></p>
<p class="star">
主演:格利高里·派克,奥黛丽·赫本,埃迪·艾伯特
</p>
其实对我们有用的就是 img src(图片地址) title 电影名 star 主演。
所以根据前边介绍过的正则表达式写法,可以推导出正则表达式
compilestr = r'''<dd>.*?<i class="board-index.*?<img data-src="(.*?)@.*?title="(.*?)".*?<p class="star">
(.*?)</p>.*?<p class="releasetime">.*?(.*?)</p'''
‘.’表示匹配任意字符,如果正则表达式用re.S模式,.还可以匹配换行符,’‘表示匹配前一个字符0到n个,’?’表示非贪婪匹配,
所以’.?’可以理解为匹配任意字符。接下来写代码打印我们匹配的条目
import requests
import re
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0' if __name__ == "__main__":
headers={'User-Agent':USER_AGENT,
}
session = requests.Session()
req = session.get('http://maoyan.com/board/4?offset=0',headers = headers, timeout = 5)
compilestr = r'<dd>.*?<i class="board-index.*?<img data-src="(.*?)@.*?title="(.*?)".*?<p class="star">(.*?)</p>.*?<p class="releasetime">.*?(.*?)</p'
#print(req.content)
pattern = re.compile(compilestr,re.S)
#print(req.content.decode('utf-8'))
lists = re.findall(pattern,req.content.decode('utf-8'))
for item in lists:
#print(item)
print(item[0].strip())
print(item[1].strip())
print(item[2].strip())
print(item[3].strip())
print('\n')
运行一下,结果如下
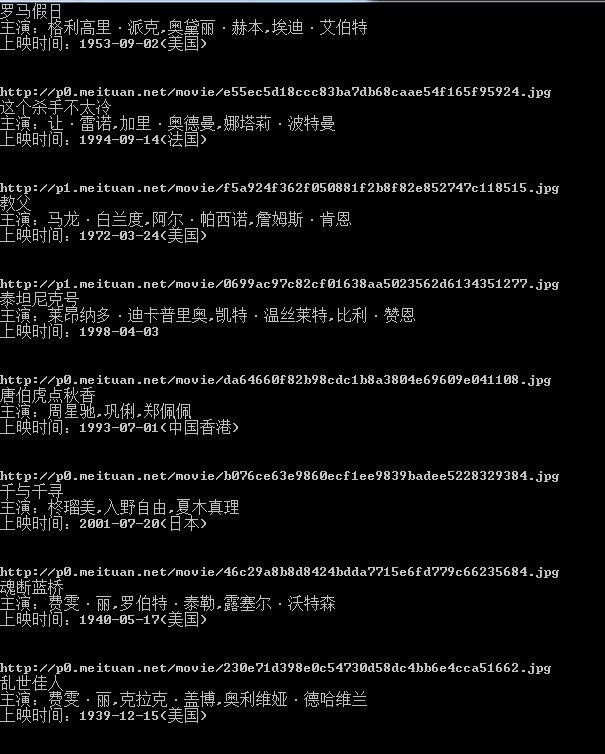
看来我们抓取到数据了,我们只爬取了这一页的信息,接下来我们分析第二页,第三页的规律,点击第二页,网址变为’http://maoyan.com/board/4?offset=10',点击第三页网址变为'http://maoyan.com/board/4?offset=20',所以每一页的offset偏移量为20,这样我们可以计算偏移量达到抓取不同页码的数据,将上一个程序稍作修改,变为可以爬取n页数据的程序
import requests
import re
import time
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0' class MaoYanScrapy(object):
def __init__(self,pages=1):
self.m_session = requests.Session()
self.m_headers = {'User-Agent':USER_AGENT,}
self.m_compilestr = r'<dd>.*?<i class="board-index.*?<img data-src="(.*?)@.*?title="(.*?)".*?<p class="star">(.*?)</p>.*?<p class="releasetime">.*?(.*?)</p'
self.m_pattern = re.compile(self.m_compilestr,re.S)
self.m_pages = pages def getPageData(self):
try:
for i in range(self.m_pages):
httpstr = 'http://maoyan.com/board/4?offset='+str(i)
req = self.m_session.get(httpstr,headers=self.m_headers,timeout=5)
lists = re.findall(self.m_pattern,req.content.decode('utf-8'))
time.sleep(1)
for item in lists:
img = item[0]
print(img.strip()+'\n')
name = item[1]
print(name.strip()+'\n')
actor = item[2]
print(actor.strip()+'\n')
fiemtime = item[3]
print(fiemtime.strip()+'\n') except:
print('get error') if __name__ == "__main__":
maoyanscrapy = MaoYanScrapy()
maoyanscrapy.getPageData()
运行下,效果和之前一样,只是支持了页码的传参了。
下面继续完善下程序,把每个电影的图片抓取并保存下来,这里面用到了创建文件夹,路径拼接,文件保存的基础知识,综合运用如下
import requests
import re
import time
import os
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0' class MaoYanScrapy(object):
def __init__(self,pages=1):
self.m_session = requests.Session()
self.m_headers = {'User-Agent':USER_AGENT,}
self.m_compilestr = r'<dd>.*?<i class="board-index.*?<img data-src="(.*?)@.*?title="(.*?)".*?<p class="star">(.*?)</p>.*?<p class="releasetime">.*?(.*?)</p'
self.m_pattern = re.compile(self.m_compilestr,re.S)
self.m_pages = pages
self.dirpath = os.path.split(os.path.abspath(__file__))[0] def getPageData(self):
try:
for i in range(self.m_pages):
httpstr = 'http://maoyan.com/board/4?offset='+str(i)
req = self.m_session.get(httpstr,headers=self.m_headers,timeout=5)
lists = re.findall(self.m_pattern,req.content.decode('utf-8'))
time.sleep(1)
for item in lists:
img = item[0]
print(img.strip()+'\n')
name = item[1]
dirpath = os.path.join(self.dirpath,name)
if(os.path.exists(dirpath)==False):
os.makedirs(dirpath)
print(name.strip()+'\n')
actor = item[2]
print(actor.strip()+'\n')
fiemtime = item[3]
print(fiemtime.strip()+'\n')
txtname = name+'.txt'
txtname = os.path.join(dirpath,txtname)
if(os.path.exists(txtname)==True):
os.remove(txtname)
with open (txtname,'w') as f:
f.write(img.strip()+'\n')
f.write(name.strip()+'\n')
f.write(actor.strip()+'\n')
f.write(fiemtime.strip()+'\n')
picname=os.path.join(dirpath,name+'.'+img.split('.')[-1])
if(os.path.exists(picname)):
os.remove(picname)
req=self.m_session.get(img,headers=self.m_headers,timeout=5)
time.sleep(1)
with open(picname,'wb') as f:
f.write(req.content)
except:
print('get error') if __name__ == "__main__":
maoyanscrapy = MaoYanScrapy()
maoyanscrapy.getPageData()
运行一下,可以看到在文件的目录里多了几个文件夹
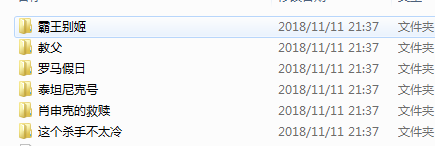
点击一个文件夹,看到里边有我们保存的图片和信息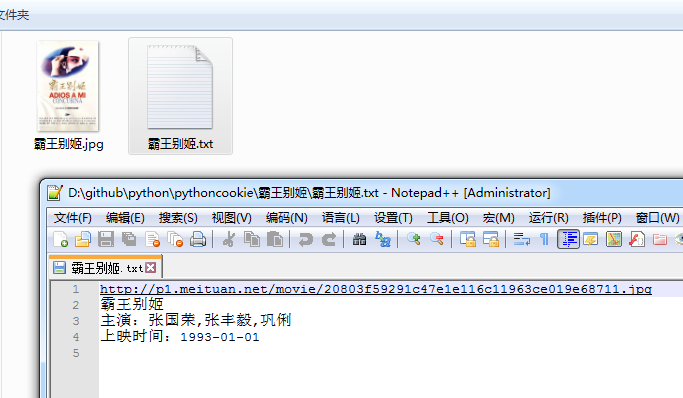
好了,到此为止,正则表达式和requests结合,做的爬虫实战完成。
源码地址:
谢谢关注我的公众号:https://github.com/secondtonone1/python-
python学习(23)requests库爬取猫眼电影排行信息的更多相关文章
- 用requests库爬取猫眼电影Top100
这里需要注意一下,在爬取猫眼电影Top100时,网站设置了反爬虫机制,因此需要在requests库的get方法中添加headers,伪装成浏览器进行爬取 import requests from re ...
- requests库爬取猫眼电影“最受期待榜”榜单 --网络爬虫
目标站点:https://maoyan.com/board/6 # coding:utf8 import requests, re, json from requests.exceptions imp ...
- PYTHON 爬虫笔记八:利用Requests+正则表达式爬取猫眼电影top100(实战项目一)
利用Requests+正则表达式爬取猫眼电影top100 目标站点分析 流程框架 爬虫实战 使用requests库获取top100首页: import requests def get_one_pag ...
- 一起学爬虫——使用xpath库爬取猫眼电影国内票房榜
之前分享了一篇使用requests库爬取豆瓣电影250的文章,今天继续分享使用xpath爬取猫眼电影热播口碑榜 XPATH语法 XPATH(XML Path Language)是一门用于从XML文件中 ...
- Python使用asyncio+aiohttp异步爬取猫眼电影专业版
asyncio是从pytohn3.4开始添加到标准库中的一个强大的异步并发库,可以很好地解决python中高并发的问题,入门学习可以参考官方文档 并发访问能极大的提高爬虫的性能,但是requests访 ...
- Python爬虫之requests+正则表达式抓取猫眼电影top100以及瓜子二手网二手车信息(四)
requests+正则表达式抓取猫眼电影top100 一.首先我们先分析下网页结构 可以看到第一页的URL和第二页的URL的区别在于offset的值,第一页为0,第二页为10,以此类推. 二.< ...
- Python爬虫学习==>第十章:使用Requests+正则表达式爬取猫眼电影
学习目的: 通过一个一个简单的爬虫应用,初窥门径. 正式步骤 Step1:流程框架 抓取单页内容:利用requests请求目标站点,得到单个页面的html代码,返回结果: 正则表达式分析:根据html ...
- python爬虫知识点总结(九)Requests+正则表达式爬取猫眼电影
一.爬取流程 二.代码演示 #-*- coding: UTF-8 -*- #_author:AlexCthon #mail:alexcthon@163.com #date:2018/8/3 impor ...
- 利用Python3的requests和re库爬取猫眼电影笔记
以下笔记,作为参考借鉴,如有疑问可以联系我进行交流探讨! 代码思路很简单,简单概括为: 首先利用requests的get方法获取页面的html文件,之后对得到的html文件进行相对应的正则处理,然 ...
随机推荐
- Python3入门机器学习 - k近邻算法
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一.所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代 ...
- 将项目托管到GitHub实现步骤
修改于:2017.1.14 第一步:先注册一个Github的账号 注册地址:Github官网注册入口 第二步:准备工作 gitHub网站使用Git版本管理工具来对仓库进行管理,但是它们并不等同. gi ...
- javascript常用方法和技巧
浏览器变编辑器 data:text/html, <style type=;right:;bottom:;left:;}</style><div id="e" ...
- MySQL原生API、MySQLi面向过程、MySQLi面向对象、PDO操作MySQL
[转载]http://www.cnblogs.com/52fhy/p/5352304.html 本文将举详细例子向大家展示PHP是如何使用MySQL原生API.MySQLi面向过程.MySQLi面向对 ...
- CF 1100C NN and the Optical Illusion(数学)
NN is an experienced internet user and that means he spends a lot of time on the social media. Once ...
- 论如何制做一个工程APP的测试内容
测试一般在软件开发过程中就已经开始进行了,测试越早.发现问题解决他的方案成本就越小.测试按照类型来区分可以划分为:单元测试,集成测试,系统测试.而OCUNIT是XCODE自带的单元测试工具.需要建立新 ...
- 第一阶段Spring个人总结
通过这一阶段的冲刺,我感到的是名义上的团队,而实际上却是一个人的事,每个人跟每个人都不一样,都有自己的特点,总会出些不必要的麻烦. 还有团队的进展也是看不到什么东西,说实话,这次我并没有太多关注团队的 ...
- 初涉JSP+JDBC 基于SQL2008的登陆验证程序
简单的以代码的形式纪念一下,因为现在还没有解决SQL2008驱动的问题,并且有好多东西要学,所以日后会有更新~ 所安装的软件有:SQL2008,eclipse,tomcat,JDK,涉及环境配置.等等 ...
- 自己对git的认识。
刚打开这个软件的网页,只能用一个字来形容,蒙,蒙,蒙,重要的事要说三遍,全英文的,这到底是什么东西,连注册都得慢慢翻译,这英语基础实在是太差劲了. 看了老师推荐的对Git使用介绍,由于之前对这个软件的 ...
- Codeforces Round #258 (Div. 2) 容斥+Lucas
题目链接: http://codeforces.com/problemset/problem/451/E E. Devu and Flowers time limit per test4 second ...