Python爬虫-豆瓣电影 Top 250
爬取的网页地址为:https://movie.douban.com/top250
打开网页后,可观察到:TOP250的电影被分成了10个页面来展示,每个页面有25个电影。
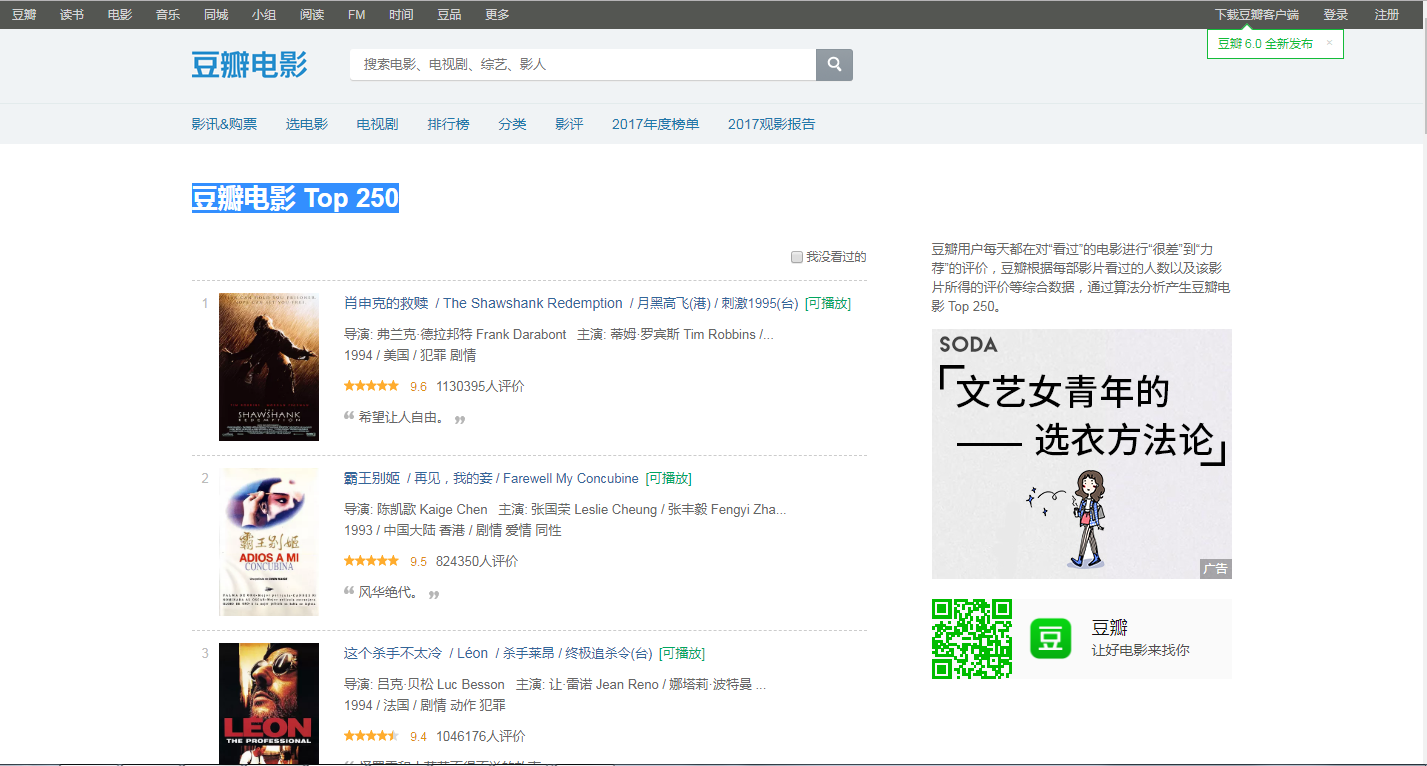
那么要爬取所有电影的信息,就需要知道另外9个页面的URL链接。
第一页:https://movie.douban.com/top250
第二页:https://movie.douban.com/top250?start=25&filter=
第三页:https://movie.douban.com/top250?start=50&filter=
以此类推...
分析网页源代码:以首页为例

观察后可以发现:
所有电影信息在一个ol标签之内,该标签的 class属性值为grid_view;
每个电影在一个li标签里面;
每个电影的电影名称在:第一个 class属性值为hd 的div标签 下的 第一个 class属性值为title 的span标签里;
每个电影的评分在对应li标签里的(唯一)一个 class属性值为rating_num 的span标签里;
每个电影的评价人数在 对应li标签 里的一个 class属性值为star 的div标签中 的最后一个数字;
每个电影的短评在 对应li标签 里的一个 class属性值为inq 的span标签里。
Python主要模块:requests模块 BeautifulSoup4模块
>pip install requests
>pip install BeautifulSoup4
主要代码:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
# -*- coding:utf-8 -*-
import requests # requests模块 from bs4 import BeautifulSoup # BeautifulSoup4模块 import re # 正则表达式模块 import time # 时间模块 import sys # 系统模块 """获取html文档""" """解析数据""" # 得到电影的评分 # 得到电影的评价人数 # 得到电影的短评 ))) # 将输出重定向到txt文件 outputfile.close() |
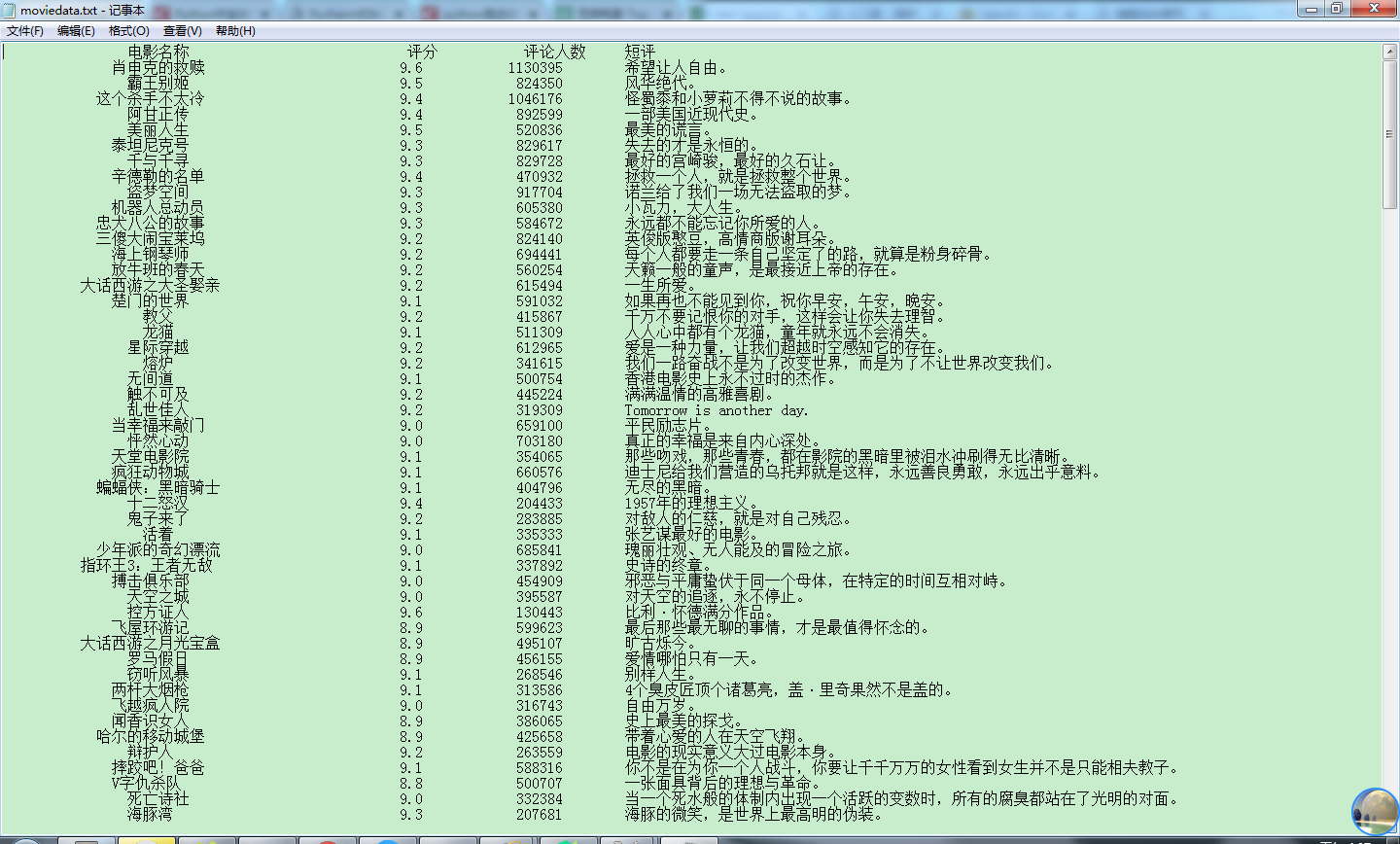
参考出处:https://blog.csdn.net/linzch3/article/details/62444947
Python爬虫-豆瓣电影 Top 250的更多相关文章
- 用python爬取豆瓣电影Top 250
首先,打开豆瓣电影Top 250,然后进行网页分析.找到它的Host和User-agent,并保存下来. 然后,我们通过翻页,查看各页面的url,发现规律: 第一页:https://movie.dou ...
- 爬取豆瓣电影TOP 250的电影存储到mongodb中
爬取豆瓣电影TOP 250的电影存储到mongodb中 1.创建项目sp1 PS D:\scrapy> scrapy.exe startproject douban 2.创建一个爬虫 PS D: ...
- Python开发爬虫之静态网页抓取篇:爬取“豆瓣电影 Top 250”电影数据
所谓静态页面是指纯粹的HTML格式的页面,这样的页面在浏览器中展示的内容都在HTML源码中. 目标:爬取豆瓣电影TOP250的所有电影名称,网址为:https://movie.douban.com/t ...
- python爬虫: 豆瓣电影top250数据分析
转载博客 https://segmentfault.com/a/1190000005920679 根据自己的环境修改并配置mysql数据库 系统:Mac OS X 10.11 python 2.7 m ...
- python爬虫-豆瓣电影的尝试
一.背景介绍 1. 使用工具 Pycharm 2. 安装的第三方库 requests.BeautifulSoup 2.1 如何安装第三方库 File => Settings => Proj ...
- 豆瓣电影 Top 250
import refrom urllib.request import urlopen def getPage(url): # 获取网页的字符串 response = urlopen(url) ret ...
- 爬虫——正则表达式爬取豆瓣电影TOP前250的中英文名
正则表达式爬取豆瓣电影TOP前250的中英文名 1.首先要实现网页的数据的爬取.新建test.py文件 test.py 1 import requests 2 3 def get_Html_text( ...
- 爬虫系列1:Requests+Xpath 爬取豆瓣电影TOP
爬虫1:Requests+Xpath 爬取豆瓣电影TOP [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]: ...
- 放养的小爬虫--豆瓣电影入门级爬虫(mongodb使用教程~)
放养的小爬虫--豆瓣电影入门级爬虫(mongodb使用教程~) 笔者声明:只用于学习交流,不用于其他途径.源代码已上传github.githu地址:https://github.com/Erma-Wa ...
随机推荐
- Swift 编程思想 阅读笔记
Swift 编程思想,第一部分:拯救小马html, body {overflow-x: initial !important;}.CodeMirror { height: auto; } .CodeM ...
- Windows系统32位、64位DLL文件的存放位置
查资料时无意中发现,Windows系统存放DLL的文件路径似乎有点蹊跷: 32位的DLL存放在C:\Windows\SysWOW64,而64位的DLL存放在C:\Windows\System32.即使 ...
- MyBatis拦截器的执行顺序引发的MyBatis源码分析
你猜一下哪个先执行?反正不要按常规来. <plugins> <plugin interceptor="com.Interceptor1"></plug ...
- [看门狗]基于Linux的嵌入式系统全程喂狗策略
转自:http://blog.csdn.net/erickhuang1989/article/details/8721548 在嵌入式系统中,为了使系统在异常情况下能自动恢复,一般都会引入看门狗电路. ...
- CAS (7) —— Mac下配置CAS 4.x的JPATicketRegistry(服务端)
CAS (7) -- Mac下配置CAS 4.x集群及JPATicketRegistry(服务端) tomcat版本: tomcat-8.0.29 jdk版本: jdk1.8.0_65 cas版本: ...
- Java设计模式(20)观察者模式(Observer模式)
Java深入到一定程度,就不可避免的碰到设计模式(design pattern)这一概念,了解设计模式,将使自己对java中的接口或抽象类应用有更深的理解.设计模式在java的中型系统中应用广泛,遵循 ...
- 客户端Cookie读取操作
function SetCookie(name,value) { //此 cookie 将被保存 30 天(可活动配置) var Days = 30; var exp = new Date(); ex ...
- Sword redis补充
Redis 键(key) Redis 键命令用于管理 redis 的键. redis任何数据类型都有key --删除key的命令 redis> del key Redis 事务 Redis 事务 ...
- why "Everything" is so fast?
Everything并不扫描整个磁盘,只是读取磁盘上的USN日志,所以速度飞快.但因此缺点也明显:1.只支持NTFS格式的分区,因为USN日志是NTFS专有的.在FAT.FAT32格式分区上无法使用E ...
- Python之cv2
1.读取图片 import cv2 img = cv2.imread('./test.jpg') 读取出来的图片是numpy.ndarray格式,值是0-255, img的形状是 (图片高度,图片宽度 ...