linux -- 基于zookeeper搭建yarn的HA高可用集群
linux -- 基于zookeeper搭建yarn的HA高可用集群
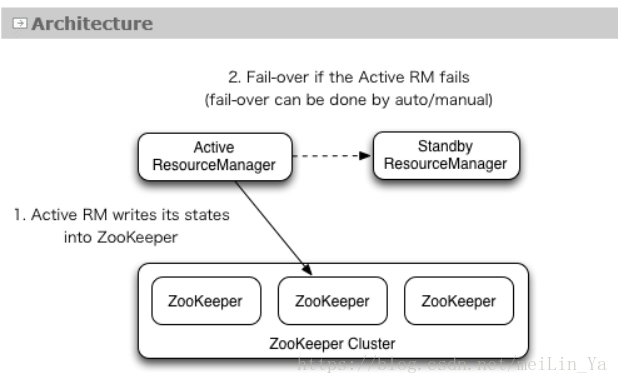
实现方式:配置yarn-site.xml配置文件
<configuration>
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>2000</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.embedded</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value> beiwangyarn</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>1707a-hadoop1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>1707a-hadoop2</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.zk.state-store.address</name>
<value>1707a-hadoop1:2181,1707a-hadoop2:2181,1707a-hadoop3:2181</value>
</property>
<property>
<name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</name>
<value>5000</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>1707a-hadoop1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>1707a-hadoop1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address.rm1</name>
<value>1707a-hadoop1:23189</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>1707a-hadoop1:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>1707a-hadoop1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>1707a-hadoop1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>1707a-hadoop2:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>1707a-hadoop2:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address.rm2</name>
<value>1707a-hadoop2:23189</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>1707a-hadoop2:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>1707a-hadoop2:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>1707a-hadoop2:8033</value>
</property>
<property>
<description>Address where the localizer IPC is.</description>
<name>yarn.nodemanager.localizer.address</name>
<value>0.0.0.0:23344</value>
</property>
<property>
<description>NM Webapp address.</description>
<name>yarn.nodemanager.webapp.address</name>
<value>0.0.0.0:23999</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/tmp/pseudo-dist/yarn/local</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/tmp/pseudo-dist/yarn/log</value>
</property>
<property>
<name>mapreduce.shuffle.port</name>
<value>23080</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>1707a-hadoop1:2181,1707a-hadoop2:2181,1707a-hadoop3:2181</value>
</property>
</configuration>
将mapred-site.xml.template改为:mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hu-hadoop1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hu-hadoop1:19888</value>
</property>
</configuration>
同步数据
scp * hu-hadoop3:/`pwd`

启动:
start-yarn.sh
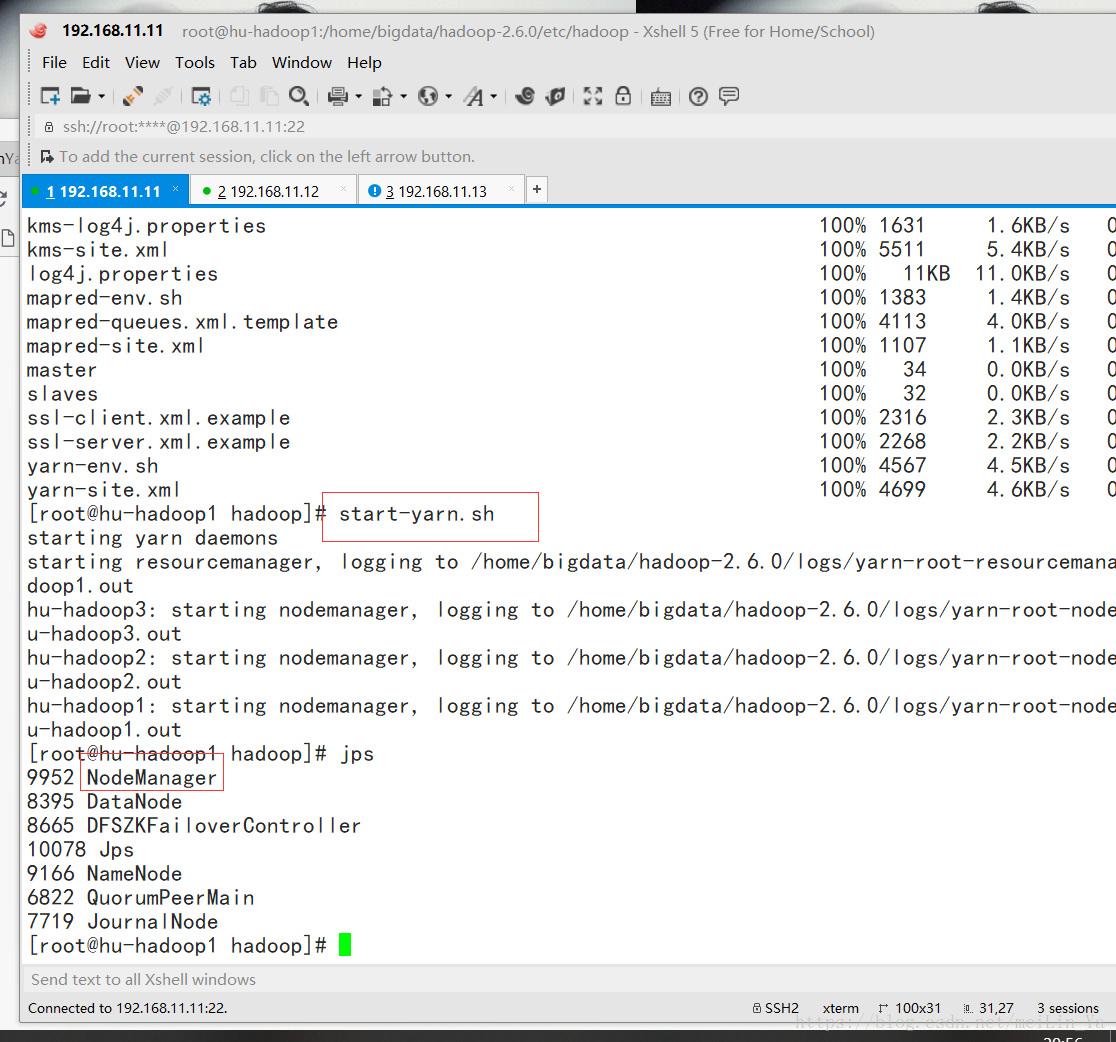
手动在hu-hadoop2中启动ResourceManager
yarn-daemon.sh start resourcemanager
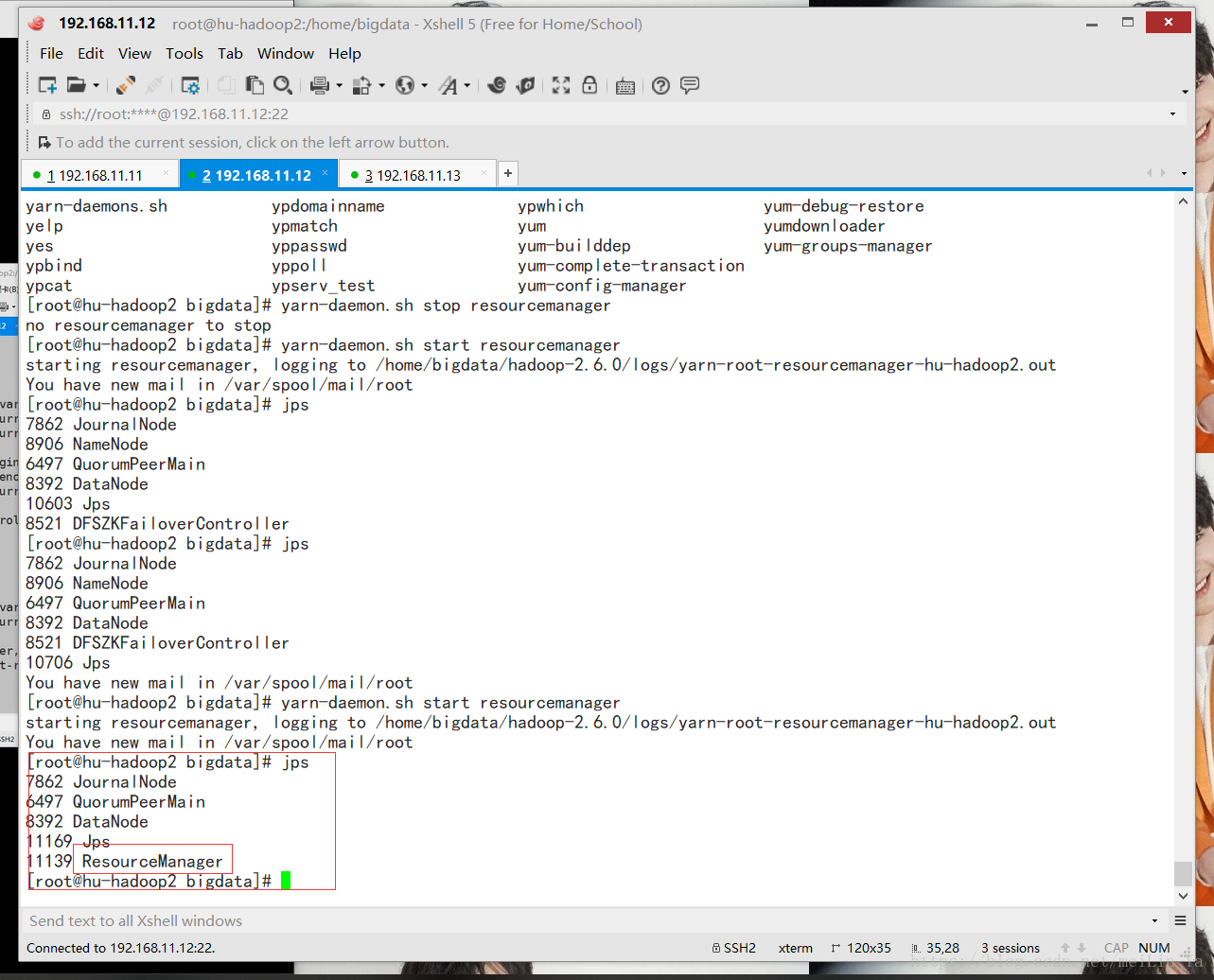

看看网页吧!!!
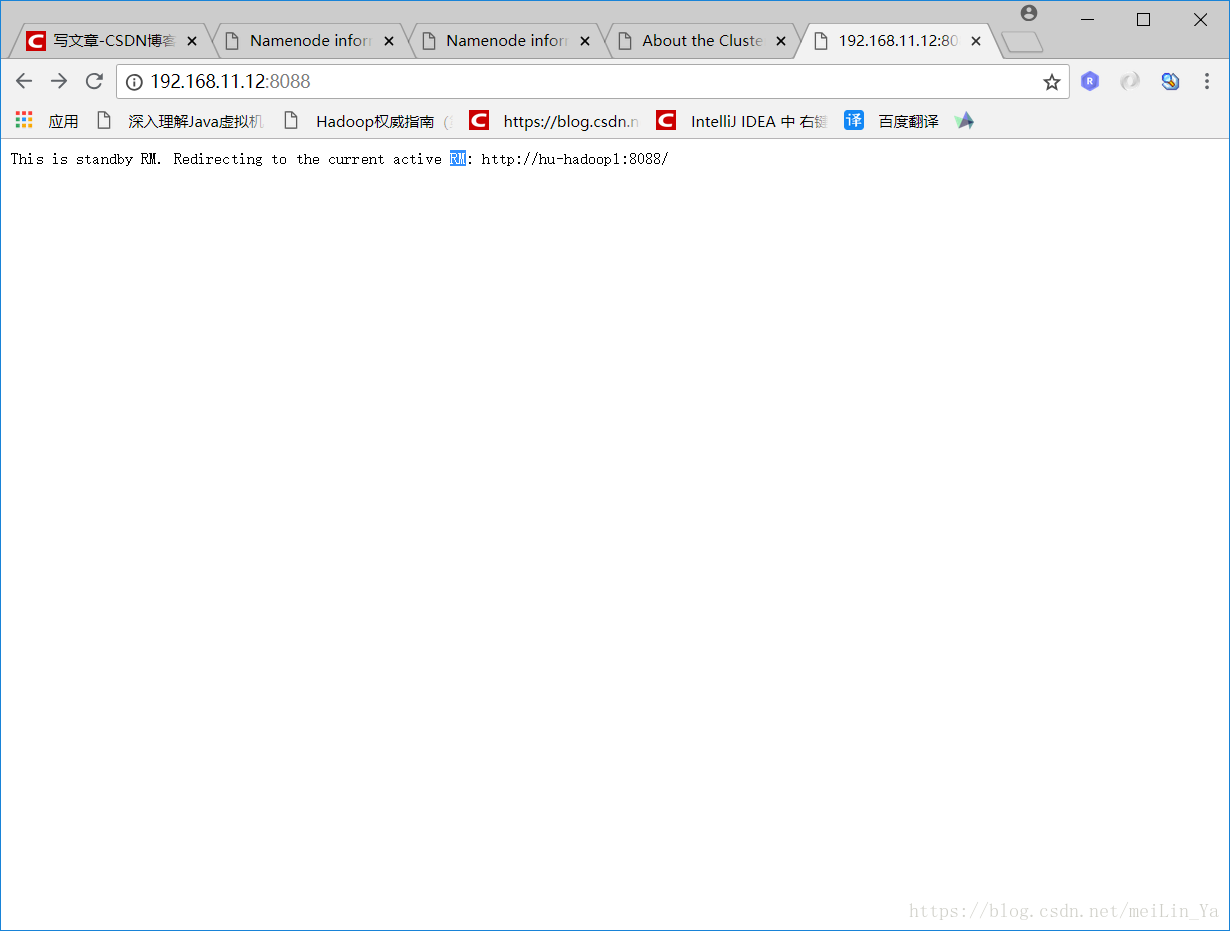
之后他会跳到主的页面中:
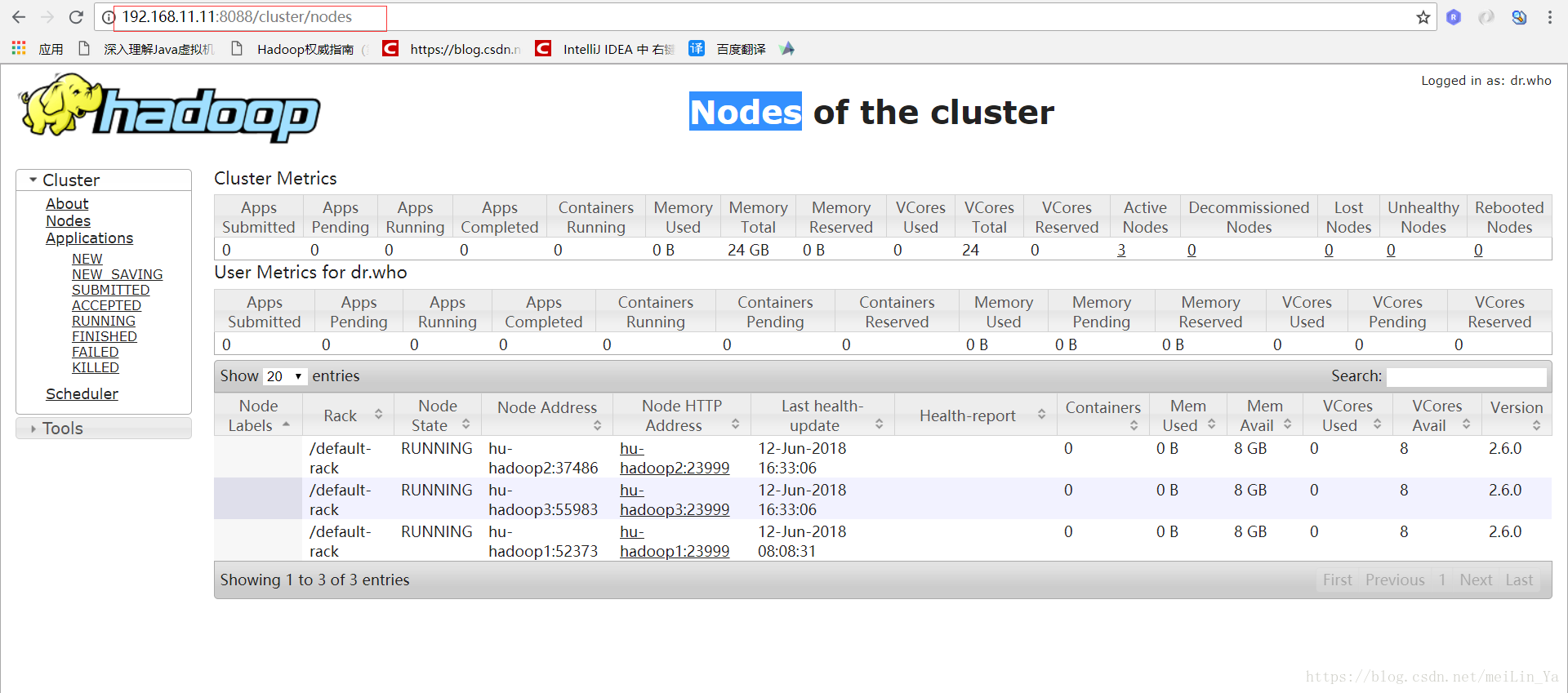
linux -- 基于zookeeper搭建yarn的HA高可用集群的更多相关文章
- 七、Hadoop3.3.1 HA 高可用集群QJM (基于Zookeeper,NameNode高可用+Yarn高可用)
目录 前文 Hadoop3.3.1 HA 高可用集群的搭建 QJM 的 NameNode HA Hadoop HA模式搭建(高可用) 1.集群规划 2.Zookeeper集群搭建: 3.修改Hadoo ...
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- Hadoop 3.1.2(HA)+Zookeeper3.4.13+Hbase1.4.9(HA)+Hive2.3.4+Spark2.4.0(HA)高可用集群搭建
目录 目录 1.前言 1.1.什么是 Hadoop? 1.1.1.什么是 YARN? 1.2.什么是 Zookeeper? 1.3.什么是 Hbase? 1.4.什么是 Hive 1.5.什么是 Sp ...
- centos HA高可用集群 heartbeat搭建 heartbeat测试 主上停止heartbeat服务 测试脑裂 两边都禁用ping仲裁 第三十二节课
centos HA高可用集群 heartbeat搭建 heartbeat测试 主上停止heartbeat服务 测试脑裂 两边都禁用ping仲裁 第三十二节课 heartbeat是Linu ...
- HA 高可用集群概述及其原理解析
HA 高可用集群概述及其原理解析 1. 概述 1)所谓HA(High Available),即高可用(7*24小时不中断服务). 2)实现高可用最关键的策略是消除单点故障.HA严格来说应该分成各个组件 ...
- 基于Keepalived实现LVS双主高可用集群
Reference: https://mp.weixin.qq.com/s?src=3×tamp=1512896424&ver=1&signature=L1C7us ...
- Kubeadm 1.9 HA 高可用集群本地离线镜像部署【已验证】
k8s介绍 k8s 发展速度很快,目前很多大的公司容器集群都基于该项目,如京东,腾讯,滴滴,瓜子二手车,易宝支付,北森等等. kubernetes1.9版本发布2017年12月15日,每三个月一个迭代 ...
- [K8s 1.9实践]Kubeadm 1.9 HA 高可用 集群 本地离线镜像部署
k8s介绍 k8s 发展速度很快,目前很多大的公司容器集群都基于该项目,如京东,腾讯,滴滴,瓜子二手车,北森等等. kubernetes1.9版本发布2017年12月15日,每是那三个月一个迭代, W ...
- Zookeeper(四)Hadoop HA高可用集群搭建
一.高可就集群搭建 1.集群规划 2.集群服务器准备 (1) 修改主机名(2) 修改 IP 地址(3) 添加主机名和 IP 映射(4) 同步服务器时间(5) 关闭防火墙(6) 配置免密登录(7) 安装 ...
随机推荐
- POJ 3415 Common Substrings(长度不小于K的公共子串的个数+后缀数组+height数组分组思想+单调栈)
http://poj.org/problem?id=3415 题意:求长度不小于K的公共子串的个数. 思路:好题!!!拉丁字母让我Wa了好久!!单调栈又让我理解了好久!!太弱啊!! 最简单的就是暴力枚 ...
- List<Model>转String 、String 转List<string>
var ltCode = from item in psw.VehicleInsuranceItem select item.Code; string code = string.Join(" ...
- hdu 5724 Chess 博弈sg+状态压缩
Chess Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others) Problem De ...
- 【六】php 错误异常处理
错误异常处理 概念:代码在try代码块被调用执行,catch代码块捕获异常 异常需要手动抛出 throw new Exception (‘message’,code) throw将出发异常处理机制 在 ...
- OpenJDK 64-Bit Server VM warning: INFO: os::commit_memory(0x0000000083e80000, 1366294528, 0) failed;
我是在手动搭建nexus时遇到的 安装nexus时 启动命令的时候会报OpenJDK 64-Bit Server VM warning: INFO: os::commit_memory(0x00000 ...
- python 读写json文件(dump, load),以及对json格式的数据处理(dumps, loads)
JSON (JavaScript Object Notation) 是一种轻量级的数据交换格式.它基于ECMAScript的一个子集. 1.json.dumps()和json.loads()是json ...
- C#_方法的重载
方法的重载是一种操作性多态,有的时候,可能需要在多个不同的实现中对不同的数据执行相同的逻辑操作,以writeline方法为例,有时可能想他传递一个整数.两者的具体实现肯定是不同的,但在逻辑上,这个方法 ...
- MYSQL常用函数(时间和日期函数)Java中
CURDATE()或CURRENT_DATE() 返回当前的日期 CURTIME()或CURRENT_TIME() 返回当前的时间 DATE_ADD(date,INTERVAL int keyword ...
- Golang atomic
原子操作函数 分为下面系列函数,其中Xxx可以是Int32/Int64/Uint32/Uint64/Uintptr/Pointer其中一种. 1.SwapXxx系列:交换新旧值: // SwapInt ...
- mt19937 -- 高质量随机数
优点:产生速度快, 周期大 用法: #include<bits/stdc++.h> using namespace std; int main() { mt19937 mt_rand(ti ...