HBase学习之路 (六)过滤器
过滤器(Filter)
基础API中的查询操作在面对大量数据的时候是非常苍白的,这里Hbase提供了高级的查询方法:Filter。Filter可以根据簇、列、版本等更多的条件来对数据进行过滤,基于Hbase本身提供的三维有序(主键有序、列有序、版本有序),这些Filter可以高效的完成查询过滤的任务。带有Filter条件的RPC查询请求会把Filter分发到各个RegionServer,是一个服务器端(Server-side)的过滤器,这样也可以降低网络传输的压力。
要完成一个过滤的操作,至少需要两个参数。一个是抽象的操作符,Hbase提供了枚举类型的变量来表示这些抽象的操作符:LESS/LESS_OR_EQUAL/EQUAL/NOT_EUQAL等;另外一个就是具体的比较器(Comparator),代表具体的比较逻辑,如果可以提高字节级的比较、字符串级的比较等。有了这两个参数,我们就可以清晰的定义筛选的条件,过滤数据。
抽象操作符(比较运算符)
LESS <
LESS_OR_EQUAL <=
EQUAL =
NOT_EQUAL <>
GREATER_OR_EQUAL >=
GREATER >
NO_OP 排除所有
比较器(指定比较机制)
BinaryComparator 按字节索引顺序比较指定字节数组,采用 Bytes.compareTo(byte[])
BinaryPrefixComparator 跟前面相同,只是比较左端的数据是否相同
NullComparator 判断给定的是否为空
BitComparator 按位比较
RegexStringComparator 提供一个正则的比较器,仅支持 EQUAL 和非 EQUAL
SubstringComparator 判断提供的子串是否出现在 value 中
HBase过滤器的分类
比较过滤器
1、行键过滤器 RowFilter
Filter rowFilter = new RowFilter(CompareOp.GREATER, new BinaryComparator("95007".getBytes()));
scan.setFilter(rowFilter);
public class HbaseFilterTest {
private static final String ZK_CONNECT_KEY = "hbase.zookeeper.quorum";
private static final String ZK_CONNECT_VALUE = "hadoop1:2181,hadoop2:2181,hadoop3:2181";
private static Connection conn = null;
private static Admin admin = null;
public static void main(String[] args) throws Exception {
Configuration conf = HBaseConfiguration.create();
conf.set(ZK_CONNECT_KEY, ZK_CONNECT_VALUE);
conn = ConnectionFactory.createConnection(conf);
admin = conn.getAdmin();
Table table = conn.getTable(TableName.valueOf("student"));
Scan scan = new Scan();
Filter rowFilter = new RowFilter(CompareOp.GREATER, new BinaryComparator("95007".getBytes()));
scan.setFilter(rowFilter);
ResultScanner resultScanner = table.getScanner(scan);
for(Result result : resultScanner) {
List<Cell> cells = result.listCells();
for(Cell cell : cells) {
System.out.println(cell);
}
}
}
运行结果部分截图
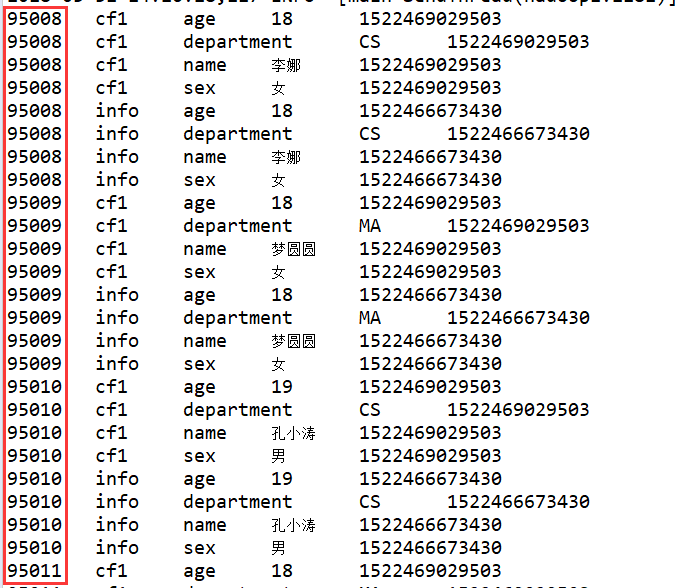
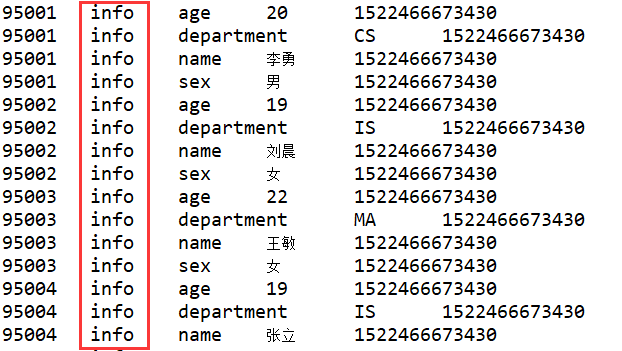
2、列簇过滤器 FamilyFilter
Filter familyFilter = new FamilyFilter(CompareOp.EQUAL, new BinaryComparator("info".getBytes()));
scan.setFilter(familyFilter);
public class HbaseFilterTest {
private static final String ZK_CONNECT_KEY = "hbase.zookeeper.quorum";
private static final String ZK_CONNECT_VALUE = "hadoop1:2181,hadoop2:2181,hadoop3:2181";
private static Connection conn = null;
private static Admin admin = null;
public static void main(String[] args) throws Exception {
Configuration conf = HBaseConfiguration.create();
conf.set(ZK_CONNECT_KEY, ZK_CONNECT_VALUE);
conn = ConnectionFactory.createConnection(conf);
admin = conn.getAdmin();
Table table = conn.getTable(TableName.valueOf("student"));
Scan scan = new Scan();
Filter familyFilter = new FamilyFilter(CompareOp.EQUAL, new BinaryComparator("info".getBytes()));
scan.setFilter(familyFilter);
ResultScanner resultScanner = table.getScanner(scan);
for(Result result : resultScanner) {
List<Cell> cells = result.listCells();
for(Cell cell : cells) {
System.out.println(cell);
}
}
}
}
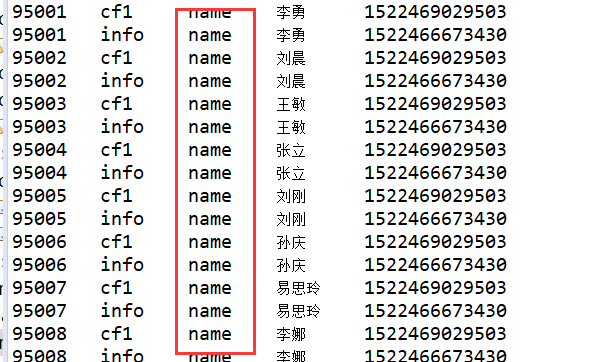
3、列过滤器 QualifierFilter
Filter qualifierFilter = new QualifierFilter(CompareOp.EQUAL, new BinaryComparator("name".getBytes()));
scan.setFilter(qualifierFilter);
public class HbaseFilterTest {
private static final String ZK_CONNECT_KEY = "hbase.zookeeper.quorum";
private static final String ZK_CONNECT_VALUE = "hadoop1:2181,hadoop2:2181,hadoop3:2181";
private static Connection conn = null;
private static Admin admin = null;
public static void main(String[] args) throws Exception {
Configuration conf = HBaseConfiguration.create();
conf.set(ZK_CONNECT_KEY, ZK_CONNECT_VALUE);
conn = ConnectionFactory.createConnection(conf);
admin = conn.getAdmin();
Table table = conn.getTable(TableName.valueOf("student"));
Scan scan = new Scan();
Filter qualifierFilter = new QualifierFilter(CompareOp.EQUAL, new BinaryComparator("name".getBytes()));
scan.setFilter(qualifierFilter);
ResultScanner resultScanner = table.getScanner(scan);
for(Result result : resultScanner) {
List<Cell> cells = result.listCells();
for(Cell cell : cells) {
System.out.println(cell);
}
}
}
}
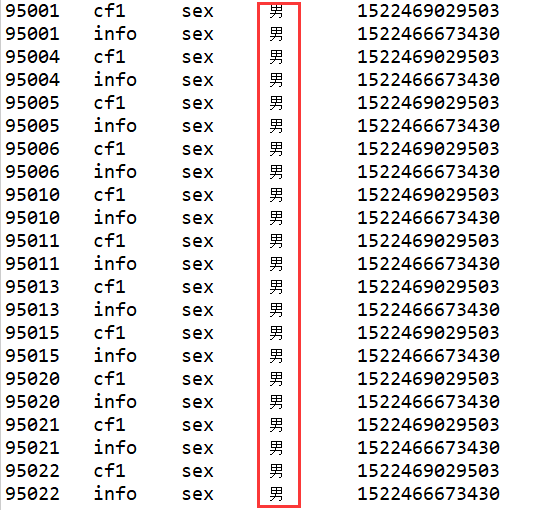
4、值过滤器 ValueFilter
Filter valueFilter = new ValueFilter(CompareOp.EQUAL, new SubstringComparator("男"));
scan.setFilter(valueFilter);
public class HbaseFilterTest {
private static final String ZK_CONNECT_KEY = "hbase.zookeeper.quorum";
private static final String ZK_CONNECT_VALUE = "hadoop1:2181,hadoop2:2181,hadoop3:2181";
private static Connection conn = null;
private static Admin admin = null;
public static void main(String[] args) throws Exception {
Configuration conf = HBaseConfiguration.create();
conf.set(ZK_CONNECT_KEY, ZK_CONNECT_VALUE);
conn = ConnectionFactory.createConnection(conf);
admin = conn.getAdmin();
Table table = conn.getTable(TableName.valueOf("student"));
Scan scan = new Scan();
Filter valueFilter = new ValueFilter(CompareOp.EQUAL, new SubstringComparator("男"));
scan.setFilter(valueFilter);
ResultScanner resultScanner = table.getScanner(scan);
for(Result result : resultScanner) {
List<Cell> cells = result.listCells();
for(Cell cell : cells) {
System.out.println(cell);
}
}
}
}
5、时间戳过滤器 TimestampsFilter
List<Long> list = new ArrayList<>();
list.add(1522469029503l);
TimestampsFilter timestampsFilter = new TimestampsFilter(list);
scan.setFilter(timestampsFilter);
public class HbaseFilterTest {
private static final String ZK_CONNECT_KEY = "hbase.zookeeper.quorum";
private static final String ZK_CONNECT_VALUE = "hadoop1:2181,hadoop2:2181,hadoop3:2181";
private static Connection conn = null;
private static Admin admin = null;
public static void main(String[] args) throws Exception {
Configuration conf = HBaseConfiguration.create();
conf.set(ZK_CONNECT_KEY, ZK_CONNECT_VALUE);
conn = ConnectionFactory.createConnection(conf);
admin = conn.getAdmin();
Table table = conn.getTable(TableName.valueOf("student"));
Scan scan = new Scan();
List<Long> list = new ArrayList<>();
list.add(1522469029503l);
TimestampsFilter timestampsFilter = new TimestampsFilter(list);
scan.setFilter(timestampsFilter);
ResultScanner resultScanner = table.getScanner(scan);
for(Result result : resultScanner) {
List<Cell> cells = result.listCells();
for(Cell cell : cells) {
System.out.println(Bytes.toString(cell.getRow()) + "\t" + Bytes.toString(cell.getFamily()) + "\t" + Bytes.toString(cell.getQualifier())
+ "\t" + Bytes.toString(cell.getValue()) + "\t" + cell.getTimestamp());
}
}
}
}
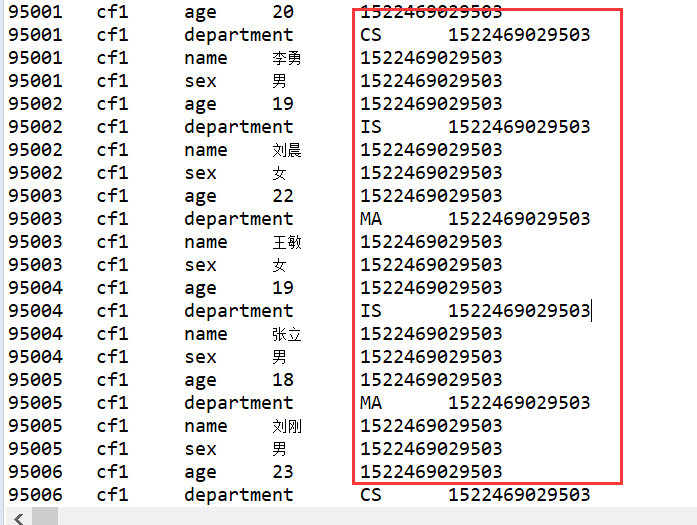
专用过滤器
1、单列值过滤器 SingleColumnValueFilter ----会返回满足条件的整行
SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter(
"info".getBytes(), //列簇
"name".getBytes(), //列
CompareOp.EQUAL,
new SubstringComparator("刘晨"));
//如果不设置为 true,则那些不包含指定 column 的行也会返回
singleColumnValueFilter.setFilterIfMissing(true);
scan.setFilter(singleColumnValueFilter);
public class HbaseFilterTest2 {
private static final String ZK_CONNECT_KEY = "hbase.zookeeper.quorum";
private static final String ZK_CONNECT_VALUE = "hadoop1:2181,hadoop2:2181,hadoop3:2181";
private static Connection conn = null;
private static Admin admin = null;
public static void main(String[] args) throws Exception {
Configuration conf = HBaseConfiguration.create();
conf.set(ZK_CONNECT_KEY, ZK_CONNECT_VALUE);
conn = ConnectionFactory.createConnection(conf);
admin = conn.getAdmin();
Table table = conn.getTable(TableName.valueOf("student"));
Scan scan = new Scan();
SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter(
"info".getBytes(),
"name".getBytes(),
CompareOp.EQUAL,
new SubstringComparator("刘晨"));
singleColumnValueFilter.setFilterIfMissing(true);
scan.setFilter(singleColumnValueFilter);
ResultScanner resultScanner = table.getScanner(scan);
for(Result result : resultScanner) {
List<Cell> cells = result.listCells();
for(Cell cell : cells) {
System.out.println(Bytes.toString(cell.getRow()) + "\t" + Bytes.toString(cell.getFamily()) + "\t" + Bytes.toString(cell.getQualifier())
+ "\t" + Bytes.toString(cell.getValue()) + "\t" + cell.getTimestamp());
}
}
}
}

2、单列值排除器 SingleColumnValueExcludeFilter
SingleColumnValueExcludeFilter singleColumnValueExcludeFilter = new SingleColumnValueExcludeFilter(
"info".getBytes(),
"name".getBytes(),
CompareOp.EQUAL,
new SubstringComparator("刘晨"));
singleColumnValueExcludeFilter.setFilterIfMissing(true); scan.setFilter(singleColumnValueExcludeFilter);
public class HbaseFilterTest2 {
private static final String ZK_CONNECT_KEY = "hbase.zookeeper.quorum";
private static final String ZK_CONNECT_VALUE = "hadoop1:2181,hadoop2:2181,hadoop3:2181";
private static Connection conn = null;
private static Admin admin = null;
public static void main(String[] args) throws Exception {
Configuration conf = HBaseConfiguration.create();
conf.set(ZK_CONNECT_KEY, ZK_CONNECT_VALUE);
conn = ConnectionFactory.createConnection(conf);
admin = conn.getAdmin();
Table table = conn.getTable(TableName.valueOf("student"));
Scan scan = new Scan();
SingleColumnValueExcludeFilter singleColumnValueExcludeFilter = new SingleColumnValueExcludeFilter(
"info".getBytes(),
"name".getBytes(),
CompareOp.EQUAL,
new SubstringComparator("刘晨"));
singleColumnValueExcludeFilter.setFilterIfMissing(true);
scan.setFilter(singleColumnValueExcludeFilter);
ResultScanner resultScanner = table.getScanner(scan);
for(Result result : resultScanner) {
List<Cell> cells = result.listCells();
for(Cell cell : cells) {
System.out.println(Bytes.toString(cell.getRow()) + "\t" + Bytes.toString(cell.getFamily()) + "\t" + Bytes.toString(cell.getQualifier())
+ "\t" + Bytes.toString(cell.getValue()) + "\t" + cell.getTimestamp());
}
}
}
}
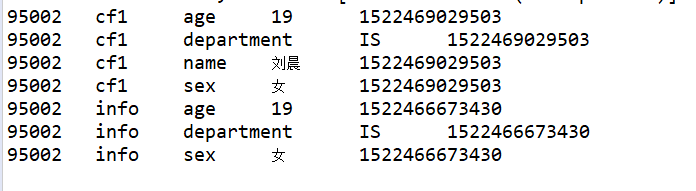
3、前缀过滤器 PrefixFilter----针对行键
PrefixFilter prefixFilter = new PrefixFilter("9501".getBytes());
scan.setFilter(prefixFilter);
public class HbaseFilterTest2 {
private static final String ZK_CONNECT_KEY = "hbase.zookeeper.quorum";
private static final String ZK_CONNECT_VALUE = "hadoop1:2181,hadoop2:2181,hadoop3:2181";
private static Connection conn = null;
private static Admin admin = null;
public static void main(String[] args) throws Exception {
Configuration conf = HBaseConfiguration.create();
conf.set(ZK_CONNECT_KEY, ZK_CONNECT_VALUE);
conn = ConnectionFactory.createConnection(conf);
admin = conn.getAdmin();
Table table = conn.getTable(TableName.valueOf("student"));
Scan scan = new Scan();
PrefixFilter prefixFilter = new PrefixFilter("9501".getBytes());
scan.setFilter(prefixFilter);
ResultScanner resultScanner = table.getScanner(scan);
for(Result result : resultScanner) {
List<Cell> cells = result.listCells();
for(Cell cell : cells) {
System.out.println(Bytes.toString(cell.getRow()) + "\t" + Bytes.toString(cell.getFamily()) + "\t" + Bytes.toString(cell.getQualifier())
+ "\t" + Bytes.toString(cell.getValue()) + "\t" + cell.getTimestamp());
}
}
}
}
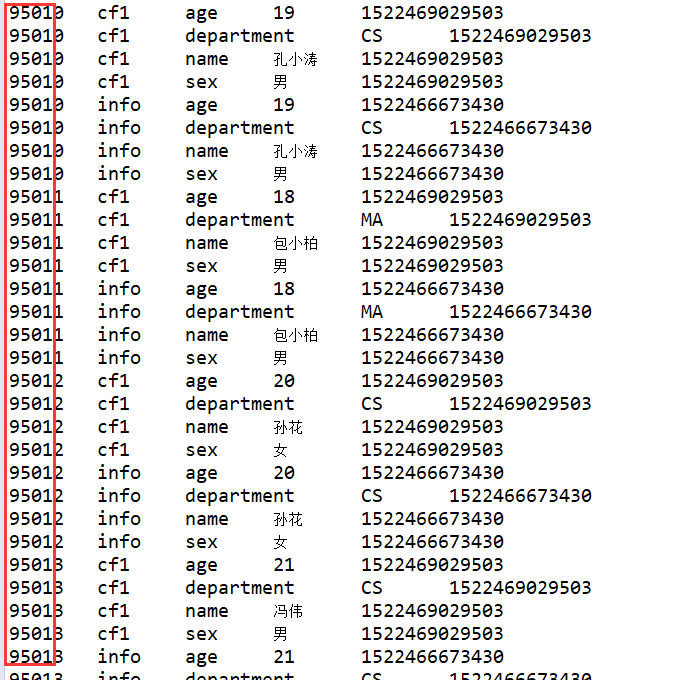
4、列前缀过滤器 ColumnPrefixFilter
ColumnPrefixFilter columnPrefixFilter = new ColumnPrefixFilter("name".getBytes());
scan.setFilter(columnPrefixFilter);
public class HbaseFilterTest2 {
private static final String ZK_CONNECT_KEY = "hbase.zookeeper.quorum";
private static final String ZK_CONNECT_VALUE = "hadoop1:2181,hadoop2:2181,hadoop3:2181";
private static Connection conn = null;
private static Admin admin = null;
public static void main(String[] args) throws Exception {
Configuration conf = HBaseConfiguration.create();
conf.set(ZK_CONNECT_KEY, ZK_CONNECT_VALUE);
conn = ConnectionFactory.createConnection(conf);
admin = conn.getAdmin();
Table table = conn.getTable(TableName.valueOf("student"));
Scan scan = new Scan();
ColumnPrefixFilter columnPrefixFilter = new ColumnPrefixFilter("name".getBytes());
scan.setFilter(columnPrefixFilter);
ResultScanner resultScanner = table.getScanner(scan);
for(Result result : resultScanner) {
List<Cell> cells = result.listCells();
for(Cell cell : cells) {
System.out.println(Bytes.toString(cell.getRow()) + "\t" + Bytes.toString(cell.getFamily()) + "\t" + Bytes.toString(cell.getQualifier())
+ "\t" + Bytes.toString(cell.getValue()) + "\t" + cell.getTimestamp());
}
}
}
}

5、分页过滤器 PageFilter
HBase学习之路 (六)过滤器的更多相关文章
- Hbase学习(三)过滤器 java API
Hbase学习(三)过滤器 HBase 的基本 API,包括增.删.改.查等. 增.删都是相对简单的操作,与传统的 RDBMS 相比,这里的查询操作略显苍白,只能根据特性的行键进行查询(Get)或者根 ...
- HBase 学习之路(七)——HBase过滤器详解
一.HBase过滤器简介 Hbase提供了种类丰富的过滤器(filter)来提高数据处理的效率,用户可以通过内置或自定义的过滤器来对数据进行过滤,所有的过滤器都在服务端生效,即谓词下推(predica ...
- HBase学习之路 (十一)HBase的协过滤器
协处理器—Coprocessor 1. 起源 Hbase 作为列族数据库最经常被人诟病的特性包括:无法轻易建立“二级索引”,难以执 行求和.计数.排序等操作.比如,在旧版本的(<0.92)Hba ...
- HBase 学习之路(六)——HBase Java API 的基本使用
一.简述 截至到目前(2019.04),HBase 有两个主要的版本,分别是1.x 和 2.x ,两个版本的Java API有所不同,1.x 中某些方法在2.x中被标识为@deprecated过时.所 ...
- HBase学习之路 (七)HBase 原理
系统架构 错误图解 这张图是有一个错误点:应该是每一个 RegionServer 就只有一个 HLog,而不是一个 Region 有一个 HLog. 正确图解 从HBase的架构图上可以看出,HBas ...
- HBase 学习之路(十)—— HBase的SQL中间层 Phoenix
一.Phoenix简介 Phoenix是HBase的开源SQL中间层,它允许你使用标准JDBC的方式来操作HBase上的数据.在Phoenix之前,如果你要访问HBase,只能调用它的Java API ...
- HBase 学习之路(八)——HBase协处理器
一.简述 在使用HBase时,如果你的数据量达到了数十亿行或数百万列,此时能否在查询中返回大量数据将受制于网络的带宽,即便网络状况允许,但是客户端的计算处理也未必能够满足要求.在这种情况下,协处理器( ...
- HBase 学习之路(一)—— HBase简介
一.Hadoop的局限 HBase是一个构建在Hadoop文件系统之上的面向列的数据库管理系统. 要想明白为什么产生HBase,就需要先了解一下Hadoop存在的限制?Hadoop可以通过HDFS来存 ...
- zigbee学习之路(六):Time3(查询方式)
一.前言 通过上次的学习,相信大家对cc2530单片机的定时器的使用有了一定的了解,今天我们来介绍定时器3的使用,为什么介绍定时器3呢,因为它和定时器4功能是差不多的,所以学会定时器3,就基本掌握了c ...
随机推荐
- SpringBoot+thymelates入门
在pom.xml当中加入这俩个依赖 <dependency> <groupId>org.springframework.boot</groupId> <art ...
- Java中响应结果工具类,可自定义响应码,内容,响应消息
创建响应状态码和说明枚举类 /** * 响应状态码和说明 */public enum CodeEnum { SUCCESS(0, "成功!"), FAIL(1, &qu ...
- 二进制GCD算法 减少%的时间消耗
/* 二进制求最大公约数.由于传统的GCD,使用了%,在计算机运行过程中要花费大量的时间,所以,采取二进制的求法,来减少时间的消耗. 算法: 当a,b都是偶数时: gcd(a,b)=2*gcd(a/2 ...
- SpingMVC_注解式开发_接收请求参数
一.逐个接收 import org.springframework.stereotype.Controller; import org.springframework.web.bind.annotat ...
- CDN和镜像站点比较
CDN和镜像站点是常用的提高网站访问速度的两种方式,但这两种方式具体是什么.二者间有什么相同和不同之处,本文对此做一粗浅介绍. 一.镜像站点 1.1定义 镜像网站是指将一个完全相同的网站源程序放到 ...
- Git 学习之git 起步(一)
起步 本章介绍开始使用 Git 前的相关知识.我们会先了解一些版本控制工具的历史背景,然后试着让 Git 在你的系统上跑起来,直到最后配置好,可以正常开始开发工作.读完本章,你就会明白为什么 Git ...
- JAVA 判断字符串是否可转化为JSONObject、JSONArray
有时,我们需要判断字符串在转化为JSON对象或者JSONArray时,我们可以使用JSONObject.parseObject和JSONArray.parseArray,但是有时候我们需要在转化之前判 ...
- JS基础(二)
21.标准事件模型的事件类型(包括4个子模块) HTMLEvents:接口为Event,支持的事件类型包括abort.blur.change.error.focus.load.resize.scrol ...
- JavaScript try-catch语句(错误处理)
错误处理在处理程序设计中的重要性是毋庸置疑的,任何有影响力的web应用程序都需要一套完善的错误处理机制.当然,大多数佼佼者确实做到了这一点,但通常只有服务器端应用程序才能做到如此.实际上,服务器端团队 ...
- C# 获取客户端信息 /asp.net/WebService/WebForm
Request.Browser.MajorVersion.ToString();//获取客户端浏览器的(主)版本号Request.Browser.Version.ToString(); //获取客 ...