java操作hbase1.3.1的增删改查
我的eclipse程序在windows7机器上,hbase在linux机器上
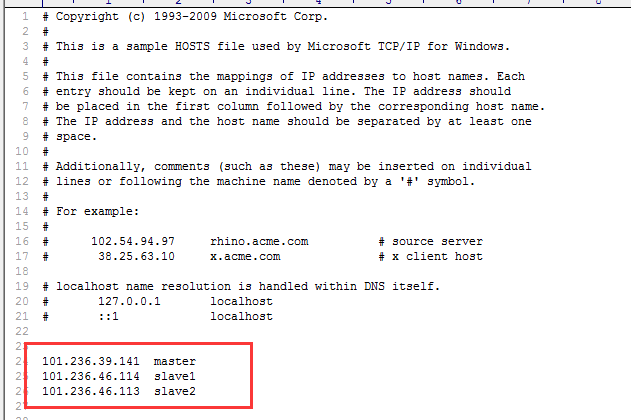
1,首先在C:\Windows\System32\drivers\etc下面的HOSTS文件,加上linux 集群
2.直接附上代码:
package com.yilian.util; import java.io.File;
import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes; public class HbaseTest2 {
public static Configuration configuration;
public static Connection connection;
public static Admin admin; public static void main(String[] args) throws IOException {
//createTable("t2", new String[] { "cf1", "cf2" });
listTables();
/*
* insterRow("t2", "rw1", "cf1", "q1", "val1"); getData("t2", "rw1",
* "cf1", "q1"); scanData("t2", "rw1", "rw2");
* deleRow("t2","rw1","cf1","q1"); deleteTable("t2");
*/
} // 初始化链接
public static void init() {
configuration = HBaseConfiguration.create();
/*
* configuration.set("hbase.zookeeper.quorum",
* "10.10.3.181,10.10.3.182,10.10.3.183");
* configuration.set("hbase.zookeeper.property.clientPort","2181");
* configuration.set("zookeeper.znode.parent","/hbase");
*/
configuration.set("hbase.zookeeper.property.clientPort", "2181");
configuration.set("hbase.zookeeper.quorum", "101.236.39.141,101.236.46.114,101.236.46.113");
configuration.set("hbase.master", "101.236.39.141:60000");
File workaround = new File(".");
System.getProperties().put("hadoop.home.dir",
workaround.getAbsolutePath());
new File("./bin").mkdirs();
try {
new File("./bin/winutils.exe").createNewFile();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
try {
connection = ConnectionFactory.createConnection(configuration);
admin = connection.getAdmin();
} catch (IOException e) {
e.printStackTrace();
}
} // 关闭连接
public static void close() {
try {
if (null != admin)
admin.close();
if (null != connection)
connection.close();
} catch (IOException e) {
e.printStackTrace();
} } // 建表
public static void createTable(String tableNmae, String[] cols) throws IOException { init();
TableName tableName = TableName.valueOf(tableNmae); if (admin.tableExists(tableName)) {
System.out.println("talbe is exists!");
} else {
HTableDescriptor hTableDescriptor = new HTableDescriptor(tableName);
for (String col : cols) {
HColumnDescriptor hColumnDescriptor = new HColumnDescriptor(col);
hTableDescriptor.addFamily(hColumnDescriptor);
}
admin.createTable(hTableDescriptor);
}
close();
} // 删表
public static void deleteTable(String tableName) throws IOException {
init();
TableName tn = TableName.valueOf(tableName);
if (admin.tableExists(tn)) {
admin.disableTable(tn);
admin.deleteTable(tn);
}
close();
} // 查看已有表
public static void listTables() throws IOException {
init();
HTableDescriptor hTableDescriptors[] = admin.listTables();
for (HTableDescriptor hTableDescriptor : hTableDescriptors) {
System.out.println(hTableDescriptor.getNameAsString());
}
close();
} // 插入数据
public static void insterRow(String tableName, String rowkey, String colFamily, String col, String val)
throws IOException {
init();
Table table = connection.getTable(TableName.valueOf(tableName));
Put put = new Put(Bytes.toBytes(rowkey));
put.addColumn(Bytes.toBytes(colFamily), Bytes.toBytes(col), Bytes.toBytes(val));
table.put(put); // 批量插入
/*
* List<Put> putList = new ArrayList<Put>(); puts.add(put);
* table.put(putList);
*/
table.close();
close();
} // 删除数据
public static void deleRow(String tableName, String rowkey, String colFamily, String col) throws IOException {
init();
Table table = connection.getTable(TableName.valueOf(tableName));
Delete delete = new Delete(Bytes.toBytes(rowkey));
// 删除指定列族
// delete.addFamily(Bytes.toBytes(colFamily));
// 删除指定列
// delete.addColumn(Bytes.toBytes(colFamily),Bytes.toBytes(col));
table.delete(delete);
// 批量删除
/*
* List<Delete> deleteList = new ArrayList<Delete>();
* deleteList.add(delete); table.delete(deleteList);
*/
table.close();
close();
} // 根据rowkey查找数据
public static void getData(String tableName, String rowkey, String colFamily, String col) throws IOException {
init();
Table table = connection.getTable(TableName.valueOf(tableName));
Get get = new Get(Bytes.toBytes(rowkey));
// 获取指定列族数据
// get.addFamily(Bytes.toBytes(colFamily));
// 获取指定列数据
// get.addColumn(Bytes.toBytes(colFamily),Bytes.toBytes(col));
Result result = table.get(get); showCell(result);
table.close();
close();
} // 格式化输出
public static void showCell(Result result) {
Cell[] cells = result.rawCells();
for (Cell cell : cells) {
System.out.println("RowName:" + new String(CellUtil.cloneRow(cell)) + " ");
System.out.println("Timetamp:" + cell.getTimestamp() + " ");
System.out.println("column Family:" + new String(CellUtil.cloneFamily(cell)) + " ");
System.out.println("row Name:" + new String(CellUtil.cloneQualifier(cell)) + " ");
System.out.println("value:" + new String(CellUtil.cloneValue(cell)) + " ");
}
} // 批量查找数据
public static void scanData(String tableName, String startRow, String stopRow) throws IOException {
init();
Table table = connection.getTable(TableName.valueOf(tableName));
Scan scan = new Scan();
// scan.setStartRow(Bytes.toBytes(startRow));
// scan.setStopRow(Bytes.toBytes(stopRow));
ResultScanner resultScanner = table.getScanner(scan);
for (Result result : resultScanner) {
showCell(result);
}
table.close();
close();
} }
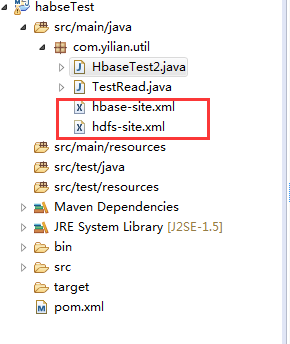
3.项目下面还要放上linux环境上配置hadoop和hbase配置文件,hbase-site.xml和hdfs-site.xml,下面是我项目的简单结构
4.按要求贴上pom.xml文件,我这项目还用了hive,redis连接,所以pom.xml写的jar比较多,但其实只需要hbase连接的jar就行
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.yilian.hbase</groupId>
<artifactId>habseTest</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>habseTest</name> <properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.3.1</version>
</dependency> <dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-common</artifactId>
<version>1.3.1</version>
</dependency> <dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.5.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.5.1</version>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.5.1</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>0.13.1</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>1.1.0</version>
</dependency> <dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jms</artifactId>
<version>4.0.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>4.0.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>4.0.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-tx</artifactId>
<version>4.0.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-aspects</artifactId>
<version>4.0.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context-support</artifactId>
<version>4.0.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-expression</artifactId>
<version>4.0.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-web</artifactId>
<version>4.0.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webmvc</artifactId>
<version>4.0.6.RELEASE</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.31</version>
</dependency>
<dependency>
<groupId>commons-dbcp</groupId>
<artifactId>commons-dbcp</artifactId>
<version>1.4</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.1.33</version>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.7.0</version>
</dependency>
</dependencies>
</distributionManagement>
</project>
java操作hbase1.3.1的增删改查的更多相关文章
- java操作elasticsearch实现基本的增删改查操作
一.在进行java操作elasticsearch之前,请确认好集群的名称及对应的ES节点ip和端口 1.查看ES的集群名称 #进入elasticsearch.yml配置文件/opt/elasticse ...
- AD 域服务简介(三)- Java 对 AD 域用户的增删改查操作
博客地址:http://www.moonxy.com 关于AD 域服务器搭建及其使用,请参阅:AD 域服务简介(一) - 基于 LDAP 的 AD 域服务器搭建及其使用 Java 获取 AD 域用户, ...
- java jdbc 连接mysql数据库 实现增删改查
好久没有写博文了,写个简单的东西热热身,分享给大家. jdbc相信大家都不陌生,只要是个搞java的,最初接触j2ee的时候都是要学习这么个东西的,谁叫程序得和数据库打交道呢!而jdbc就是和数据库打 ...
- Java通过JDBC进行简单的增删改查(以MySQL为例)
Java通过JDBC进行简单的增删改查(以MySQL为例) 目录: 前言:什么是JDBC 一.准备工作(一):MySQL安装配置和基础学习 二.准备工作(二):下载数据库对应的jar包并导入 三.JD ...
- 第三百零七节,Django框架,models.py模块,数据库操作——表类容的增删改查
Django框架,models.py模块,数据库操作——表类容的增删改查 增加数据 create()方法,增加数据 save()方法,写入数据 第一种方式 表类名称(字段=值) 需要save()方法, ...
- 五 Django框架,models.py模块,数据库操作——表类容的增删改查
Django框架,models.py模块,数据库操作——表类容的增删改查 增加数据 create()方法,增加数据 save()方法,写入数据 第一种方式 表类名称(字段=值) 需要save()方法, ...
- java+jsp+sqlserver实现简单的增删改查操作 连接数据库代码
1,网站系统开发需要掌握的技术 (1)网页设计语言,html语言css语言等 (2)Java语言 (3)数据库 (4)等 2,源程序代码 (1) 连接数据库代码 package com.jaovo.m ...
- Java对XML文档的增删改查
JAVA增删改查XML文件 最近总是需要进行xml的相关操作. 不免的要进行xml的读取修改等,于是上网搜索,加上自己的小改动,整合了下xml的常用操作. 读取XML配置文件 首先我们需要通过Do ...
- Java描述数据结构之链表的增删改查
链表是一种常见的基础数据结构,它是一种线性表,但在内存中它并不是顺序存储的,它是以链式进行存储的,每一个节点里存放的是下一个节点的"指针".在Java中的数据分为引用数据类型和基础 ...
随机推荐
- c# 进程调用exe
using System; using System.Collections.Generic; using System.ComponentModel; using System.Diagnostic ...
- HDU 4557
http://acm.hdu.edu.cn/showproblem.php?pid=4557 解决一类问题的set用法 #include <iostream> #include <c ...
- xdoj 1044---炸红花 (话说 小时候经常玩这个被虐。。。。qwq)
// 我真的好笨 只会枚举 话说那个ac的370b到底是怎么做的 /(ㄒoㄒ)/~~ #include <iostream> #include <algorithm> usin ...
- 定义一组抽象的 Awaiter 的实现接口,你下次写自己的 await 可等待对象时将更加方便
我在几篇文章中都说到了在 .NET 中自己实现 Awaiter 情况.async / await 写异步代码用起来真的很爽,就像写同步一样.然而实现 Awaiter 没有现成的接口,它需要你按照编译器 ...
- 【洛谷P1338】末日的传说
https://www.luogu.org/problemnew/show/P1338 [题目大意:从1到n的连续自然数,求其逆序对数为m的一个字母序最小的排列.] 最开始的思路是想从逆序对数入手,然 ...
- LG2945 【[USACO09MAR]沙堡Sand Castle】
经典的贪心模型,常规思路:将M和B排序即可 看到没有人用优先队列,于是我的showtime到了 说下思路: 读入时将数加入啊a,b堆中,不用处理(二叉堆本来就有有序的性质) 读完后逐个判断,照题目模拟 ...
- 转 MetaWeblog API 编写
如今,许多人都熟悉个人和公司或业界主办的博客.后者明显成为了传统公司和行业网站的下一代新兴产物.博客的内容涉及从简洁的特制产品公告和公共关系到实用且深刻的主题探索,这些主题可能对公司的产品或行业的未来 ...
- No result defined for action com.nynt.action.ManageAction and result input问题
No result defined for action com.nynt.action.ManageAction and result input 问题原因: 1). 在action类中定义的一个r ...
- 在CentOS和RHEL中配置SNMPv3
首先,使用yum安装必要的软件 [root@server ~]# yum install net-snmp-utils net-snmp-devel安装完成之后, 先停止snmpd,再创建具有只读属性 ...
- 移植RTL8188CUS USB-WIFI(移植失败)
1.主makefile CONFIG_POWER_SAVING = n CONFIG_PLATFORM_I386_PC = n CONFIG_PLATFORM_HI3518E = y ##swann ...