第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启
第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启
scrapy的每一个爬虫,暂停时可以记录暂停状态以及爬取了哪些url,重启时可以从暂停状态开始爬取过的URL不在爬取
实现暂停与重启记录状态
1、首先cd进入到scrapy项目里
2、在scrapy项目里创建保存记录信息的文件夹
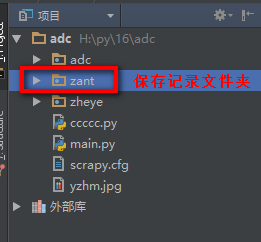
3、执行命令:
scrapy crawl 爬虫名称 -s JOBDIR=保存记录信息的路径
如:scrapy crawl cnblogs -s JOBDIR=zant/001
执行命令会启动指定爬虫,并且记录状态到指定目录
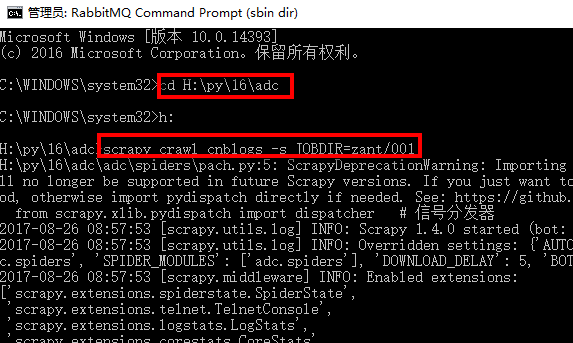
爬虫已经启动,我们可以按键盘上的ctrl+c停止爬虫
停止后我们看一下记录文件夹,会多出3个文件
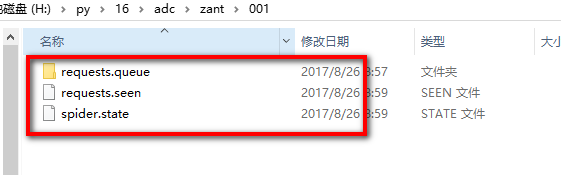
其中的requests.queue文件夹里的p0文件就是URL记录文件,这个文件存在就说明还有未完成的URL,当所有URL完成后会自动删除此文件
当我们重新执行命令:scrapy crawl cnblogs -s JOBDIR=zant/001 时爬虫会根据p0文件从停止的地方开始继续爬取,
第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启的更多相关文章
- 第三百五十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—chrome谷歌浏览器无界面运行、scrapy-splash、splinter
第三百五十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—chrome谷歌浏览器无界面运行.scrapy-splash. splinter 1.chrome谷歌浏览器无界面运行 chrome ...
- 第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目
第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目 scrapyd模块是专门用于部署scrapy项目的,可以部署和管理scrapy项目 下载地址:h ...
- 第三百六十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作、增、删、改、查
第三百六十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作.增.删.改.查 elasticsearch(搜索引擎)基本的索引 ...
- 第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询 1.elasticsearch(搜索引擎)的查询 elasticsearch是功能 ...
- 第三百五十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy信号详解
第三百五十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy信号详解 信号一般使用信号分发器dispatcher.connect(),来设置信号,和信号触发函数,当捕获到信号时执行 ...
- 第三百四十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图
第三百四十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图 1.基本概念 2.反爬虫的目的 3.爬虫和反爬的对抗过程以及策略 scra ...
- 第三百四十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—通过downloadmiddleware中间件全局随机更换user-agent浏览器用户代理
第三百四十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—通过downloadmiddleware随机更换user-agent浏览器用户代理 downloadmiddleware介绍中间件是 ...
- 第三百四十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器
第三百四十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器 编写spiders爬虫文件循环 ...
- Python分布式爬虫打造搜索引擎完整版-基于Scrapy、Redis、elasticsearch和django打造一个完整的搜索引擎网站
Python分布式爬虫打造搜索引擎 基于Scrapy.Redis.elasticsearch和django打造一个完整的搜索引擎网站 https://github.com/mtianyan/Artic ...
- 四十六 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
前面我们讲到的elasticsearch(搜索引擎)操作,如:增.删.改.查等操作都是用的elasticsearch的语言命令,就像sql命令一样,当然elasticsearch官方也提供了一个pyt ...
随机推荐
- VMWare ESX/ESXi 虚拟机硬盘的厚置备(Thick Provision)与精简置备(Thin Provision)的转换
VMWare ESX/ESXi 有两种硬盘置备方式,厚制备(thick)和精简置备(Thin) 有时可能会由于性能问题或磁盘空间需要将虚拟机磁盘在两种模式间进行互转,虽然在虚拟机配置页面是没有办法修改 ...
- Oracle字段类型及存储(一)
Oracle中2000个byte,并不是2000个字符的意思,1个字符在Oracle中可能是1个byte到4个byte不等,需看数据库字符集的设置了. 对GBK字符集而言,ASCII码中128个字符使 ...
- 再论FreeRTOS中的configTOTAL_HEAP_SIZE
关于任务栈和系统栈的基础知识,可以参考之前的随笔.(点击这里) 这里再次说明:#define configTOTAL_HEAP_SIZE ( ( size_t ) ( 17 * 1024 ) ) 这个 ...
- Highcharts 多个Y轴动态刷新数据
效果图: js代码: $(function() { $(document).ready(function() { Highcharts.setOptions({ global: { useUTC: f ...
- Web图形开发
Web项目开发过程中要找到完美的图形解决方案比较困难,只能根据自己的需要,选择自己最合适的画图方案. Web图表一般有以下几种做法: (1)使用客户端控件技术 (2)使用服务器端生成图片 (3)使用富 ...
- 1. CNN卷积网络-初识
1. CNN卷积网络-初识 2. CNN卷积网络-前向传播算法 3. CNN卷积网络-反向更新 1. 前言 卷积神经网络是一种特殊的深层的神经网络模型,它的特殊性体现在两个方面, 它的神经元间的连接是 ...
- 基于HTML5手机登录注册表单代码
分享一款基于HTML5手机登录注册表单代码.这是一款鼠标点击注册登录按钮弹出表单,适合移动端使用.效果图如下: 在线预览 源码下载 实现的代码. html代码: <div class=&qu ...
- 基于jQuery实现滚动新闻代码下载
分享一款基于jQuery实现滚动新闻代码下载.这是一款基于bootstrup 3实现的响应式jQuery滚动新闻插件.效果图如下: 在线预览 源码下载 实现的代码. html代码: <div ...
- mysql行转列转换
http://blog.csdn.net/sinat_27406925/article/details/77507478 mysql 行列转换 ,在项目中应用的极其频繁,尤其是一些金融项目里的报表.其 ...
- 【Unity】JsonUtility解析集合(collections)类型(List)
Unity自带的Json解析工具类JsonUtility居然没有API用于解析集合类型,也太鬼扯了吧. https://stackoverflow.com/questions/36239705/ser ...