flume 配置
[root@dtpweb data]#tar -zxvf apache-flume-1.7.0-bin.tar.gz
[root@dtpweb conf]# cp flume-env.sh.template flume-env.sh
修改java_home
[root@dtpweb conf]# cp flume-env.sh
export JAVA_HOME=/data/jdk
export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
flume.conf
#定义agent名, source,channel,sink的名称
a4.sources = r1
a4.channels = c1
a4.sinks = k1
#具体定义source
a4.sources.r1.type = spooldir
a4.sources.r1.spoolDir = /data/logs
#具体定义channel
a4.channels.c1.type = memory
a4.channels.c1.capacity = 10000
a4.channels.c1.transactionCapacity = 100
#定义拦截器,拦截一些无效的数据, 为消息添加时间戳,按照日志存入到当天的时间中
a4.sources.r1.interceptors = i1
a4.sources.r1.interceptors.i1 = org.apache.flume.interceptor.TimestampInterceptor$Builder
#定义sinks
a4.sinks.k1.type = hdfs
a4.sinks.k1.hdfs.path = hdfs://ns1/flume/%Y%m%d
a4.sinks.k1.hdfs.filePrefix = events
a4.sinks.k1.hdfs.fileType = DataStream
#不按照条数生成文件
a4.sinks.k1.hdfs.rollCount = 0
#HDFS上的文件达到128M时生成一个文件
a4.sinks.k1.hdfs.rollSize = 134217728
#HDFS上的文件达到60秒生成一个文件
a4.sinks.k1.hdfs.rollInterval = 60
#组装 source、channel、sink
a4.sources.r1.channels = c1
a4.sinks.k1.channels = c1
[root@dtpweb lib]# scp namenode:/data/hadoop/etc/hadoop/{core-site.xml,hdfs-site.xml} /data/apache-flume-1.7.0-bin/conf
[root@dtpweb bin]# ./flume-ng agent -n a4 -c ../conf -f ../conf/a4.conf -Dflume.root.logger=INFO,console
报错1:
java.lang.NoClassDefFoundError: org/apache/hadoop/io/SequenceFile$CompressionType
[root@dtpweb lib]# scp 192.168.20.184:/data/hadoop//share/hadoop/common/hadoop-common-2.7.3.jar ./
报错2:
java.lang.NoClassDefFoundError: org/apache/commons/configuration/Configuration
[root@dtpweb lib]# scp 192.168.20.184:/data/hadoop/share/hadoop/common/lib/commons-configuration-1.6.jar ./
[root@dtpweb lib]# scp 192.168.20.184:/data/hadoop/share/hadoop/common/lib/hadoop-auth-2.7.3.jar ./
[root@dtpweb lib]# scp 192.168.20.184:/data/hadoop/share/hadoop/common/lib/htrace-core-3.1.0-incubating.jar ./
报错3
Caused by: java.lang.NoClassDefFoundError: org/apache/commons/io/Charsets
[root@dtpweb lib]# scp 192.168.20.184:/data/hadoop/share/hadoop/common/lib/commons-io-2.4.jar ./
修改hdfs 属主,默认为hadoop
[hadoop@namenode bin]$ ./hdfs dfs -mkdir /flume
[hadoop@namenode bin]$ ./hdfs dfs -chown -R root /flume
[root@dtpweb bin]# mkdir /data/logs
[root@dtpweb bin]# ./flume-ng agent -n a4 -c ../conf -f ../conf/a4.conf -Dflume.root.logger=INFO,console
##############################################################################################################
!!!!使用root用户进行收集!!!!!
log4j ----- > kafka -----flume(收集所有的topic) -----> hdfs
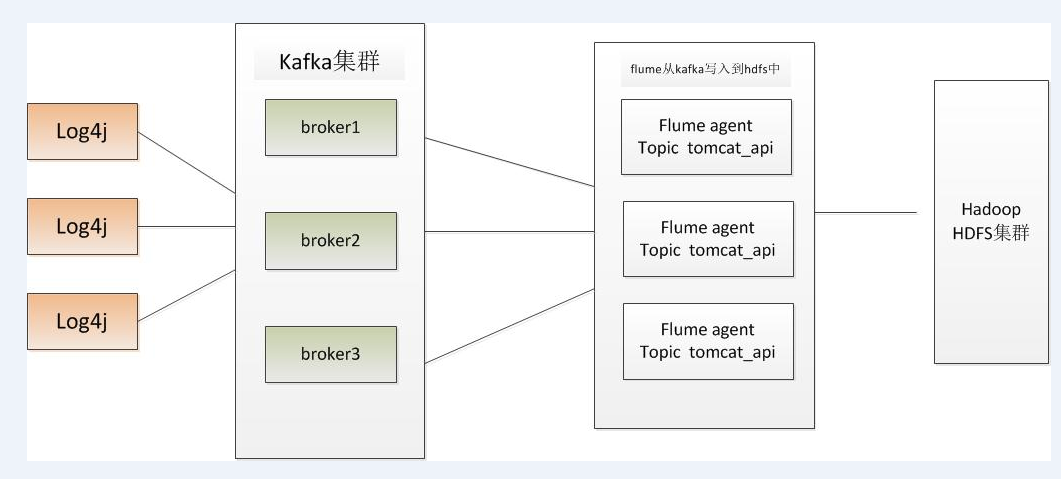
flume hosts主机名
192.168.20.206 kafka1
192.168.20.207 kafka2
192.168.20.208 kafka3
192.168.20.181 journalnode1
192.168.20.182 journalnode2
192.168.20.183 journalnode3
192.168.20.184 namenode
192.168.20.185 standbynamenode
192.168.20.186 datanode1
192.168.20.187 datanode2
192.168.20.188 datanode3
192.168.20.37 zookeeper1
192.168.20.38 zookeeper2
192.168.20.39 zookeeper3
192.168.20.189 rm1
192.168.20.193 rm2
192.168.20.190 hmaster1
192.168.20.191 hmaster2
192.168.20.194 hregionserver1
192.168.20.195 hregionserver2
kafaka建立topic id
[root@kafka1 bin]# ./kafka-topics.sh --create --topic testtopic1 --replication-factor 1 --partitions 1 --zookeeper zookeeper1:2181
[root@kafka1 bin]# ./kafka-console-producer.sh --broker-list kafka1:9092 --topic testtopic1
发送消........................
[root@kafka1 bin]# .
namenode节点修改hdfs 属主,默认为hadoop
[hadoop@namenode bin]$ ./hdfs dfs -mkdir /flume
[hadoop@namenode bin]$ ./hdfs dfs -chown -R root /flume
./kafka-console-consumer.sh --zookeeper zookeeper1:2181 --topic testtopic1 --from-beginning
cat /data/flume/conf/a5.conf
#定义agent名, source,channel,sink的名称
a5.sources = r1
a5.channels = c1
a5.sinks = k1
#auto.commit.enable = true
#具体定义source
a5.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
#a5.sources.r1.zookeeperConnect = zookeeper1:2181,zookeeper2:2181,zookeeper3:2181/testkafka
a5.sources.r1.kafka.bootstrap.servers = kafka1:9092,kafka2:9092,kafka3:9092
# 配置消费的kafka topic
a5.sources.r1.kafka.topics = testtopic1,testtopic2
#a5.sources.r1.topics.regex = testtopic[0-9]$
# 配置消费者组的id
#a5.sources.r1.kafka.consumer.group.id = flume
#a5.sources.r1.topic = itil_topic_4097
#a5.sources.r1.batchSize = 10000
#定义具体的channel
a5.channels.c1.type = memory
a5.channels.c1.capacity = 100000
a5.channels.c1.transactionCapacity = 10000
#定义具体的sink
a5.sinks.k1.type = hdfs
a4.sinks.k1.hdfs.filePrefix = testtoppic
a5.sinks.k1.hdfs.path = hdfs://ns1/flume/_%Y%m%d
a5.sinks.k1.hdfs.rollCount = 0
a5.sinks.k1.hdfs.rollSize = 134217728
a5.sinks.k1.hdfs.rollInterval = 60
a5.sinks.k1.hdfs.threadsPoolSize = 300
a5.sinks.k1.hdfs.callTimeout = 50000
#a5.sinks.k1.hdfs.writeFormat=Text
#a5.sinks.k1.hdfs.codeC = gzip
#a5.sinks.k1.hdfs.fileType = CompressedStream
#组装source、channel、sink
a5.sources.r1.channels = c1
a5.sinks.k1.channel = c1
[root@dtpweb bin]# ./flume-ng agent -n a4 -c ../conf -f ../conf/a4.conf -Dflume.root.logger=INFO,console
flume 配置的更多相关文章
- 关于flume配置加载(二)
为什么翻flume的代码,一方面是确实遇到了问题,另一方面是想翻一下flume的源码,看看有什么收获,现在收获还谈不上,因为要继续总结.不够已经够解决问题了,而且确实有好的代码,后续会继续慢慢分享,这 ...
- 关于flume配置加载
最近项目在用到flume,因此翻了下flume的代码, 启动脚本: nohup bin/flume-ng agent -n tsdbflume -c conf -f conf/配置文件.conf -D ...
- Flume配置Replicating Channel Selector
1 官网内容 上面的配置是r1获取到的内容会同时复制到c1 c2 c3 三个channel里面 2 详细配置信息 # Name the components on this agent a1.sour ...
- Flume配置Multiplexing Channel Selector
1 官网内容 上面配置的是根据不同的heder当中state值走不同的channels,如果是CZ就走c1 如果是US就走c2 c3 其他默认走c4 2 我的详细配置信息 一个监听http端口 然后 ...
- hadoop生态搭建(3节点)-09.flume配置
# http://archive.apache.org/dist/flume/1.8.0/# ===================================================== ...
- flume配置和说明(转)
Flume是什么 收集.聚合事件流数据的分布式框架 通常用于log数据 采用ad-hoc方案,明显优点如下: 可靠的.可伸缩.可管理.可定制.高性能 声明式配置,可以动态更新配置 提供上下文路由功能 ...
- flume 配置与使用
1.下载flume,解压到自建文件夹 2.修改flume-env.sh文件 在文件中添加JAVA_HOME 3.修改flume.conf 文件(原名好像不叫这个,我自己把模板名改了) 里面我自己配的( ...
- flume配置参数的意义
1.监控端口数据: flume启动: [bingo@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a1 --conf-file jo ...
- Flume配置Failover Sink Processor
1 官网内容 2 看一张图一目了然 3 详细配置 source配置文件 #配置文件: a1.sources= r1 a1.sinks= k1 k2 a1.channels= c1 #负载平衡 a1.s ...
随机推荐
- 情人节那点事,Power BI告诉你
情人节伴随着元宵节刚刚过去,Power BI团队就送给我们一份大礼,利用来自NRF(national retail foundation)和Bing搜索的数据,在Power BI中帮助我们发现在美国那 ...
- UC浏览器 分享到朋友圈和微信好友 分类: JavaScript 2015-04-28 14:45 615人阅读 评论(1) 收藏
用手机UC浏览器访问新浪微博,会注意到有这样的两个分享按钮: 在手机端浏览器里,点击分享按钮,就可以启动微信客户端并分享到微信.研究了下其源代码,存在这样的一个js:http://mjs.sinaim ...
- WPF中如何将ListViewItem双击事件绑定到Command
今天的博客将介绍如何实现ListViewItem双击事件绑定到ViewModel中的Command.实现方法借助了Style中的EventSetter,请看下面的详细代码: <ListView ...
- k-means聚类算法python实现
K-means聚类算法 算法优缺点: 优点:容易实现缺点:可能收敛到局部最小值,在大规模数据集上收敛较慢使用数据类型:数值型数据 算法思想 k-means算法实际上就是通过计算不同样本间的距离来判断他 ...
- Hibernate关联关系的映射
实体之间的关系 实体之间有三种关系 一对多:一个用户,生成多个订单,每一个订单只能属于一个用户 建表原则:在多的一方创建一个字段,作为外键,指向一的一方的主键 多对多:一个学生可以选择多门课程,一个课 ...
- Log4net用法
日记是我们在程序中经常用到的,故记于此 首先要下载Log4net.dll 官方网站:http://logging.apache.org/log4net/ vs里创建一个c#控制台程序,在App.con ...
- 分享一下自己用c++写的小地图
http://www.unrealchina.com/forum.php?mod=viewthread&tid=451&extra=&from=portal&page= ...
- 1.1 Quartz 2D 绘图
本文并非最终版本,如有更新或更正会第一时间置顶,联系方式详见文末 如果觉得本文内容过长,请前往本人 “简书” Quartz2D 绘图主要步骤: 1. 获取[图形上下文]对象 —— (拿到草稿纸 ...
- Leetcode Trapping Rain Water
Given n non-negative integers representing an elevation map where the width of each bar is 1, comput ...
- compass General 常用api学习[Sass和compass学习笔记]
compass 中一些常用api 包括一些浏览器hack @import "compass/utilities/general" Clearfix Clearfix 是用来清除浮动 ...