第三百三十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—Scrapy启动文件的配置—xpath表达式
第三百三十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—Scrapy启动文件的配置—xpath表达式
我们自定义一个main.py来作为启动文件
main.py
#!/usr/bin/env python
# -*- coding:utf8 -*- from scrapy.cmdline import execute #导入执行scrapy命令方法
import sys
import os sys.path.append(os.path.join(os.getcwd())) #给Python解释器,添加模块新路径 ,将main.py文件所在目录添加到Python解释器 execute(['scrapy', 'crawl', 'pach', '--nolog']) #执行scrapy命令
爬虫文件
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request
import urllib.response
from lxml import etree
import re class PachSpider(scrapy.Spider):
name = 'pach'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/all-posts/'] def parse(self, response):
pass
xpath表达式
1、
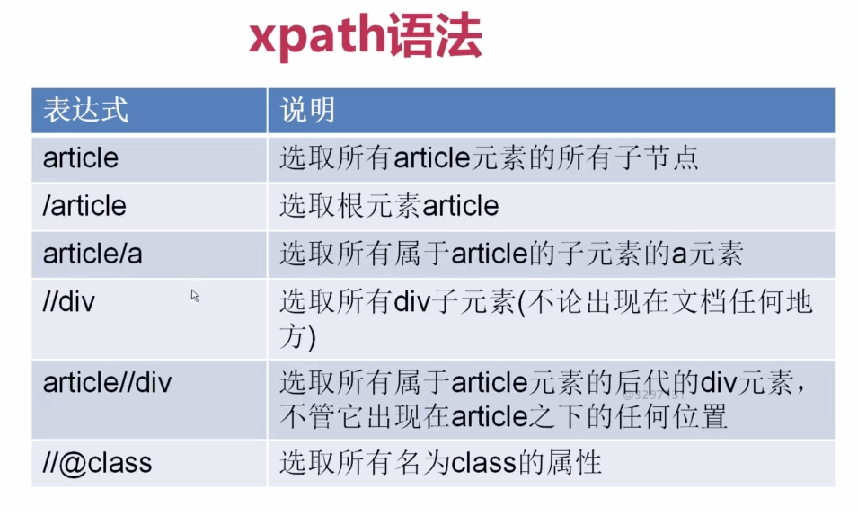
2、
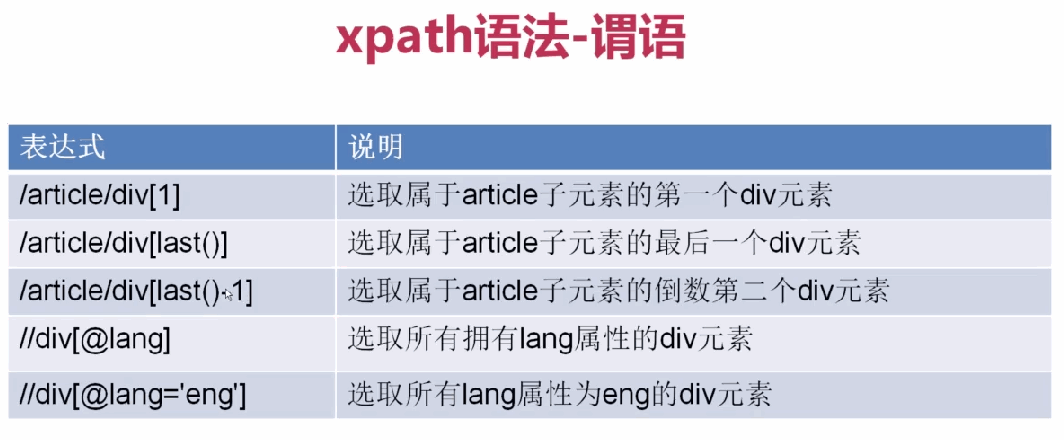
3、

基本使用
allowed_domains设置爬虫起始域名
start_urls设置爬虫起始url地址
parse(response)默认爬虫回调函数,response返回的是爬虫获取到的html信息对象,里面封装了一些关于htnl信息的方法和属性
responsehtml信息对象下的方法和属性
response.url获取抓取的rul
response.body获取网页内容
response.body_as_unicode()获取网站内容unicode编码
xpath()方法,用xpath表达式过滤节点
extract()方法,获取过滤后的数据,返回列表
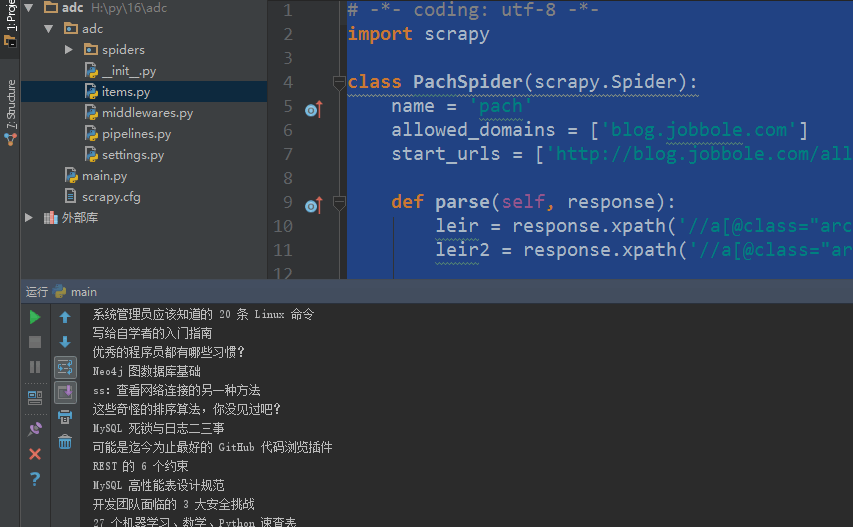
# -*- coding: utf-8 -*-
import scrapy class PachSpider(scrapy.Spider):
name = 'pach'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/all-posts/'] def parse(self, response):
leir = response.xpath('//a[@class="archive-title"]/text()').extract() #获取指定标题
leir2 = response.xpath('//a[@class="archive-title"]/@href ').extract() #获取指定url print(response.url) #获取抓取的rul
print(response.body) #获取网页内容
print(response.body_as_unicode()) #获取网站内容unicode编码 for i in leir:
print(i)
for i in leir2:
print(i)
第三百三十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—Scrapy启动文件的配置—xpath表达式的更多相关文章
- 第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索的自动补全功能
第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—用Django实现搜索的自动补全功能 elasticsearch(搜索引擎)提供了自动补全接口 官方说明:https://www.e ...
- 第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作
第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作 注意:前面讲到的各种操作都是一次http请求操作一条数据,如果想 ...
- 第三百五十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—将bloomfilter(布隆过滤器)集成到scrapy-redis中
第三百五十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—将bloomfilter(布隆过滤器)集成到scrapy-redis中,判断URL是否重复 布隆过滤器(Bloom Filter)详 ...
- 第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启
第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启 scrapy的每一个爬虫,暂停时可以记录暂停状态以及爬取了哪些url,重启时可以从暂停状态开始爬取过的UR ...
- 第三百七十九节,Django+Xadmin打造上线标准的在线教育平台—xadmin的安装
第三百七十九节,Django+Xadmin打造上线标准的在线教育平台—xadmin的安装 xadmin介绍 xadmin是基于Django的admin开发的更完善的后台管理系统,页面基于Bootstr ...
- 第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理—用户代理和ip代理结合应用
第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理 使用IP代理 ProxyHandler()格式化IP,第一个参数,请求目标可能是http或者https,对应设置build_opener ...
- 第三百八十九节,Django+Xadmin打造上线标准的在线教育平台—列表筛选结合分页
第三百八十九节,Django+Xadmin打造上线标准的在线教育平台—列表筛选结合分页 根据用户的筛选条件来结合分页 实现原理就是,当用户点击一个筛选条件时,通过get请求方式传参将筛选的id或者值, ...
- 第三百三十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—深度优先与广度优先原理
第三百三十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—深度优先与广度优先原理 网站树形结构 深度优先 是从左到右深度进行爬取的,以深度为准则从左到右的执行(递归方式实现)Scrapy默认 ...
- 第三百四十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—通过自定义中间件全局随机更换代理IP
第三百四十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—通过自定义中间件全局随机更换代理IP 设置代理ip只需要,自定义一个中间件,重写process_request方法, request ...
- 第三百四十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy模拟登陆和知乎倒立文字验证码识别
第三百四十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy模拟登陆和知乎倒立文字验证码识别 第一步.首先下载,大神者也的倒立文字验证码识别程序 下载地址:https://gith ...
随机推荐
- 每日英语:The Risks of Big Data for Companies
Big data. It's the latest IT buzzword, and it isn't hard to see why. The ability to parse more infor ...
- App store 应用审核由于 IPv6 网络问题被拒的一点分析
App store 应用审核由于 IPv6 网络问题被拒的一点分析 六月以后陆续有一些软件提交市场的时候被拒了,症状基本就是无法登陆啥的.我们公司的应用也未能幸免. 很多同学也想了不少办法,申诉. ...
- vue如何在路由跳转的时候更新组件
项目中在路由跳转的时候碰到一个问题,没有更新视图,如何解决呢: https://segmentfault.com/a/1190000008879966 http://www.tuicool.com/a ...
- visio直线交叉相交跨线修改
在使用visio画流程图时,经常会遇到两条直线相交.下面讲如何修改使得相交点变成我们想要的方式. 可以设置如下: (1) 全局直线相交,设置跨线标志. (2) 对每条线进行相交跨线设置. (一) ...
- HTML <meta> 标签 和 http-equiv
前言 经常在写HTML,但是对于meta 的设置却一直疏于关注. <meta> 是什么 <meta> 是一个HTML的标签(辅助性标签). 它的位置位于文档的头部 <h ...
- Python(一)之Python概述
前言:最近学习Python基础,网上找了视频教程,本篇记录下Python概况,学习环境Python2.6. 学习Python首先得会获取Python自带的帮助信息,下面几个实用的内置函数,不管是工作或 ...
- idea 换主题
换背景 . 选中行变色
- [emacs] org-mode的一些小技巧
Table of Contents 1 快速输入 #+BEGIN_SRC … #+END_SRC 2 代码按语法高亮 3 导出成HTML时的一些问题和技巧 3.1 生成目录表 3.2 为每个分节的标题 ...
- C语言 · 扶老奶奶过街
算法提高 扶老奶奶过街 时间限制:1.0s 内存限制:256.0MB 一共有5个红领巾,编号分别为A.B.C.D.E,老奶奶被他们其中一个扶过了马路. 五个红领巾各自说话: A :我 ...
- ffmpeg 将jpg转为yuv
ffmpeg -i temp.jpg -s 1024x680 -pix_fmt yuvj420p 9.yuv 此前网上有条盛传的命令 -y -s出来uv是错的