第三百三十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—Scrapy启动文件的配置—xpath表达式
第三百三十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—Scrapy启动文件的配置—xpath表达式
我们自定义一个main.py来作为启动文件
main.py
#!/usr/bin/env python
# -*- coding:utf8 -*- from scrapy.cmdline import execute #导入执行scrapy命令方法
import sys
import os sys.path.append(os.path.join(os.getcwd())) #给Python解释器,添加模块新路径 ,将main.py文件所在目录添加到Python解释器 execute(['scrapy', 'crawl', 'pach', '--nolog']) #执行scrapy命令
爬虫文件
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request
import urllib.response
from lxml import etree
import re class PachSpider(scrapy.Spider):
name = 'pach'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/all-posts/'] def parse(self, response):
pass
xpath表达式
1、
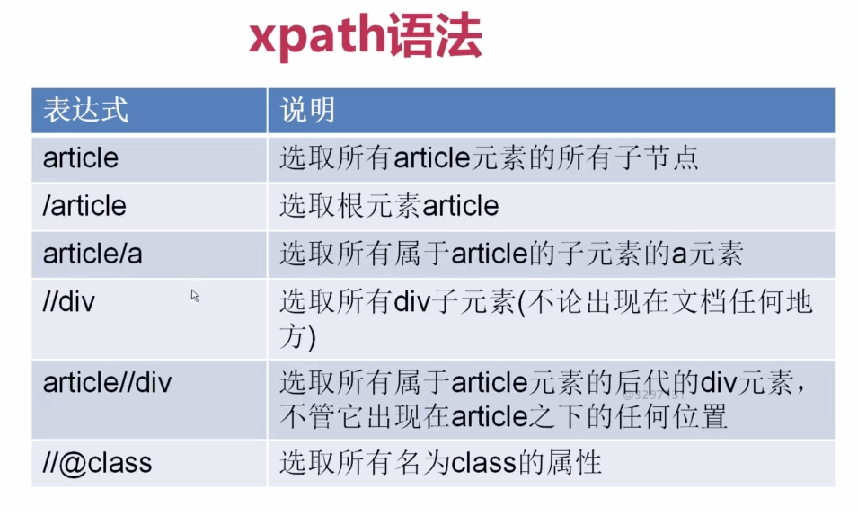
2、
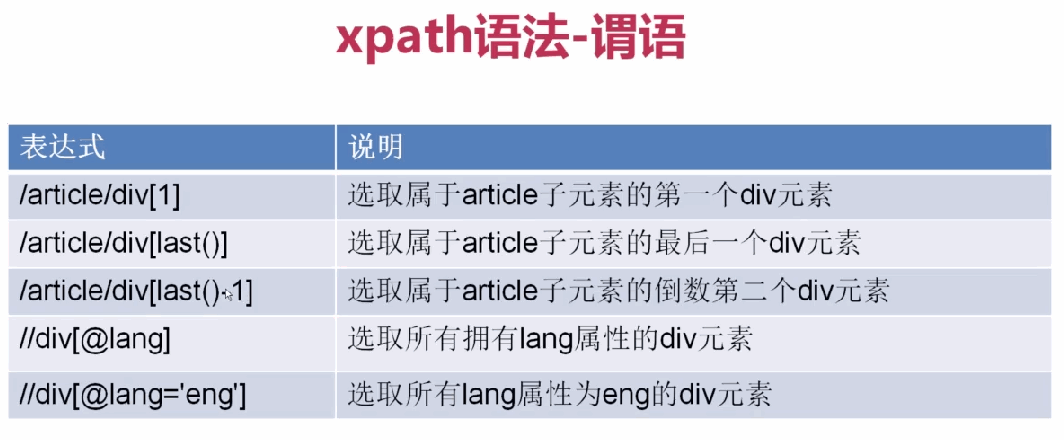
3、

基本使用
allowed_domains设置爬虫起始域名
start_urls设置爬虫起始url地址
parse(response)默认爬虫回调函数,response返回的是爬虫获取到的html信息对象,里面封装了一些关于htnl信息的方法和属性
responsehtml信息对象下的方法和属性
response.url获取抓取的rul
response.body获取网页内容
response.body_as_unicode()获取网站内容unicode编码
xpath()方法,用xpath表达式过滤节点
extract()方法,获取过滤后的数据,返回列表
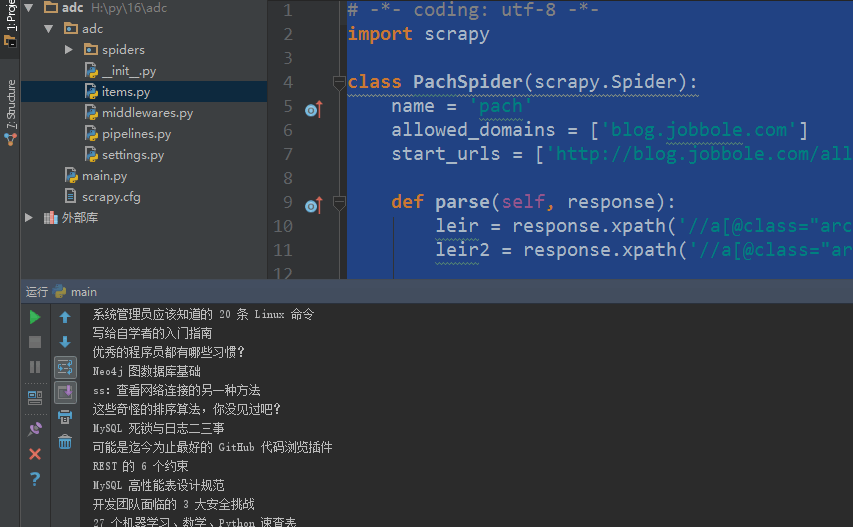
# -*- coding: utf-8 -*-
import scrapy class PachSpider(scrapy.Spider):
name = 'pach'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/all-posts/'] def parse(self, response):
leir = response.xpath('//a[@class="archive-title"]/text()').extract() #获取指定标题
leir2 = response.xpath('//a[@class="archive-title"]/@href ').extract() #获取指定url print(response.url) #获取抓取的rul
print(response.body) #获取网页内容
print(response.body_as_unicode()) #获取网站内容unicode编码 for i in leir:
print(i)
for i in leir2:
print(i)
第三百三十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—Scrapy启动文件的配置—xpath表达式的更多相关文章
- 第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索的自动补全功能
第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—用Django实现搜索的自动补全功能 elasticsearch(搜索引擎)提供了自动补全接口 官方说明:https://www.e ...
- 第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作
第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作 注意:前面讲到的各种操作都是一次http请求操作一条数据,如果想 ...
- 第三百五十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—将bloomfilter(布隆过滤器)集成到scrapy-redis中
第三百五十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—将bloomfilter(布隆过滤器)集成到scrapy-redis中,判断URL是否重复 布隆过滤器(Bloom Filter)详 ...
- 第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启
第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启 scrapy的每一个爬虫,暂停时可以记录暂停状态以及爬取了哪些url,重启时可以从暂停状态开始爬取过的UR ...
- 第三百七十九节,Django+Xadmin打造上线标准的在线教育平台—xadmin的安装
第三百七十九节,Django+Xadmin打造上线标准的在线教育平台—xadmin的安装 xadmin介绍 xadmin是基于Django的admin开发的更完善的后台管理系统,页面基于Bootstr ...
- 第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理—用户代理和ip代理结合应用
第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理 使用IP代理 ProxyHandler()格式化IP,第一个参数,请求目标可能是http或者https,对应设置build_opener ...
- 第三百八十九节,Django+Xadmin打造上线标准的在线教育平台—列表筛选结合分页
第三百八十九节,Django+Xadmin打造上线标准的在线教育平台—列表筛选结合分页 根据用户的筛选条件来结合分页 实现原理就是,当用户点击一个筛选条件时,通过get请求方式传参将筛选的id或者值, ...
- 第三百三十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—深度优先与广度优先原理
第三百三十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—深度优先与广度优先原理 网站树形结构 深度优先 是从左到右深度进行爬取的,以深度为准则从左到右的执行(递归方式实现)Scrapy默认 ...
- 第三百四十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—通过自定义中间件全局随机更换代理IP
第三百四十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—通过自定义中间件全局随机更换代理IP 设置代理ip只需要,自定义一个中间件,重写process_request方法, request ...
- 第三百四十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy模拟登陆和知乎倒立文字验证码识别
第三百四十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy模拟登陆和知乎倒立文字验证码识别 第一步.首先下载,大神者也的倒立文字验证码识别程序 下载地址:https://gith ...
随机推荐
- 【小白的CFD之旅】25 二维还是三维
小白最近逛图书馆,发现最近关于Fluent的书是越来越多了,而且还发现这些关于Fluent教材中的案例都大同小异.小白接受小牛师兄的建议,找了一本结构比较鲜明的书照着上面的案例就练了起来.不过当练习的 ...
- adaptive query processing
http://www.cs.umd.edu/~amol/talks/VLDB07-AQP-Tutorial.pdf https://www.cis.upenn.edu/~zives/research/ ...
- 深入详解JVM内存模型与JVM参数详细配置
对于大多数应用来说,Java 堆(Java Heap)是Java 虚拟机所管理的内存中最大的一块.Java 堆是被所有线程共享的一块内存区域,在虚拟机启动时创建. JVM内存结构 由上图可以清楚的看到 ...
- linux怎么关闭iptables linux如何关闭防火墙
Linux系统下面自带了防火墙iptables,iptables可以设置很多安全规则.但是如果配置错误很容易导致各种网络问题,那么如果要关闭禁用防火墙怎么操作呢,咗嚛本经验以centos系统为例演示如 ...
- 每日英语:Nanjing's New Sifang Art Museum Illustrates China's Cultural Boom
In a forest on the outskirts of this former Chinese capital, 58-year-old real-estate developer Lu Ju ...
- java 多线程 25 :线程和线程组的异常处理
线程中出现异常 从上面代码可以看出来处理线程的异常 设置异常的两种方式 1.全局异常,也是静态异常,是个静态方法 , 类.setDefaultUncaughtExceptionHandler() 2. ...
- Javascript 中ajax实现前台向后台交互
第一种情况:前台传入字符串参数 后台返回json字符串.或是json数组 代码如下: 前台: $.ajax({ url: "xxx/xxx.action", data: &quo ...
- 6. 集成学习(Ensemble Learning)算法比较
1. 集成学习(Ensemble Learning)原理 2. 集成学习(Ensemble Learning)Bagging 3. 集成学习(Ensemble Learning)随机森林(Random ...
- stdafx
Standard Application Fram Extend没有函数库,只是定义了一些环境参数,使得编译出来的程序能在32位的操作系统环境下运行. Windows和MFC的include文件都非常 ...
- 基于bootstrup3全屏宽度的响应式jQuery幻灯片特效
这是一款效果非常酷的基于Bootstrup3.x和HTML5的响应式全屏宽度jQuery幻灯片特效.该幻灯片能自适应屏幕的宽度,使用HTML5的data属性来指定幻灯片所需的各种属性.使用简单,界面美 ...