Python爬虫-豆瓣电影 Top 250
爬取的网页地址为:https://movie.douban.com/top250
打开网页后,可观察到:TOP250的电影被分成了10个页面来展示,每个页面有25个电影。
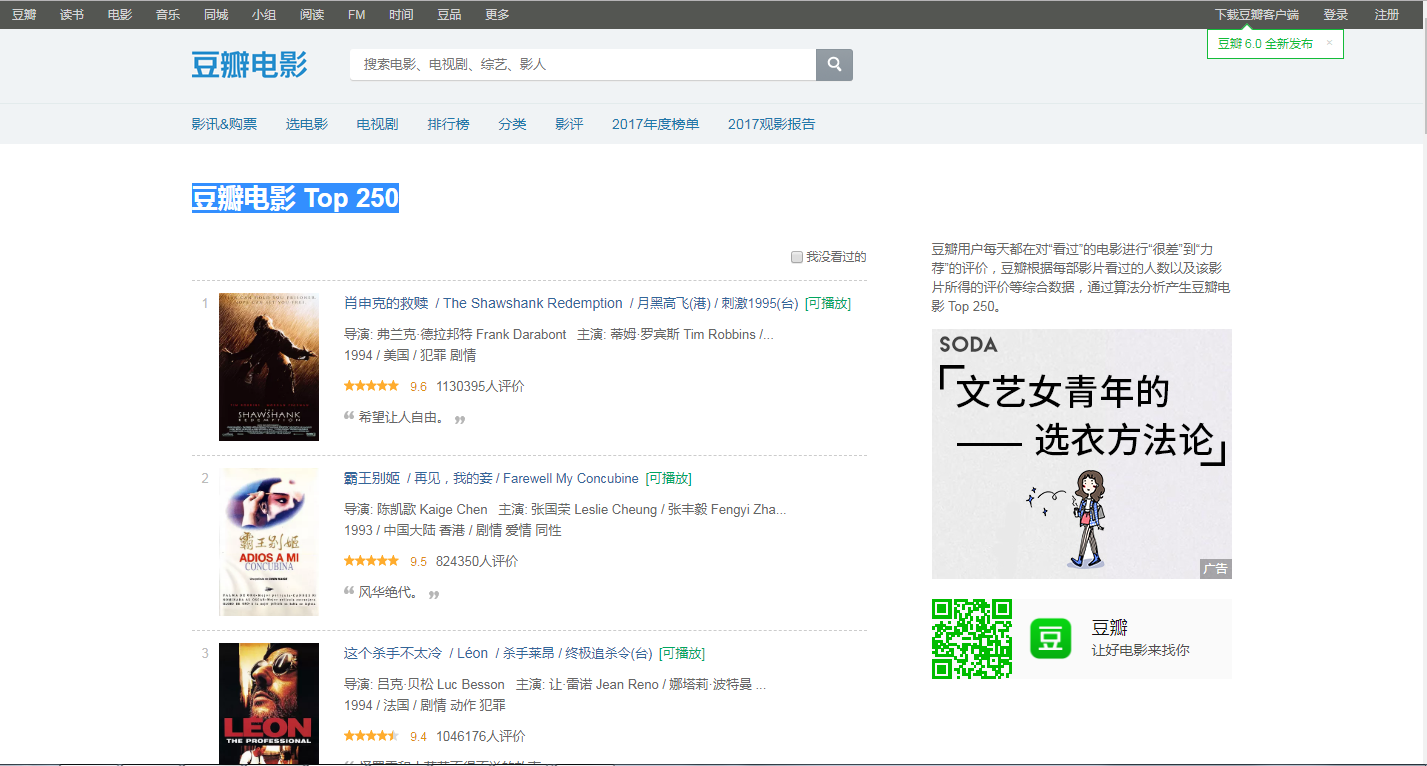
那么要爬取所有电影的信息,就需要知道另外9个页面的URL链接。
第一页:https://movie.douban.com/top250
第二页:https://movie.douban.com/top250?start=25&filter=
第三页:https://movie.douban.com/top250?start=50&filter=
以此类推...
分析网页源代码:以首页为例

观察后可以发现:
所有电影信息在一个ol标签之内,该标签的 class属性值为grid_view;
每个电影在一个li标签里面;
每个电影的电影名称在:第一个 class属性值为hd 的div标签 下的 第一个 class属性值为title 的span标签里;
每个电影的评分在对应li标签里的(唯一)一个 class属性值为rating_num 的span标签里;
每个电影的评价人数在 对应li标签 里的一个 class属性值为star 的div标签中 的最后一个数字;
每个电影的短评在 对应li标签 里的一个 class属性值为inq 的span标签里。
Python主要模块:requests模块 BeautifulSoup4模块
>pip install requests
>pip install BeautifulSoup4
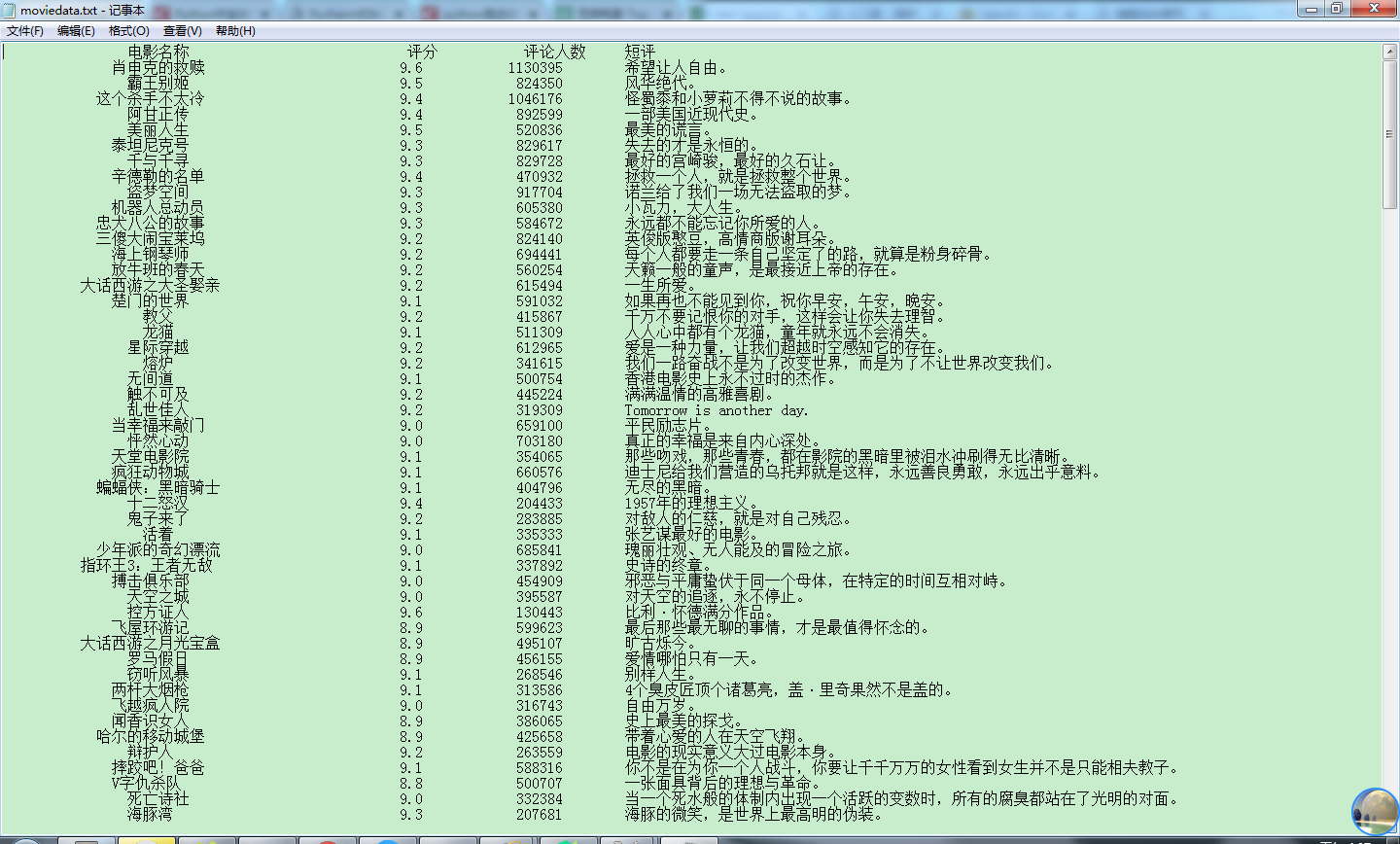
主要代码:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
# -*- coding:utf-8 -*-
import requests # requests模块 from bs4 import BeautifulSoup # BeautifulSoup4模块 import re # 正则表达式模块 import time # 时间模块 import sys # 系统模块 """获取html文档""" """解析数据""" # 得到电影的评分 # 得到电影的评价人数 # 得到电影的短评 ))) # 将输出重定向到txt文件 outputfile.close() |
参考出处:https://blog.csdn.net/linzch3/article/details/62444947
Python爬虫-豆瓣电影 Top 250的更多相关文章
- 用python爬取豆瓣电影Top 250
首先,打开豆瓣电影Top 250,然后进行网页分析.找到它的Host和User-agent,并保存下来. 然后,我们通过翻页,查看各页面的url,发现规律: 第一页:https://movie.dou ...
- 爬取豆瓣电影TOP 250的电影存储到mongodb中
爬取豆瓣电影TOP 250的电影存储到mongodb中 1.创建项目sp1 PS D:\scrapy> scrapy.exe startproject douban 2.创建一个爬虫 PS D: ...
- Python开发爬虫之静态网页抓取篇:爬取“豆瓣电影 Top 250”电影数据
所谓静态页面是指纯粹的HTML格式的页面,这样的页面在浏览器中展示的内容都在HTML源码中. 目标:爬取豆瓣电影TOP250的所有电影名称,网址为:https://movie.douban.com/t ...
- python爬虫: 豆瓣电影top250数据分析
转载博客 https://segmentfault.com/a/1190000005920679 根据自己的环境修改并配置mysql数据库 系统:Mac OS X 10.11 python 2.7 m ...
- python爬虫-豆瓣电影的尝试
一.背景介绍 1. 使用工具 Pycharm 2. 安装的第三方库 requests.BeautifulSoup 2.1 如何安装第三方库 File => Settings => Proj ...
- 豆瓣电影 Top 250
import refrom urllib.request import urlopen def getPage(url): # 获取网页的字符串 response = urlopen(url) ret ...
- 爬虫——正则表达式爬取豆瓣电影TOP前250的中英文名
正则表达式爬取豆瓣电影TOP前250的中英文名 1.首先要实现网页的数据的爬取.新建test.py文件 test.py 1 import requests 2 3 def get_Html_text( ...
- 爬虫系列1:Requests+Xpath 爬取豆瓣电影TOP
爬虫1:Requests+Xpath 爬取豆瓣电影TOP [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]: ...
- 放养的小爬虫--豆瓣电影入门级爬虫(mongodb使用教程~)
放养的小爬虫--豆瓣电影入门级爬虫(mongodb使用教程~) 笔者声明:只用于学习交流,不用于其他途径.源代码已上传github.githu地址:https://github.com/Erma-Wa ...
随机推荐
- WPF打包工具
找到一款相当不错的WPF项目的打包工具:advanced installer 工具简单易用,有破/解版,还可以把项目依赖库一起打到一个包中. 用法参考: https://www.cnblogs.com ...
- Spring WebSocket教程(二)
实现目标 这一篇文章,就要直接实现聊天的功能,并且,在聊天功能的基础上,再实现缓存一定聊天记录的功能. 第一步:聊天实现原理 首先,需要明确我们的需求.通常,网页上的聊天,都是聊天室的形式,所以,这个 ...
- Go Revel - Routing(路由)
`Routing`路由控制着请求应该由哪些控制器接受. 它在项目的`conf/routes`文件中定义. 格式为: (METHOD) (URL Pattern) (Controller.Action) ...
- Java通过JDBC进行简单的增删改查(以MySQL为例)
Java通过JDBC进行简单的增删改查(以MySQL为例) 目录: 前言:什么是JDBC 一.准备工作(一):MySQL安装配置和基础学习 二.准备工作(二):下载数据库对应的jar包并导入 三.JD ...
- ansible示例,离线安装etcd
一.基础介绍 ========================================================================================== 1. ...
- webRTC源码下载 Windows Mac(iOS) Linux(Android)全
webRTC源码下载地址:https://pan.baidu.com/s/18CjClvAuz3B9oF33ngbJIw 提取码:wl1e Windows版:visual studio 2017工 ...
- 一图让你看懂CSS盒子模型
- ggplot ggplot2 画图
折线图-ggplot2 http://blog.163.com/yugao1986@126/blog/static/6922850820131161531421/http://blog.sina.c ...
- [spark 快速大数据分析读书笔记] 第一章 导论
[序言] Spark 基于内存的基本类型 (primitive)为一些应用程序带来了 100 倍的性能提升.Spark 允许用户程序将数据加载到 集群内存中用于反复查询,非常适用于大数据和机器学习. ...
- tornado上传大文件以及多文件上传
tornado上传大文件问题解决方法 tornado默认上传限制为低于100M,但是由于需要上传大文件需求,网上很多说是用nginx,但我懒,同时不想在搞一个服务了. 解决方法: server = H ...