Hadoop系列-HDFS基础
基本原理
HDFS(Hadoop Distributed File System)是Hadoop的一个基础的分布式文件系统,这个分布式的概念主要体现在两个地方:
数据分块存储在多台主机
数据块采取冗余存储的方式提高数据的可用性
针对于以上的分布式存储概念,HDFS采用了master/slave的主从结构来构建整个存储系统。之所以可以通过分散的机器组成一个整体式的系统,这其中机器之间的相互通讯必不可少。对于一个程序在不同机器上的通讯,主要是通过远程系统调用RPC(remote procedure call)实现,不同的语言有不同的实现方式,而HDFS是运行于JVM基础上的,那么这里的通讯就是指不同机器的JVM进程之间的通讯。当然,底层的网络通讯主要是socket协议,在实际的工业场景中使用对socket进一步封装的netty实现。接下来,进一步针对数据块、namenode、datanode等进行说明。
数据块
每个计算机的磁盘都有一个默认的数据块(block)大小,这是进行数据读写的最小单位,文件系统通过管理磁盘上的数据块来管理文件。HDFS的block默认大小为128MB,但是于一般单一的磁盘文件系统不同的是,HDFS中小于一个块大小的文件不会占用整个block空间。例如:一个大小为1MB的文件存储在HDFS中时,在默认数据块是128MB的情况下还是只占用1MB,而不是128MB。决定数据传输速度的因素主要是磁盘驱动器的传输速率和文件寻址效率,如果数据块设置的足够大,那么文件寻址的效率就会变高,但也不是无限大,具体block的大小还需要根据具体的业务逻辑进行考虑。对文件进行块抽象的一个明显优点就是文件的大小不受限于任何一台单独的主机的磁盘容量限制,也就使得HDFS更适合数据量比较大的大数据场景。
namenode
整个HDFS集群有管理节点(namenode)和工作节点(datanode)。namenode主要维持两层关系:
第一层:整个集群的目录树结构以及文件的数据块列表,这两部分又可以总称为Namespace管理;
第二层:数据块在各个datanode的存储位置,这一部分称作块管理,除此之外块管理还会维护blockid到block的映射关系。

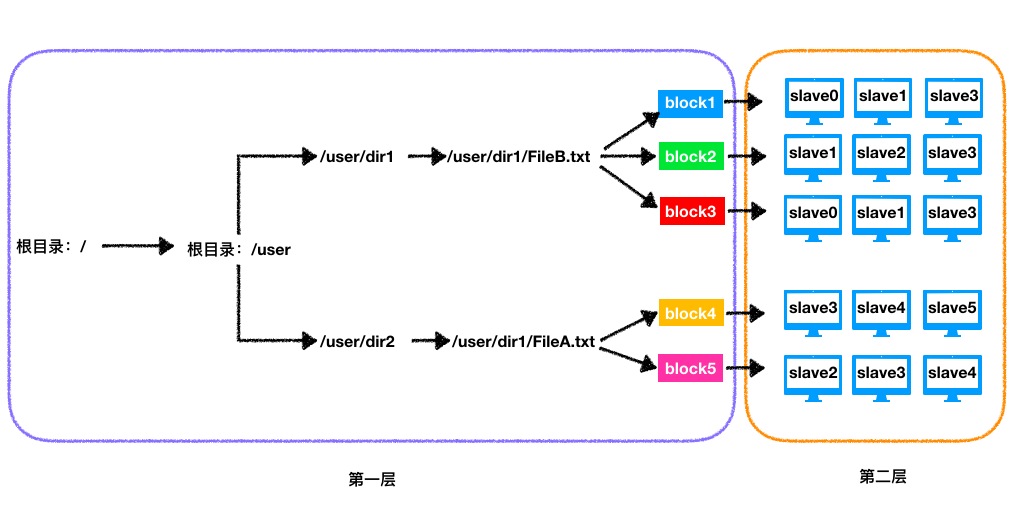
上图展示了namenode维持的两层关系,除了上述两层关系之外实际上namenode还会维持整个HDFS集群机架的拓扑信息以及所有datanode的信息(如主机名,版本等)。
为了使客户端访问的速度最快,以上的信息会保存在namenode主机的内存中。对于在内存中保存的数据,在断电后就会消失,这显然是不允许的,因此以上信息除了在内存中保存之外还需要在硬盘中保存一份,具体在硬盘中的保存形式为:
命名空间镜像文件(FSImage):某一时刻内存元数据的真实组织情况
编辑日志文件(EditsLog):该时刻后所有元数据的改动信息
需要说明的是,数据块与数据节点的信息虽然也会存储在namenode进程中,但是这个信息不会持久化到磁盘中,是在集群启动的时候namenode根据datanode上报的信息来构建的。
secondarynamenode
secondarynamenode主要是不定时的观察EditsLog、FSImage的情况,超过一定的阈值情况下对EditsLog和FSImage进行合并,形成新的FSImage文件。这样可以尽量减少namenode本身的负载。
datanode
datanode是主要的数据存储节点,这其中涉及了datanode与namenode的通讯情况。
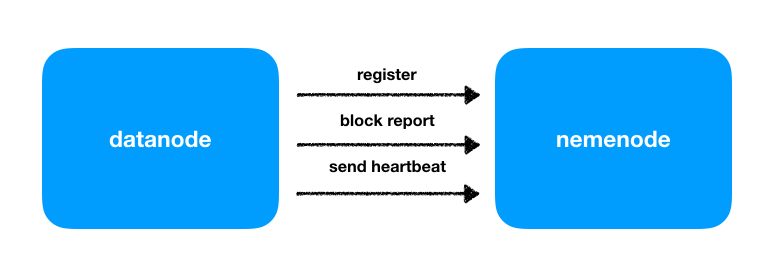


register:将datanode所在主机的信息(如主机名、内存、硬盘)告诉namenode,nemenode通过check相应的信息允许其称为集群中的一员;
block report:传输block信息给namenode,便于namenode可以维护数据块和数据节点之间的映射关系;
send heartbeat:
通过心跳机制保持与namenode的联系更新存储容量等信息
执行namenode通过heartbeat传输来的指令
federation
上文提到,namenode为了尽可能的使客户端的访问效率变高,会将所有的文件系统和数据块的引用信息保存在内存中,如果集群存储的文件量足够多,namenode内存的大小将限制集群的整个性能和可扩展能力。为此,在hadoop2.x中引入了federation机制,通过添加namenode实现扩展。
federation环境下,每隔namenode维护一个命名空间卷(namespace volume)由命名空间的元数据和数据块池组成,命名空间之间相互独立,互不通信。在这种情况下datanode被用作通用的数据存储设备,每个datanode要向集群中所有的namenode注册,且周期性的向所有namenode发送心跳和报告,并执行来自所有namenode的命令。但是,每个namenode只管理各自的block信息,如果一个namenode挂掉,虽然不会影响到其他的namenode,但是这个namenode管理的数据就不可访问,还是会存在SPOF(single point of failure,即单点故障问题)。
以上主要是个人对HDFS的一些基本概念的初步理解,如有错误还请各位大大们指正。
Hadoop系列-HDFS基础的更多相关文章
- 每天收获一点点------Hadoop之HDFS基础入门
一.HDFS出现的背景 随着社会的进步,需要处理数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是却不方便管理和维护—>因此,迫切需要一种系统来管理多 ...
- Hadoop(1): HDFS基础架构
1. What's HDFS? Hadoop Distributed File System is a block-structured file system where each file is ...
- Hadoop系列-MapReduce基础
由于在学习过程中对MapReduce有很大的困惑,所以这篇文章主要是针对MR的运行机制进行理解记录,主要结合网上几篇博客以及视频的讲解内容进行一个知识的梳理. MapReduce on Yarn运行原 ...
- Hadoop系列-zookeeper基础
目前是刚刚初学完zookeeper,这篇文章主要是简单的对一些基本的概念进行梳理强化. zookeeper基础概念的理解 有时候计算机领域很多名词都是从一长串英文提取首字母缩写而来,但很不幸zooke ...
- hadoop系列二:HDFS文件系统的命令及JAVA客户端API
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
- Hadoop 系列文章(二) Hadoop配置部署启动HDFS及本地模式运行MapReduce
接着上一篇文章,继续我们 hadoop 的入门案例. 1. 修改 core-site.xml 文件 [bamboo@hadoop-senior hadoop-2.5.0]$ vim etc/hadoo ...
- hadoop - hdfs 基础操作
hdfs --help # 所有参数 hdfs dfs -help # 运行文件系统命令在Hadoop文件系统 hdfs dfs -ls /logs # 查看 hdfs dfs -ls /user/ ...
- hadoop系列四:mapreduce的使用(二)
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
- 深入理解Hadoop之HDFS架构
Hadoop分布式文件系统(HDFS)是一种分布式文件系统.它与现有的分布式文件系统有许多相似之处.但是,与其他分布式文件系统的差异是值得我们注意的: HDFS具有高度容错能力,旨在部署在低成本硬件上 ...
随机推荐
- linux 下的python的最佳打开方式, you know?
IPython install IPython是Python的交互式Shell,提供了代码自动补完,自动缩进,高亮显示,执行Shell命令等非常有用的特性.特别是它的代码补完功能,例如:在输入zlib ...
- [转]实现Hive数据同步更新的shell脚本
引言: 上一篇文章<Sqoop1.4.4 实现将 Oracle10g 中的增量数据导入 Hive0.13.1 ,并更新Hive中的主表>http://www.linuxidc.com/Li ...
- Halo 的缔造者们在忙什么?
如果你自认为是一名主机游戏玩家,就一定知道 Halo.自 2001 年首代作品问世至今,十多年的磨炼已使得『光环』成为世界顶级的 FPS 游戏之一.<光环4>的推出,更让系列走向一个重要的 ...
- 使用HVTableView动态展开tableView中的cell
使用HVTableView动态展开tableView中的cell 效果: 源码: HVTableView.h 与 HVTableView.m // // HVTableView.h // HRVTab ...
- CSV输入输出
读取csv文件: import csv cf = open('D:\pywe.csv','rb') cf.readline() #读取标题行,光标移动到下一行(相当于调过标题行) for l in c ...
- SQLyog通过ssh隧道连接MySQL
1.简介 因为现在很多公司服务的数据库为了安全起见,都不允许直接连接其服务,而只能通过跳板机进行登陆到数据库.而ssh有一项非常有用的功能,即端口转发的隧道功能,让一些不安全的服务,像TCP.POP3 ...
- EXCHANGE 2013 队列
每当咱在Exchange里查看队列的时候,我们会看到队列分成好几个组,每个邮箱数据库都有自己的目标队列,DAG.AD站点也是,AD林也是一个队列,最后最多的就是外部SMTP域队列. 当传输服务处理队列 ...
- 进程&多道技术
进程 顾名思义,进程即正在执行的一个过程.进程是对正在运行程序的一个抽象. 进程的概念起源于操作系统,是操作系统最核心的概念,也是操作系统提供的最古老也是最重要的抽象概念之一.操作系统的其他所有内容都 ...
- 乘风破浪:LeetCode真题_003_Longest Substring Without Repeating Characters
乘风破浪:LeetCode真题_003_Longest Substring Without Repeating Characters 一.前言 在算法之中出现最多的就是字符串方面的问题了,关于字符串的 ...
- 给腾讯云Linux主机创建Swap文件
新买的腾讯云主机没有提供Swap分区 理由是由于主机经常因为内存使用率过高,频繁使用Swap,导致磁盘IO过高,服务器整体性能反而下降. 不过用户依然可以使用Swap文件的方式添加Swap. 方法如下 ...