Elasticsearch之如何合理分配索引分片
大多数ElasticSearch用户在创建索引时通用会问的一个重要问题是:我需要创建多少个分片?
在本文中, 我将介绍在分片分配时的一些权衡以及不同设置带来的性能影响. 如果想搞清晰你的分片策略以及如何优化,请继续往下阅读.
为什么要考虑分片数
分片分配是个很重要的概念, 很多用户对如何分片都有所疑惑, 当然是为了让分配更合理. 在生产环境中, 随着数据集的增长, 不合理的分配策略可能会给系统的扩展带来严重的问题.
同时, 这方面的文档介绍也非常少. 很多用户只想要明确的答案而不仅仅一个数字范围, 甚至都不关心随意的设置可能带来的问题.
当然,我也有一些答案. 不过先要看看它的定义和描述, 然后通过几个通用的案例来分别给出我们的建议.
分片定义
如果你刚接触ElasticSearch, 那么弄清楚它的几个术语和核心概念是非常必要的.
(如果你已经有ES的相关经验, 可以跳过这部分)
假设ElasticSearch集群的部署结构如下:
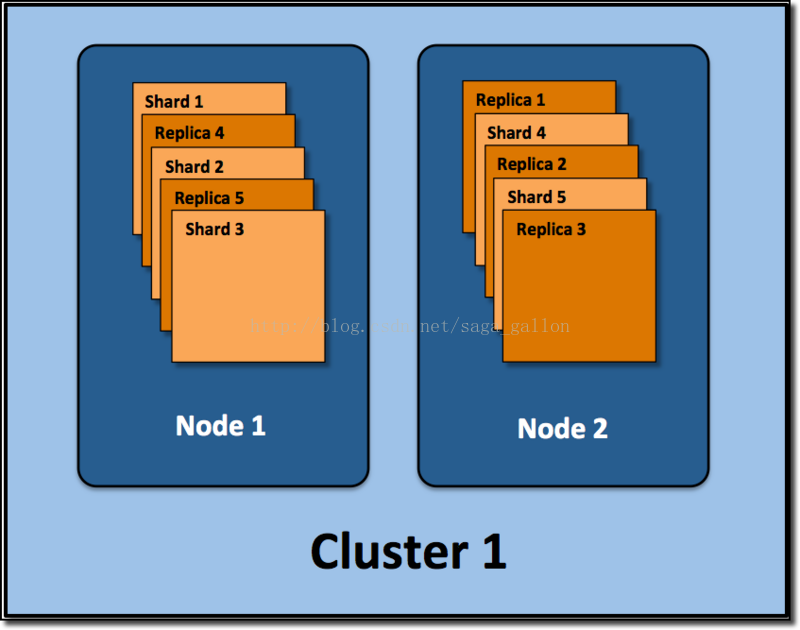
通过该图, 记住下面的几个定义:
集群(cluster):由一个或多个节点组成, 并通过集群名称与其他集群进行区分
节点(node):单个ElasticSearch实例. 通常一个节点运行在一个隔离的容器或虚拟机中
索引(index):在ES中, 索引是一组文档的集合
分片(shard):因为ES是个分布式的搜索引擎, 所以索引通常都会分解成不同部分, 而这些分布在不同节点的数据就是分片. ES自动管理和组织分片, 并在必要的时候对分片数据进行再平衡分配, 所以用户基本上不用担心分片的处理细节,一个分片默认最大文档数量是20亿.
副本(replica):ES默认为一个索引创建5个主分片, 并分别为其创建一个副本分片. 也就是说每个索引都由5个主分片成本, 而每个主分片都相应的有一个copy.
对于分布式搜索引擎来说, 分片及副本的分配将是高可用及快速搜索响应的设计核心.主分片与副本都能处理查询请求, 它们的唯一区别在于只有主分片才能处理索引请求.
在上图示例中, 我们的ElasticSearch集群有两个节点, 并使用了默认的分片配置. ES自动把这5个主分片分配到2个节点上, 而它们分别对应的副本则在完全不同的节点上. 对,就这是分布式的概念.
请记住, 索引的number_of_shards参数只对当前索引有效而不是对整个集群生效.对每个索引来讲, 该参数定义了当前索引的主分片数(而不是集群中所有的主分片数).
关于副本
本文中不会对ElasticSearch的副本做详细阐述. 如果想单独了解可参考这篇文章.
副本对搜索性能非常重要, 同时用户也可在任何时候添加或删除副本. 正如另篇文章所述, 额外的副本能给你带来更大的容量, 更高的呑吐能力及更强的故障恢复能力.
谨慎分配你的分片
当在ElasticSearch集群中配置好你的索引后, 你要明白在集群运行中你无法调整分片设置. 既便以后你发现需要调整分片数量, 你也只能新建创建并对数据进行重新索引(reindex)(虽然reindex会比较耗时, 但至少能保证你不会停机).
主分片的配置与硬盘分区很类似, 在对一块空的硬盘空间进行分区时, 会要求用户先进行数据备份, 然后配置新的分区, 最后把数据写到新的分区上.
2~3GB的静态数据集
分配分片时主要考虑的你的数据集的增长趋势.
我们也经常会看到一些不必要的过度分片场景. 从ES社区用户对这个热门主题(分片配置)的分享数据来看, 用户可能认为过度分配是个绝对安全的策略(这里讲的过度分配是指对特定数据集, 为每个索引分配了超出当前数据量(文档数)所需要的分片数).
Elastic在早期确实鼓吹过这种做法, 然后很多用户做的更为极端--例如分配1000个分片. 事实上, Elastic目前对此持有更谨慎的态度.
稍有富余是好的, 但过度分配分片却是大错特错. 具体定义多少分片很难有定论, 取决于用户的数据量和使用方式. 100个分片, 即便很少使用也可能是好的;而2个分片, 即便使用非常频繁, 也可能是多余的.
要知道, 你分配的每个分片都是有额外的成本的:
每个分片本质上就是一个Lucene索引, 因此会消耗相应的文件句柄, 内存和CPU资源
每个搜索请求会调度到索引的每个分片中. 如果分片分散在不同的节点倒是问题不太. 但当分片开始竞争相同的硬件资源时, 性能便会逐步下降
ES使用词频统计来计算相关性. 当然这些统计也会分配到各个分片上. 如果在大量分片上只维护了很少的数据, 则将导致最终的文档相关性较差
我们的客户通常认为随着业务的增长, 他们的数据量也会相应的增加, 所以很有必要为此做长期规划. 很多用户相信他们将会遇到暴发性增长(尽管大多数甚至都没有遇到过峰值), 当然也希望避免重新分片并减少可能的停机时间.
如果你真的担心数据的快速增长, 我们建议你多关心这条限制: ElasticSearch推荐的最大JVM堆空间是30~32G, 所以把你的分片最大容量限制为30GB, 然后再对分片数量做合理估算. 例如, 你认为你的数据能达到200GB, 我们推荐你最多分配7到8个分片.
总之, 不要现在就为你可能在三年后才能达到的10TB数据做过多分配. 如果真到那一天, 你也会很早感知到性能变化的.
尽管本部分并未详细讨论副本分片, 但我们推荐你保持适度的副本数并随时可做相应的增加. 如果你正在部署一个新的环境, 也许你可以参考我们的基于副本的集群的设计.这个集群有三个节点组成, 每个分片只分配了副本. 不过随着需求变化, 你可以轻易的调整副本数量.
大规模以及日益增长的数据场景
对大数据集, 我们非常鼓励你为索引多分配些分片--当然也要在合理范围内. 上面讲到的每个分片最好不超过30GB的原则依然使用.
不过, 你最好还是能描述出每个节点上只放一个索引分片的必要性. 在开始阶段, 一个好的方案是根据你的节点数量按照1.5~3倍的原则来创建分片. 例如,如果你有3个节点, 则推荐你创建的分片数最多不超过9(3x3)个.
随着数据量的增加,如果你通过集群状态API发现了问题,或者遭遇了性能退化,则只需要增加额外的节点即可. ES会自动帮你完成分片在不同节点上的分布平衡.
再强调一次, 虽然这里我们暂未涉及副本节点的介绍, 但上面的指导原则依然使用: 是否有必要在每个节点上只分配一个索引的分片. 另外, 如果给每个分片分配1个副本, 你所需的节点数将加倍. 如果需要为每个分片分配2个副本, 则需要3倍的节点数. 更多详情可以参考基于副本的集群.
Logstash
不知道你是否有基于日期的索引需求, 并且对索引数据的搜索场景非常少. 也许这些索引量将达到成百上千, 但每个索引的数据量只有1GB甚至更小. 对于这种类似场景, 我建议你只需要为索引分配1个分片.
如果使用ES的默认配置(5个分片), 并且使用Logstash按天生成索引, 那么6个月下来, 你拥有的分片数将达到890个. 再多的话, 你的集群将难以工作--除非你提供了更多(例如15个或更多)的节点.
想一下, 大部分的Logstash用户并不会频繁的进行搜索, 甚至每分钟都不会有一次查询. 所以这种场景, 推荐更为经济使用的设置. 在这种场景下, 搜索性能并不是第一要素, 所以并不需要很多副本. 维护单个副本用于数据冗余已经足够. 不过数据被不断载入到内存的比例相应也会变高.
如果你的索引只需要一个分片, 那么使用Logstash的配置可以在3节点的集群中维持运行6个月. 当然你至少需要使用4GB的内存, 不过建议使用8GB, 因为在多数据云平台中使用8GB内存会有明显的网速以及更少的资源共享.
总结
再次声明, 数据分片也是要有相应资源消耗,并且需要持续投入.
当索引拥有较多分片时, 为了组装查询结果, ES必须单独查询每个分片(当然并行的方式)并对结果进行合并. 所以高性能IO设备(SSDs)和多核处理器无疑对分片性能会有巨大帮助. 尽管如此, 你还是要多关心数据本身的大小,更新频率以及未来的状态. 在分片分配上并没有绝对的答案, 只希望你能从本文的讨论中受益.
附加分片处理实例
添加分片:
- //新增索引的同时添加分片,不使用默认分片,分片的数量
- //一般以(节点数*1.5或3倍)来计算,比如有4个节点,分片数量一般是6个到12个,每个分片一般分配一个副本
- PUT /testindex
- {
- "settings" : {
- "number_of_shards" : 12,
- "number_of_replicas" : 1
- }
- }
修改副本:
- //修改分片的副本数量
- PUT /testindex/_settings
- {
- "number_of_replicas" : 2
- }
转载自:https://blog.csdn.net/alan_liuyue/article/details/79585345
Elasticsearch之如何合理分配索引分片的更多相关文章
- 如何在Elasticsearch中解析未分配的分片(unassigned shards)
一.精确定位到有问题的shards 1.查看哪些分片未被分配 curl -XGET localhost:9200/_cat/shards?h=index,shard,prirep,state,unas ...
- Elasticsearch强制重置未分配的分片(unassigned)
强制重置未分片的分片,这个问题源自于Elasticsearch维护中,Node意外退出的场景. 意外退出后Elasticsearch由于网络原因或者jvm性能压力,未能短时间内分配分片. 看一下分片的 ...
- Elasticsearch 集群分配多少分片合理
Elasticsearch 是一个非常通用的平台,支持各种用户实例,并为组织数据和复制策略提供了极大的灵活性.但是,这种灵活性有时会使我们很难在早期确定如何很好地将数据组织成索引和分片,尤其是不熟悉 ...
- ElasticSearch优化系列六:索引过程
大家可能会遇到索引数据比较慢的过程.其实明白索引的原理就可以有针对性的进行优化.ES索引的过程到相对Lucene的索引过程多了分布式数据的扩展,而这ES主要是用tranlog进行各节点之间的数据平衡. ...
- 高效管理 Elasticsearch 中基于时间的索引——本质是在利用滚动模式做数据的冷热分离,热索引可以用ssd
高效管理 Elasticsearch 中基于时间的索引 转自:http://stormluke.me/es-managing-time-based-indices-efficiently/ 用 Ela ...
- Elasticsearch笔记七之setting,mapping,分片查询方式
Elasticsearch笔记七之setting,mapping,分片查询方式 setting 通过setting可以更改es配置可以用来修改副本数和分片数. 1:查看,通过curl或浏览器可以看到副 ...
- 一文带您了解 Elasticsearch 中,如何进行索引管理(图文教程)
欢迎关注笔者的公众号: 小哈学Java, 每日推送 Java 领域干货文章,关注即免费无套路附送 100G 海量学习.面试资源哟!! 个人网站: https://www.exception.site/ ...
- Docker安装ElasticSearch 以及使用LogStash实现索引库和数据库同步
1:下载 ElasticSearch 镜像 docker pull docker.io/elasticsearch:5.6.8 2:创建 ElasticSearch 容器: 注意:5.0默认分配jvm ...
- Elasticsearch-基础介绍及索引原理分析(转载)
最近在参与一个基于Elasticsearch作为底层数据框架提供大数据量(亿级)的实时统计查询的方案设计工作,花了些时间学习Elasticsearch的基础理论知识,整理了一下,希望能对Elastic ...
随机推荐
- Code Signal_练习题_reverseParentheses
You have a string s that consists of English letters, punctuation marks, whitespace characters, and ...
- 简单侧边栏js效果
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Ubuntu中利用rename批量重命名
1.简介: 通常在机器视觉的学习过程中,需要批量处理一些图片,通常会涉及到批量重命名的问题,可以利用rename命令快速实现图片的批量重命名 2.rename命令格式: rename [-v] [-n ...
- flutter 生命周期
前言:生命周期是一个组件加载到卸载的整个周期,熟悉生命周期可以让我们在合适的时机做该做的事情, flutter中的State生命周期和android以及React Native的生命周期类似. 先看一 ...
- linux rabbitmq 安装
下载 在安装 erlang 时使用的是源码包21.0版本:接着下载 rabbitmq-server/3.7.7 的源码包,编译时报错,说 erlang 版本号不满足条件,erlang版本>=19 ...
- mybatis 一对多 id标签作用
一对多 MyBatis的resultMap只用于配置结果如何映射,id的唯一作用就是在嵌套的映射配置时判断数据是否相同,当配置id标签时,MyBatis只需要逐条比较所有数据中id标签字段值是否相同即 ...
- redis介绍(2)简单安装
我分两种方式讲解 window 下载地址:https://github.com/MSOpenTech/redis/releases. Redis 支持 32 位和 64 位.这个需要根据你系统平台的实 ...
- linux 自启动 ,让生活更美好!!
systemctl enable svnserve.service systemctl enable iptables.service systemctl enable firewalld.servi ...
- 转:JavaBean 、 Serverlet 总结
Serverlet简介: Servlet(Server Applet),全称Java Servlet,未有中文译文.是用Java编写的服务器端程序.其主要功能在于交互式地浏览和修改数据,生成动态Web ...
- [翻译] INSSearchBar
INSSearchBar 效果: An animating search bar. 一个带动画效果的search bar. Originally developed for ShopNow v2. ( ...