hadoop完全分布式搭建HA(高可用)
首先创建5台虚拟机(最少三台),并且做好部署规划
|
ip地址 |
主机名 |
安装软件 |
进程 |
|
192.168.xx.120 |
master |
jdk,hadoop,zookeeper |
namenode,ZKFC,Resourcemanager |
|
192.168.xx.121 |
master2 |
jdk,hadoop,zookeeper |
namenode,ZKFC,Resourcemanager |
|
192.168.xx.122 |
slave1 |
jdk,hadoop,zookeeper |
natanode,nodemanager,zookeeper,Journalnode, |
|
192.168.xx.123 |
slave2 |
jdk,hadoop,zookeeper |
natanode,nodemanager,zookeeper,Journalnode, |
|
192.168.xx.124 |
slave3 |
jdk,hadoop,zookeeper |
natanode,nodemanager,zookeeper,Journalnode, |
一、首先设置防火墙防火墙
立即关闭防火墙service iptables stop

设置防火墙开机不启动 chkconfig iptables off

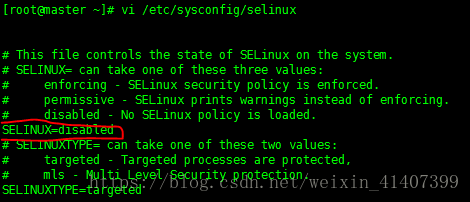
设置 selinux 将SELINUX 改为disabled
二、编辑主机名映射
vi/etc/hosts

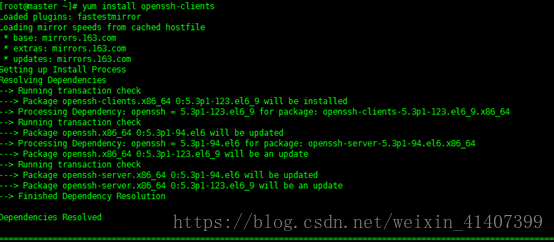
下载 ssh包获取scp命令
yuminstall openssh-clients
将hosts远程拷贝至后面四台机器
scp /etc/hostsmaster2:/etc/hosts

三、设置五台机器时间同步
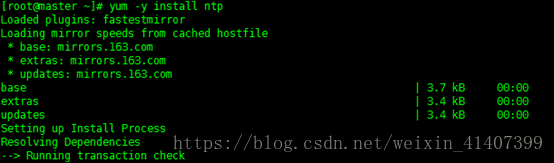
最小化安装没有ntpdate这个软件,首先用yum命令下载
yum –y installntp
设置master 与指定时间服务器同步
ntpdate cn.pool.ntp.org

设置后面4台机器与master同步
修改master ntp配置文件
vi /etc/ntp.conf
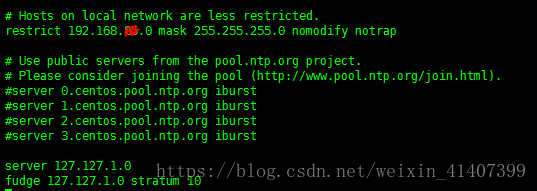
讲restrict 上的网段改为自己的网段
注释server 服务器
在最下面添加两行server 和fudge内容
启动ntpd ,并设置为开机启动

关闭后面几台ntpd,并设置为开机不启动

同步master时间服务器
ntpdate master

四、创建普通用户
adduser hadoop
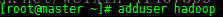
passwd hadoop 设置密码
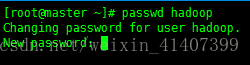
五、SSH免密登录
切换到普通用户

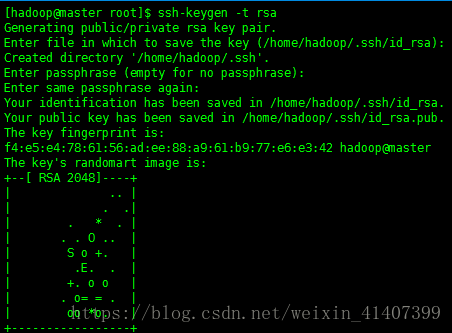
在五台机器上都输入ssh-keygen –t rsa,然后一直按回车
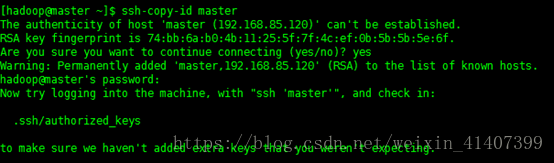
将秘钥拷贝到五台机器上
ssh-copy-id master
ssh-copy-id master2
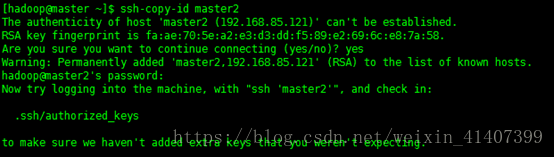
ssh-copy-id slave1
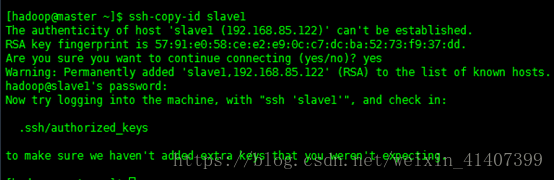
ssh-copy-id slave2
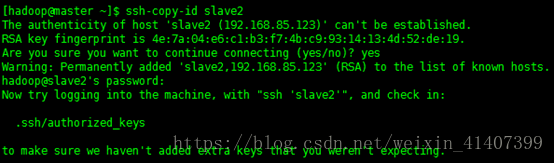
ssh-copy-id slave3
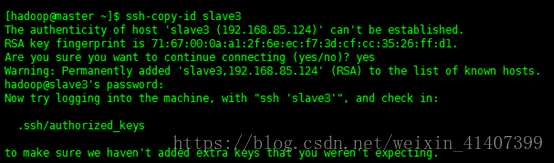
测试能否免密登录,设置成功!

在其他四台机器上重复以上操作
六、安装jdk
我这里是最小化安装不需要检查系统自己看装的jdk,如果不是需要卸载
通过下面两行命令查找卸载
rpm –qa |grep jdk
rpm –e –nodep
修改/opt/文件夹用户
chown –R hadoop:hadoop /opt/
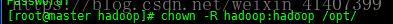
创建 /opt/software文件夹,这个文件夹用来存放压缩包, 创建/opt/modules这个文件用来存放解压的软件

上传jdk到software

解压jdk到modules

配置环境变变量,切换到root用户vi /etc/profile 也可以在普通用户下修改vi ~/.bash_profile,在最后添加

保存退出,输入 source /etc/profile ,然后输入java -version验证版本

将java scp至其他几台机器

将配置文件scp至其他几台机器

七、进入slave1主机,安装配置zookeeper
上传zookeeper到software文件夹,并解压到modules

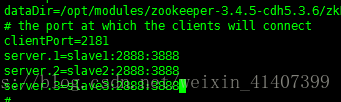
修改zookeeper配置文件


修改dataDir 路径,增加server配置信息
创建zkData文件夹并创建myid文件,在slave1输入1

scp zookeeper文件夹到slave2和slave3下

修改slave2和slave3 的myid文件

启动zookeeper,并验证状态
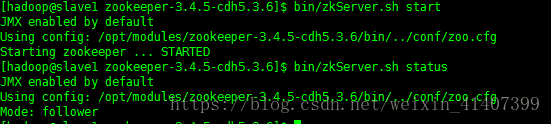
启动 bin/zkCli.sh,配置完成!
八、安装配置hadoop
上传hadoop到software文件夹,并解压到modules

配置hadoop环境变量
root vi /etc/profile, 记得source /etc/profile

修改hadoop 配置文件
修改 etc/hadoop 下的环境变量文件增加java环境变量
hadoop-env.sh mapred-env.sh yarn-env.sh
export JAVA_HOME=/opt/modules/jdk1.7.0_79
修改core-site.xml文件
- <configuration>
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://ns1</value>
- </property>
- <property>
- <name>hadoop.tmp.dir</name>
- <value>/opt/modules/App/hadoop-2.5.0/data/tmp</value>
- </property>
- <property>
- <name>hadoop.http.staticuser.user</name>
- <value>hadoop</value>
- </property>
- <property>
- <name>ha.zookeeper.quorum</name>
- <value>slave1:2181,slave2:2181,slave3:2181</value>
- </property>
- </configuration>
修改hdfs-site.xml文件
- <configuration>
- <property>
- <name>dfs.replication</name>
- <value>3</value>
- </property>
- <property>
- <name>dfs.permissions.enabled</name>
- <value>false</value>
- </property>
- <property>
- <name>dfs.nameservices</name>
- <value>ns1</value>
- </property>
- <property>
- <name>dfs.blocksize</name>
- <value>134217728</value>
- </property>
- <property>
- <name>dfs.ha.namenodes.ns1</name>
- <value>nn1,nn2</value>
- </property>
- <!-- nn1的RPC通信地址,nn1所在地址 -->
- <property>
- <name>dfs.namenode.rpc-address.ns1.nn1</name>
- <value>master:8020</value>
- </property>
- <!-- nn1的http通信地址,外部访问地址 -->
- <property>
- <name>dfs.namenode.http-address.ns1.nn1</name>
- <value>master:50070</value>
- </property>
- <!-- nn2的RPC通信地址,nn2所在地址 -->
- <property>
- <name>dfs.namenode.rpc-address.ns1.nn2</name>
- <value>master2:8020</value>
- </property>
- <!-- nn2的http通信地址,外部访问地址 -->
- <property>
- <name>dfs.namenode.http-address.ns1.nn2</name>
- <value>master2:50070</value>
- </property>
- <!-- 指定NameNode的元数据在JournalNode日志上的存放位置(一般和zookeeper部署在一起) -->
- <property>
- <name>dfs.namenode.shared.edits.dir</name>
- <value>qjournal://slave1:8485;slave2:8485;slave3:8485/ns1</value>
- </property>
- <!-- 指定JournalNode在本地磁盘存放数据的位置 -->
- <property>
- <name>dfs.journalnode.edits.dir</name>
- <value>/opt/modules/hadoop-2.5.0-cdh5.3.6/data/journal</value>
- </property>
- <!--客户端通过代理访问namenode,访问文件系统,HDFS 客户端与Active 节点通信的Java 类,使用其确定Active 节点是否活跃 -->
- <property>
- <name>dfs.client.failover.proxy.provider.ns1</name>
- <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
- </property>
- <!--这是配置自动切换的方法,有多种使用方法,具体可以看官网,在文末会给地址,这里是远程登录杀死的方法 -->
- <property>
- <name>dfs.ha.fencing.methods</name>
- <value>sshfence</value>
- </property>
- <!-- 这个是使用sshfence隔离机制时才需要配置ssh免登陆 -->
- <property>
- <name>dfs.ha.fencing.ssh.private-key-files</name>
- <value>/home/hadoop/.ssh/id_rsa</value>
- </property>
- <!-- 配置sshfence隔离机制超时时间,这个属性同上,如果你是用脚本的方法切换,这个应该是可以不配置的 -->
- <property>
- <name>dfs.ha.fencing.ssh.connect-timeout</name>
- <value>30000</value>
- </property>
- <!-- 这个是开启自动故障转移,如果你没有自动故障转移,这个可以先不配 -->
- <property>
- <name>dfs.ha.automatic-failover.enabled</name>
- <value>true</value>
- </property>
- </configuration>
修改mapred-site.xml.template名称为mapred-site.xml并修改
- <configuration>
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
- <property>
- <name>mapreduce.jobhistory.address</name>
- <value>master:10020</value>
- </property>
- <property>
- <name>mapreduce.jobhistory.webapp.address</name>
- <value>master:19888</value>
- </property>
- </configuration>
配置 yarn-site.xml
- <configuration>
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
- <!-- Site specific YARN configuration properties -->
- <!--启用resourcemanager ha-->
- <!--是否开启RM ha,默认是开启的-->
- <property>
- <name>yarn.resourcemanager.ha.enabled</name>
- <value>true</value>
- </property>
- <!--声明两台resourcemanager的地址-->
- <property>
- <name>yarn.resourcemanager.cluster-id</name>
- <value>rmcluster</value>
- </property>
- <property>
- <name>yarn.resourcemanager.ha.rm-ids</name>
- <value>rm1,rm2</value>
- </property>
- <property>
- <name>yarn.resourcemanager.hostname.rm1</name>
- <value>master</value>
- </property>
- <property>
- <name>yarn.resourcemanager.hostname.rm2</name>
- <value>master2</value>
- </property>
- <!--指定zookeeper集群的地址-->
- <property>
- <name>yarn.resourcemanager.zk-address</name>
- <value>slave1:2181,slave2:2181,slave3:2181</value>
- </property>
- <!--启用自动恢复,当任务进行一半,rm坏掉,就要启动自动恢复,默认是false-->
- <property>
- <name>yarn.resourcemanager.recovery.enabled</name>
- <value>true</value>
- </property>
- <!--指定resourcemanager的状态信息存储在zookeeper集群,默认是存放在FileSystem里面。-->
- <property>
- <name>yarn.resourcemanager.store.class</name>
- <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
- </property>
- </configuration>
配置slaves
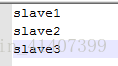
scp hadoop到其他四台机器,拷贝之前删除share/doc文件


分别在master和master2的yarn-site.xml上添加
- <property>
- <name>yarn.resourcemanager.ha.id</name>
- <value>rm1</value>
- </property>
- <property>
- <name>yarn.resourcemanager.ha.id</name>
- <value>rm2</value>
- </property>

启动zookeeper

启动journalnode sbin/hadoop-deamon.sh startjournalnode

格式化master namenode bin/hdfs namenode –format

启动 master namenode sbin/hadoop-deamon.sh startnamenode

在master2上同步master namenode元数据 bin/hdfs namenode -bootstrapStandby

启动master2 namenode sbin/hadoop-deamon.sh startnamenode

此时进入 50070 web页面,两个namenode都是standby状态,这是可以先强制手动是其中一个节点变为active bin/hdfs haadmin –transitionToActive–forcemanual
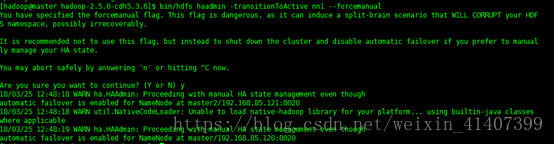
此时master变为active
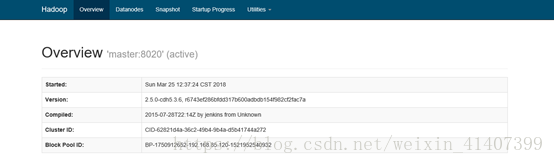
手动故障转移已经完成,接下来配置自动故障转移
先把整个集群关闭,zookeeper不关,输入bin/hdfs zkfc –formatZK,格式化ZKFC

在slave1上登录zookeeper

输入ls / ,发现多了一个hadoop-ha节点,这是配置应该没有问题
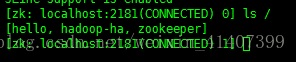
启动集群, 在master 输入 sbin/start-dfs.sh
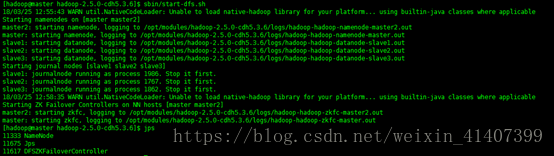
此时一个节点stanby 一个节点active
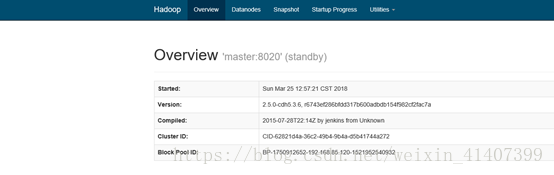
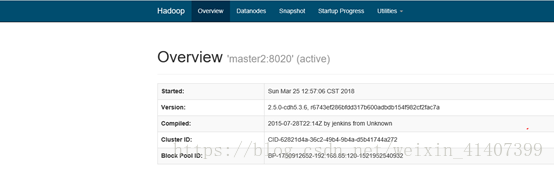
现在kill掉master namenode进程, 刷新master页面
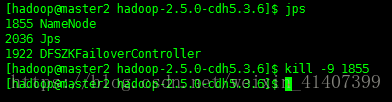
master自动切换为active,配置成功!
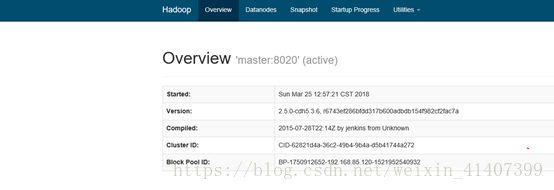
启动yarn,测试resourcemanager ha ,master1输入 sbin/start-yarn.sh

master2输入 sbin/yarn-daemaon.sh start resourcemanager

在web 端输入master2:8088自动跳转

Kill master rm进程
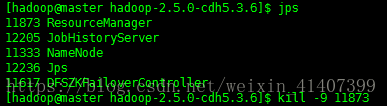
master2:8088 active

wordcount程序测试,在本地创建一个测试文件,并上传到hdfs上



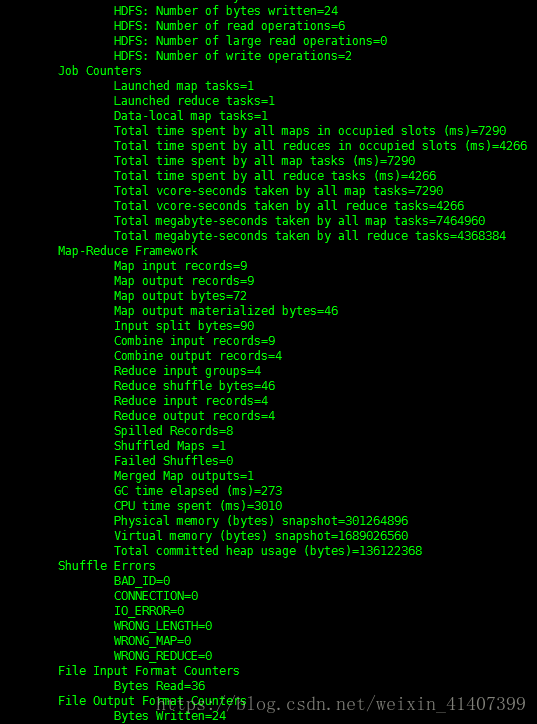
查看输出文件 hadoop fs –cat /output1/part*,运行成功

关闭active rm ,再次运行wordcount
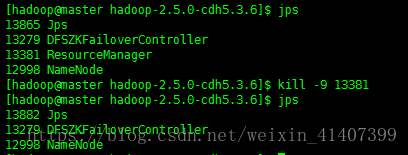

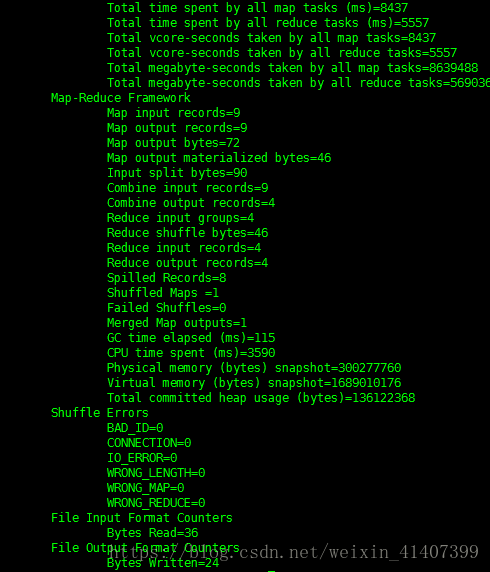
关闭active namenode,查看文件
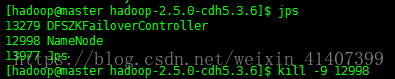
查看成功,rm nn HA配置成功!

hadoop完全分布式搭建HA(高可用)的更多相关文章
- Hadoop集群搭建-HA高可用(手动切换模式)(四)
步骤和集群规划 1)保存完全分布式模式配置 2)在full配置的基础上修改为高可用HA 3)第一次启动HA 4)常规启动HA 5)运行wordcount 集群规划: centos虚拟机:node-00 ...
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- Hadoop 3.1.2(HA)+Zookeeper3.4.13+Hbase1.4.9(HA)+Hive2.3.4+Spark2.4.0(HA)高可用集群搭建
目录 目录 1.前言 1.1.什么是 Hadoop? 1.1.1.什么是 YARN? 1.2.什么是 Zookeeper? 1.3.什么是 Hbase? 1.4.什么是 Hive 1.5.什么是 Sp ...
- hadoop 集群HA高可用搭建以及问题解决方案
hadoop 集群HA高可用搭建 目录大纲 1. hadoop HA原理 2. hadoop HA特点 3. Zookeeper 配置 4. 安装Hadoop集群 5. Hadoop HA配置 搭建环 ...
- 大数据Hadoop的HA高可用架构集群部署
1 概述 在Hadoop 2.0.0之前,一个Hadoop集群只有一个NameNode,那么NameNode就会存在单点故障的问题,幸运的是Hadoop 2.0.0之后解决了这个问题,即支持N ...
- linux -- 基于zookeeper搭建yarn的HA高可用集群
linux -- 基于zookeeper搭建yarn的HA高可用集群 实现方式:配置yarn-site.xml配置文件 <configuration> <property> & ...
- HA高可用的搭建
HA 即 (high available)高可用,又被叫做双机热备,用于关键性业务. 简单理解就是,有两台机器A和B,正常是A提供服务,B待命闲置,当A宕机或服务宕掉,会切换至B机器继续提供服务.常用 ...
- CentOS7+Hadoop2.7.2(HA高可用+Federation联邦)+Hive1.2.1+Spark2.1.0 完全分布式集群安装
1 2 2.1 2.2 2.3 2.4 2.5 2.6 2.7 2.8 2.9 2.9.1 2.9.2 2.9.2.1 2.9.2.2 2.9.3 2.9.3.1 2.9.3.2 2.9.3.3 2. ...
- centos HA高可用集群 heartbeat搭建 heartbeat测试 主上停止heartbeat服务 测试脑裂 两边都禁用ping仲裁 第三十二节课
centos HA高可用集群 heartbeat搭建 heartbeat测试 主上停止heartbeat服务 测试脑裂 两边都禁用ping仲裁 第三十二节课 heartbeat是Linu ...
随机推荐
- 转载:帮你提升 Python 的 27 种编程语言
帮你提升 Python 的 27 种编程语言: 出处:http://www.oschina.net/translate/languages-to-improve-your-python
- HTML5 3D Google搜索 小盒子 大世界
HTML5真是能让人想象万千,居然动起了Google搜索的主意,它利用HTML5技术将Google搜索放到了一个小盒子里,弄起了3D搜索.随着鼠标移动,HTML5 3D搜索盒子也就转动,非常立体.点击 ...
- datepicker clone 控件错误
删除id,并删除hasDatepicker //+ - function changeRows(sender,desc){ var tr = $(sender).closest("tr&q ...
- PHP获取当前url路径的函数及服务器变量:$_SERVER["QUERY_STRING"],$_SERVER["REQUEST_URI"],$_SERVER["SCRIPT_NAME"],$_SER
1,$_SERVER["QUERY_STRING"] 说明:查询(query)的字符串 2,$_SERVER["REQUEST_URI"] 说明:访问此页面所需 ...
- Android使用http协议与服务器通信
网上介绍Android上http通信的文章很多,不过大部分只给出了实现代码的片段,一些注意事项和如何设计一个合理的类用来处理所有的http请求以及返回结果,一般都不会提及.因此,自己对此做了些总结,给 ...
- [Learn AF3]第七章 App framework组件之Popup
AF3的弹出对话框Popup 组件名称:Popup 是否js控件:是,$.afui.popup 说明:af3中的popup和af2中相比变化不大,依然是通过插件popup来实现的 方法 ...
- Linq 查询某个字段为null的数据
如tb_flag 数据结构如下:flag int null 不能使用:flag==null 生成的SQL语句为 where flag=null 建议使用:可空类型 用Nullable<T&g ...
- 避免使用jQuery的html方法来替换标签,而是使用replaceWith方法
tblCostSplit.html内容: <nobr title="">只想显示里面内容,去掉nobr标签</nobr> <nobr title=&q ...
- Yslow-23条军规
YslowYahoo发布的一款基于FireFox的插件,主要是为了提高网页性能而设计的,下面是它提倡了23条规则,还是很不错的,分享一下: 1.减少HTTP请求次数 合并图片.CSS.JS,改进首次访 ...
- 如何将会员名单加入LINE@生活圈?
如何将会员名单加入LINE@生活圈? 我要如何将会员名单加入LINE@生活圈呢?答案是没有办法利用LINE@生活圈直接加入会员名单,LINE@生活圈是许可式行销,必须由LINE好友主动将LINE@生活 ...