ML之监督学习算法之分类算法一 ——— 决策树算法
一、概述
决策树(decision tree)的一个重要任务是为了数据中所蕴含的知识信息,因此决策树可以使用不熟悉的数据集合,并从中提取出一系列规则,在这些机器根据数据创建规则时,就是机器学习的过程。
二、决策树的构造
决策树:
优点:计算复杂度不高, 输出结果易于理解, 对中间值的缺失不敏感, 可以处理不相关特征数据。
缺点: 可能会产生过度匹配问题。
适用数据类型:数值型和标称型
在构造决策树时, 我们需要解决的第一个问题就是, 当前数据集上哪个特征在划分数据分类时起决定性作用。 为了找到决定性的特征, 划分出最好的结果, 我们必须评估每个特征。 完成测试之后, 原始数据集就被划分为几个数据子集。 这些数据子集会分布在第一个决策点的所有分支上;
决策树的一般流程
1. 收集数据: 可以使用任何方法。
2. 准备数据: 树构造算法只适用于标称型数据, 因此数值型数据必须离散化。
3. 分析数据: 可以使用任何方法, 构造树完成之后, 我们应该检查图形是否符合预期。
4. 训练算法: 构造树的数据结构。
5. 测试算法: 使用经验树计算错误率。
6. 使用算法: 此步骤可以适用于任何监督学习算法, 而使用决策树可以更好地理解数据的内在含义。
涉及的算法:
二分法:一些决策树算法采用二分法划分数据,
ID3: 而我们将适用ID3算法划分数据集 ,ID3算法更多信息了解
C4.5: ID3的一个改进, 比ID3准确率高且快, 可以处理连续值和有缺失值的feature
CRAT: 使用基尼指数的划分准则,通过在每个步骤最大限度降低不纯洁度, CART能够处理孤立点以及对空缺值的处理;
信息增益:
划分数据集的大原则是: 将无序的数据变得更加有序。 我们可以使用多 种方法划分数据集, 但是每种方法都有各自的优缺点。 组织杂乱无章数据的一种方法就是使用信息论度量信息, 信息论是量化处理信息的分支 科学。 我们可以在划分数据前后使用信息论量化度量信息的内容。
在划分数据集之前之后信息发生的变化称为信息增益, 知道如何计算信 息增益, 我们就可以计算每个特征值划分数据集获得的信息增益, 获得 信息增益最高的特征就是最好的选择。
熵:
为了计算熵(entropy), 我们需要计算所有类别所有可能值包含的信息期望值, 通过下面的公式得到:
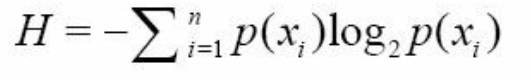
符号xi 的信息定义为:
其中p(xi)是选择该分类的概率
熵的单位是bit, 用来衡量信息的多少;从计算熵的公式来看:
变量的不确定性越大, 熵就越大;
计算完信息熵后,我们便可以得到数据集的无序程度。我们将对每个特征划分数据集的结果计算一次信息熵,然后判断哪个特征划分数据集是最好的划分方式(根据信息熵判断,信息熵越小,说明划分效果越好)
三、ID3算法
选择属性判断节点;
信息获取量(Information Gain): Gain(A)= Info(D) - Infor_A(D) , 通过A来作为节点分类获取了多少信息;
ML之监督学习算法之分类算法一 ——— 决策树算法的更多相关文章
- 算法杂货铺——分类算法之朴素贝叶斯分类(Naive Bayesian classification)
算法杂货铺——分类算法之朴素贝叶斯分类(Naive Bayesian classification) 0.写在前面的话 我个人一直很喜欢算法一类的东西,在我看来算法是人类智慧的精华,其中蕴含着无与伦比 ...
- ML之监督学习算法之分类算法一 ———— k-近邻算法(最邻近算法)
一.概述 最近邻规则分类(K-Nearest Neighbor)KNN算法 由Cover 和Hart在1968年提出了最初的邻近算法, 这是一个分类(classification)算法 输入基于实例的 ...
- (ZT)算法杂货铺——分类算法之朴素贝叶斯分类(Naive Bayesian classification)
https://www.cnblogs.com/leoo2sk/archive/2010/09/17/naive-bayesian-classifier.html 0.写在前面的话 我个人一直很喜欢算 ...
- (ZT)算法杂货铺——分类算法之决策树(Decision tree)
https://www.cnblogs.com/leoo2sk/archive/2010/09/19/decision-tree.html 3.1.摘要 在前面两篇文章中,分别介绍和讨论了朴素贝叶斯分 ...
- (ZT)算法杂货铺——分类算法之贝叶斯网络(Bayesian networks)
https://www.cnblogs.com/leoo2sk/archive/2010/09/18/bayes-network.html 2.1.摘要 在上一篇文章中我们讨论了朴素贝叶斯分类.朴素贝 ...
- Spark ML下实现的多分类adaboost+naivebayes算法在文本分类上的应用
1. Naive Bayes算法 朴素贝叶斯算法算是生成模型中一个最经典的分类算法之一了,常用的有Bernoulli和Multinomial两种.在文本分类上经常会用到这两种方法.在词袋模型中,对于一 ...
- 【十大算法实现之naive bayes】朴素贝叶斯算法之文本分类算法的理解与实现
关于bayes的基础知识,请参考: 基于朴素贝叶斯分类器的文本聚类算法 (上) http://www.cnblogs.com/phinecos/archive/2008/10/21/1315948.h ...
- Kmeans算法与KNN算法的区别
最近研究数据挖掘的相关知识,总是搞混一些算法之间的关联,俗话说好记性不如烂笔头,还是记下了以备不时之需. 首先明确一点KNN与Kmeans的算法的区别: 1.KNN算法是分类算法,分类算法肯定是需要有 ...
- 数学建模:2.监督学习--分类分析- KNN最邻近分类算法
1.分类分析 分类(Classification)指的是从数据中选出已经分好类的训练集,在该训练集上运用数据挖掘分类的技术,建立分类模型,对于没有分类的数据进行分类的分析方法. 分类问题的应用场景:分 ...
随机推荐
- Direct2D教程VII——变换几何(TransformedGeometry)对象
目前博客园中成系列的Direct2D的教程有 1.万一的 Direct2D 系列,用的是Delphi 2009 2.zdd的 Direct2D 系列,用的是VS中的C++ 3.本文所在的 Direct ...
- [Canvas]计时表/秒表
欲观看效果请点击下载,然后用浏览器打开index.html查看. 本作 Github地址:https://github.com/horn19782016/StopWatch 图例: 代码: <! ...
- 【Python】使用geopy由经纬度找地理信息
from geopy.geocoders import Nominatim geolocator = Nominatim() location = geolocator.reverse("3 ...
- 极域电子教室卸载或安装软件后windows7无法启用触摸板、键盘
我今天在win7上装了个极域电子教室,卸载后重启触摸板,键盘都不能用了?连口令都是用屏幕键盘来输入的.进去后看设备管理器,键盘和触摸板,前面都有黄色的告警,而且就是出现了鼠标代码为10的情况?不过吧鼠 ...
- setUserVisibleHint-- fragment真正的onResume和onPause方法
现在越来越多的应用会使用viewpager+fragment显示自己的内容页,fragment和activity有很多共同点,如下图就是fragment的生命周期 但是fragment和activit ...
- TCP三次握手详解
当两台主机采用 TCP 协议进行通信时,在交换数据前将建立连接.通信完成后,将关闭会话并终止连接.连接和会话机制保障了TCP 的可靠性功能. 请参见图中建立并终止 TCP 连接的步骤. 主机将跟踪会话 ...
- React (native) 相关知识
container component provider组件 react里的redux进阶玩法 react组件的生命周期 conductor / componentWillMount / render ...
- 演示一下:rm -rf /
- kettle 如何将excel文件导入oracle数据库?
1.情景展示 昨日,有一批数据需要导入数据库,但是,plsql不知为何不能导了,于是,我选择使用kettle完成excel数据的导入. 2.准备工作 将对应的数据库所需的jar包拷贝至其lib目录 ...
- Leetcode 240 Search a 2D Matrix II (二分法和分治法解决有序二维数组查找)
1.问题描写叙述 写一个高效的算法.从一个m×n的整数矩阵中查找出给定的值,矩阵具有例如以下特点: 每一行从左到右递增. 每一列从上到下递增. 2. 方法与思路 2.1 二分查找法 依据矩阵的特征非常 ...