Hadoop系列-MapReduce基础
由于在学习过程中对MapReduce有很大的困惑,所以这篇文章主要是针对MR的运行机制进行理解记录,主要结合网上几篇博客以及视频的讲解内容进行一个知识的梳理。
MapReduce on Yarn运行原理
Job提交
yarn由两个重要的jvm进程组成:ResourceManager、NodeManager。在客户端运行MapReduce Job之后,会首先向ResourceManager申请一个唯一的applicationID
判断Job的输出路径是否存在,如果存在则报错退出。这里之所以这样设计必须要求要一个新的输出路径的原因可以参考博文:https://www.cnblogs.com/sharpxiajun/p/3151395.html
根据输入文件计算input splits
将Job需要的依赖资源上传到HDFS,资源包括程序的jar包、计算好的splits(包括input splits数量、位置)等
向ResourceManager提交MapReduce Job
Job初始化
ResourceManager根据提交的资源请求在NodeManager上启动一个Container(yarn对资源的一个封装,就是包含一定cpu和内存的jvm)运行ApplicationMaster(MRAppMaster)。在这里需要说明两点,第一,可以在程序内部添加代码实现内存和cpu的配置(相对于在mapred-site.xml中配置较为灵活),ResourceManager根据资源情况选择合适的NodeManager启动一个Container来运行MRAppMaster。第二,之所以要在NodeManager上运行MRAppmaster是为了分散ResourceManager所在主机的运行压力。
MRAppmaste初始化job(多少MapTask、ReduceTask、都在哪些机器上跑)
读取inputsplits信息,为每个inputsplits创建MmapTask,根据程序里的配置确定需要创建多少个ReduceTask,MRAppmaste就是负责管理Task运行的
Task分配
MRAppmaste为每一个MapTask、ReduceTask向ResourceManager申请资源
Task执行
在申请完资源之后在数据所在的节点启动一个Container,在其中运行一个YarnChild
MapTask、ReduceTask都是运行在YarnChild上的,运行过程中会给MRAppmaste发送运行状态信息
以上基本描述了MapReduce on Yarn的一个基本运行过程,可以参考以下的图示进行理解。

MapReduce 的运行机制
宏观角度来看,整个MapReduce 程序运行的核心是MapTask和ReduceTask,分阶段来看主要分为三个阶段:map阶段、shuffle阶段、reduce阶段,这其中shuffle是核心。
map阶段:实际上是运行编写好的map方法就可以,一般会在相应的splits节点机器上本地运行。
shuffle阶段:shuffle阶段的操作横跨MapTask和ReduceTask
在经过map方法之后数据会以key-value的形式保存在内存中,如果在程序中设置了要用多个ReduceTask的话,接下来MapReduce提供Partitioner接口进行分区,也就是决定哪些数据会最终在哪一个ReduceTask上跑。默认情况下是HashPartitioner,也可以自定义。之后,需要将数据写入内存缓冲区中,缓冲区的作用是批量收集map结果。我们的key-value对以及Partition的结果都会被写入缓冲区。当然写入之前,key与value值都会被序列化成字节数组。缓冲区是一个环形数据结构中,使用环形数据结构是为了更有效地使用内存空间,在内存中放置尽可能多的数据。
这个缓冲区的默认大小是100MB,那么当数据量较大的时候,缓冲区就不够用了,这个时候就需要向磁盘中写入,但是这里不是说完全达到100MB才会触发向磁盘写的操作,默认情况下会有一个0.8的阈值系数,也就是说当占用了80MB的空间之后,就会触发向磁盘写的操作,称为spill。当溢写线程触发之后,需要对这80MB空间内的key做排序(Sort),在spill的过程中还可以利用剩余的20MB空间继续向缓存区存入数据,这两个过程之间互不影响。如果client设置过Combiner,那么现在就是使用Combiner的时候了,将有相同key的key/value对的value加起来,减少溢写到磁盘的数据量,但是combiner要慎用,使用它的原则是combiner的输入不会影响到reduce计算的最终输入,例如:如果计算只是求总数,最大值,最小值可以使用combiner,但是做平均值计算使用combiner的话,最终的reduce计算结果就会出错。每次spill操作也就是写入磁盘操作时候就会写一个溢出文件,也就是说在做map输出有几次spill就会产生多少个溢出文件。
由于最终的输出文件只有一个,所以需要将这些溢写文件归并到一起,这个过程就叫做Merge。这里可能也会出现多个相同key的情况,设置过combiner的话这里也会进行合并。
以上就是MapTask阶段的shuffle操作。
拉取MapTask的输出文件,主要通过HTTP的方式请求数据
merge和sort,数据拉取过来之后会先放在内存缓冲区中,与map端的spill类似也会向磁盘写如溢出文件,同时进行排序,最后在硬盘中合并为一个最终文件
reduce阶段:生成的最终文件作为reduce的输入,然后调用编写的reduce方法最终完成ReduceTask阶段。
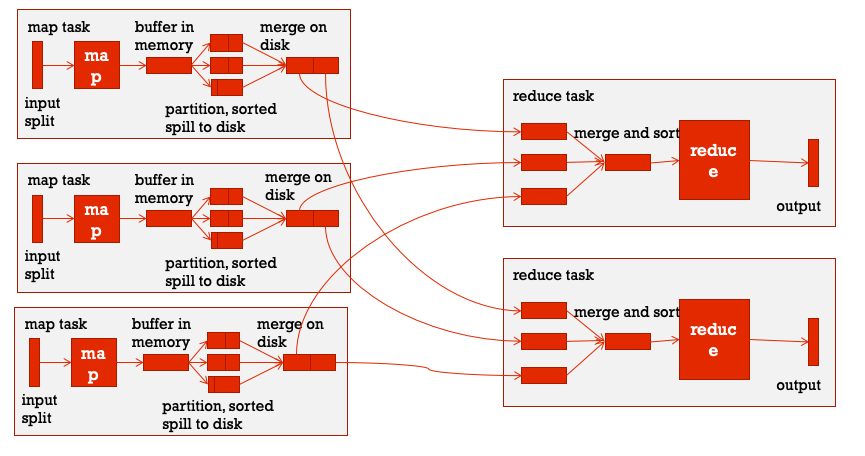
通过上述分析可以发现,在整个环节中shuffle的操作最为复杂真正涉及到内存以及磁盘的读写,所以shuffle阶段是一个主要系统调优的点。
参考:
【1】https://www.cnblogs.com/sharpxiajun/p/3151395.html
【2】https://blog.csdn.net/sunshingheavy/article/details/75849554
Hadoop系列-MapReduce基础的更多相关文章
- Hadoop系列-HDFS基础
基本原理 HDFS(Hadoop Distributed File System)是Hadoop的一个基础的分布式文件系统,这个分布式的概念主要体现在两个地方: 数据分块存储在多台主机 数据块采取冗余 ...
- 小记---------Hadoop的MapReduce基础知识
MapReduce是一种分布式计算模型,主要用于搜索领域,解决海量数据的计算问题 MR由两个阶段组成:Map和Reduce,用户只需要实现map()和reduce()两个函数,即可实现分布式计算. 两 ...
- Hadoop系列-zookeeper基础
目前是刚刚初学完zookeeper,这篇文章主要是简单的对一些基本的概念进行梳理强化. zookeeper基础概念的理解 有时候计算机领域很多名词都是从一长串英文提取首字母缩写而来,但很不幸zooke ...
- hadoop系列四:mapreduce的使用(二)
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
- [Hadoop in Action] 第4章 编写MapReduce基础程序
基于hadoop的专利数据处理示例 MapReduce程序框架 用于计数统计的MapReduce基础程序 支持用脚本语言编写MapReduce程序的hadoop流式API 用于提升性能的Combine ...
- hadoop系列三:mapreduce的使用(一)
转载请在页首明显处注明作者与出处 http://www.cnblogs.com/zhuxiaojie/p/7224772.html 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的 ...
- Hadoop 综合揭秘——MapReduce 基础编程(介绍 Combine、Partitioner、WritableComparable、WritableComparator 使用方式)
前言 本文主要介绍 MapReduce 的原理及开发,讲解如何利用 Combine.Partitioner.WritableComparator等组件对数据进行排序筛选聚合分组的功能.由于文章是针对开 ...
- 安装Hadoop系列 — 新建MapReduce项目
1.新建MR工程 依次点击 File → New → Ohter… 选择 “Map/Reduce Project”,然后输入项目名称:mrdemo,创建新项目: 2.(这步在以后的开发中可能 ...
- 从Hadoop骨架MapReduce在海量数据处理模式(包括淘宝技术架构)
从hadoop框架与MapReduce模式中谈海量数据处理 前言 几周前,当我最初听到,以致后来初次接触Hadoop与MapReduce这两个东西,我便稍显兴奋,认为它们非常是神奇.而神奇的东西常能勾 ...
随机推荐
- Python3 循环语句
Python3 循环语句 转来的 很适合小白 感谢作者 Python中的循环语句有 for 和 while. Python循环语句的控制结构图如下所示: while 循环 Python中wh ...
- LGWR和DBWn的触发条件
Rolling Forward(前滚) Oracle启动实例并加载数据库,然后通过Online Redologs中的重做日志,重现实例崩溃前对数据库的修改操作.在恢复过程中对于已经提交的事务,但尚未写 ...
- java基础(十) 数组类型
1. 数组类简介 在java中,数组也是一种引用类型,即是一种类. 我们来看一个例子,理解一下数组类: public static void main(String[] args) { Class ...
- gradle结合spring-boot生成可运行jar包,并打印日志
1.用gradle把springboot项目打包成jar 1.1 build.gradle 中添加 buildscript { repositories { mavenLocal() maven { ...
- Windows程序设计(Charles Petzold)HELLOWIN程序实现
/*-------------------------------------------------------------- HELLOWIN.C--DisPlays "Hello, W ...
- 缓冲区溢出基础实践(一)——shellcode 与 ret2libc
最近结合软件安全课程上学习的理论知识和网络资料,对缓冲区溢出漏洞的简单原理和利用技巧进行了一定的了解.这里主要记录笔者通过简单的示例程序实现缓冲区溢出漏洞利用的步骤,按由简至繁的顺序,依次描述简单的 ...
- JavaScript设计模式—工厂模式
工厂模式介绍 将new操作符单独进行封装,遇到new时,就要考虑是否该使用工厂模式 举一个生活当中的示例: 你要去购买汉堡,直接点餐,取餐,不会自己动手做,商店要“封装” 做汉堡的工作,做好直接给购买 ...
- 用python解析word文件(一):paragraph
太长了,我决定还是拆开三篇写. (一)段落篇(paragraph)(本篇) (二)表格篇(table) (三)样式篇(style) 选你所需即可.下面开始正文. 最近公司的项目,需要在页面上显示w ...
- BZOJ4180:字符串计数(SAM,二分,矩阵乘法)
Description SD有一名神犇叫做Oxer,他觉得字符串的题目都太水了,于是便出了一道题来虐蒟蒻yts1999. 他给出了一个字符串T,字符串T中有且仅有4种字符 'A', 'B', 'C', ...
- 【CodeChef】Prime Distance On Tree
vjudge 给定一棵边长都是\(1\)的树,求有多少条路径长度为质数 树上路径自然是点分治去搞,但是发现要求是长度为质数,总不能对每一个质数都判断一遍吧 自然是不行的,这个东西显然是一个卷积,我们合 ...