大规模向量相似度计算方法(Google在07年发表的文章)
转载请注明出处:http://www.cnblogs.com/zz-boy/p/3648878.html
更多精彩文章在:http://www.cnblogs.com/zz-boy/
最近看了Google在 WWW2007上发表的Scaling Up All Pairs Similarity Search,觉得还不错,分享一下作者的思路。
在基于用户协同过滤方法的推荐系统中,用户相似度的计算是最终推荐的基础步骤;用户向量是用户的行为向量,其每一维度是物品,值是用户对该物品的喜爱程度,这种场景尤其多见于电商网站,电商网站中的用户数据量是很大的,物品数量也很多,这就导致用户向量数量很大,如果不加优化的计算用户相似度,其时间开销是很大的。
我们给出相似度计算问题的定义:
有一个实数值向量集合U,x(v1,…,vn)是一个实数值向量且x属于U,相似度计算公式为sim(x,y),最终我们要得到的是(x,y,sim(x,y))的集合,其中x,y都属于U,并且sim(x,y)>=t.
可能刚开始看到这个问题,我们的直观的想法都是下面的这种蛮力的求解方法:

上面的方法没有经过任何的优化,t的作用仅仅体现在计算完成的相似度是否满足约束,其实仔细思考这个问题,t的作用不应该仅仅局限于此,我们在将x放入I时,或许可以考虑x是否会和余下的向量相似。基于这样的想法于是便有了下面改进的算法:

可以看到在上面的算法中,很关键的一行是

maxweighti(V)的含义是向量集合V中第i列的最大值,如果遍历完x,b的值仍然小于t,那么x就不可能和余下的向量相似,所以x就不应该被加入倒排表I。另外该算法开头部分对向量维度的重排,在该算法中看似没有什么效果,也就是说即使不重排,也不会影响算法的效率,要让开头语句起作用,上面的算法还要做一些小的改动,在循环
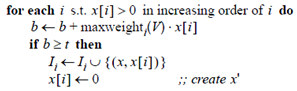
中,一旦判断出b>=t,那么式子

就不要再计算了,这样的改进如果能够提高效率是因为数据满足假设:
一个向量所有维的最大值出现在向量集合密集维度的可能性相对出现在稀疏维度更大。
这个假设不总是成立的,取决于数据集。
下面的算法对数据又加了一步预处理,将V集合按照maxweight(x)的降序排列。

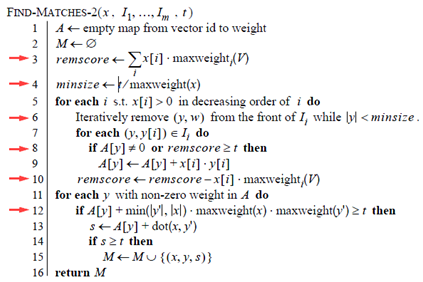
上面算法精彩的几点如下:
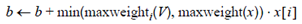
后续将加入倒排表I的向量,所有维度的最大值必然小于maxweight(x),因为数据预处理中的排序步骤。
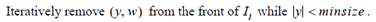
推导步骤:
如果|y|*maxweight(x)<t那么y必然不可能再和后续的要加入倒排表中的向量相似。
这里还要解释一下的是既然All-PAIRS-2中已经对能否加入倒排表中的向量进行了更加严格的限制,这里为什么还要对I进行筛除,这主要是因为对y进行处理时,是针对余下的所有x,当到对x进行处理,和y相似的所有向量都在y至x的处理序列之间,即y不可能再和x之后的向量相似了,所以当处理时对y进行的一个粗的筛选。
- remscore的作用主要体现在和语句
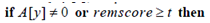
的配合上,试想如果遍历到某一个i时,A[y]=0但是此时remscore却是小于t,那么必然有x不可能和y相似,所以也就没必要计算A[y]了。
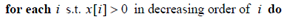
此条语句是降序的原因:向量x的维度序列经过重排,当i降序时,维度稀疏性的变化为稀疏到密集,再结合语句
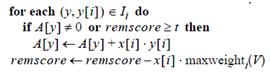
便能做到最大限度的减少在密集维度中的计算次数。
更多精彩文章在:http://www.cnblogs.com/zz-boy/
大规模向量相似度计算方法(Google在07年发表的文章)的更多相关文章
- hadoop Mahout中相似度计算方法介绍(转)
来自:http://blog.csdn.net/samxx8/article/details/7691868 相似距离(距离越小值越大) 优点 缺点 取值范围 PearsonCorrelation 类 ...
- Mahout实战---编写自己的相似度计算方法
Mahout本身提供了很多的相似度计算方法,如PCC,COS等.但是当需要验证自己想出来的相似度计算公式是否是好的,这时候需要自己实现相似度类.研究了Mahout-core-0.9.jar的源码后,自 ...
- Mahout的taste里的几种相似度计算方法
欧几里德相似度(Euclidean Distance) 最初用于计算欧几里德空间中两个点的距离,以两个用户x和y为例子,看成是n维空间的两个向量x和y, xi表示用户x对itemi的喜好值,yi表示 ...
- McCabe环路复杂度计算方法
环路复杂度用来定量度量程序的逻辑复杂度.以McCabe方法来表示. 在程序控制流程图中,节点是程序中代码的最小单元,边代表节点间的程序流.一个有e条边和n个节点的流程图F,可以用下述3种方法中的任何一 ...
- google在nature上发表的关于量子计算机的论文(Quantum supremacy using a programmable superconducting processor 译)— 附论文
Google 2019年10月23号发表在Nature(<自然><科学>及<细胞>杂志都是国际顶级期刊,貌似在上面发文两篇,就可以评院士了)上,关于量子计算(基于 ...
- 自动下载google reader里面的星标文章
1. google reader马上就要关闭了,最后一次看看俺的浏览记录吧 最近 30 天的统计信息 全部订阅: 367 已读条目: 151 已点击的条目:41 个 加星标条目: 16 已发电子邮件条 ...
- Google+团队如何测试移动应用 - from Google Testing Blog
How the Google+ Team Tests Mobile Apps by Eduardo Bravo Ortiz “移动第一”在当下已成为很多公司的口头禅.但是能够用一种合理的方法来测试移动 ...
- Spark MLlib 之 大规模数据集的相似度计算原理探索
无论是ICF基于物品的协同过滤.UCF基于用户的协同过滤.基于内容的推荐,最基本的环节都是计算相似度.如果样本特征维度很高或者<user, item, score>的维度很大,都会导致无法 ...
- 从NLP任务中文本向量的降维问题,引出LSH(Locality Sensitive Hash 局部敏感哈希)算法及其思想的讨论
1. 引言 - 近似近邻搜索被提出所在的时代背景和挑战 0x1:从NN(Neighbor Search)说起 ANN的前身技术是NN(Neighbor Search),简单地说,最近邻检索就是根据数据 ...
随机推荐
- 如何实现Punycode中文域名转码
如果你见过中文域名应该会觉得很奇怪,为什么复制出来的域名变成一个很莫名其妙的字符串,比如这个秀恩爱的域名“郝越.我爱你”,实际显示的域名是 http://xn--vq3al9d.xn--6qq986b ...
- Faster-rcnn 配置方法
Faster-rcnn 在Linux下的配置方法 感谢@邓学长 建立过程: (下载库的时候要按照库readme 进行操作) opencv 的包下载安装,安装教程 用git命令将这个库下载到本地 fas ...
- [WCF安全3]使用wsHttpBinding构建基于SSL与UserName授权的WCF应用程序
上一篇文章中介绍了如何使用wsHttpBinding构建UserName授权的WCF应用程序,本文将为您介绍如何使用wsHttpBinding构建基于SSL的UserName安全授权的WCF应用程序. ...
- Springcloud/Springboot项目绑定域名,使用Nginx配置Https
https://blog.csdn.net/a_squirrel/article/details/79729690 一.Https 简介(百度百科) HTTPS(全称:Hyper Text Trans ...
- SQL Server 的索引结构实例
目前SQL Server 的索引结构如下: 这个是聚集索引的存放形式: 非聚集索引的方式如下: 它们是以B+树的数据结构存放的. 相信大家都看过类似的图,但是没有直观的认识,下面举一个实际的例子来说明 ...
- Floyd判圈算法 Floyd Cycle Detection Algorithm
2018-01-13 20:55:56 Floyd判圈算法(Floyd Cycle Detection Algorithm),又称龟兔赛跑算法(Tortoise and Hare Algorithm) ...
- 英语每日阅读---5、VOA慢速英语(翻译+字幕+讲解):美国人口普查局表示美国人受教育程度提升
英语每日阅读---5.VOA慢速英语(翻译+字幕+讲解):美国人口普查局表示美国人受教育程度提升 一.总结 一句话总结: a.Thirty-four percent - college degree: ...
- PWA web应用模型
2018年的第一篇博客,最近都去挤图书馆了,希望新年新气象... 简介 PWA 是一门Google推出的web前端新技术,全称是Progressive Web App,是Google在2015年提出, ...
- LeetCode 275. H-Index II
275. H-Index II Add to List Description Submission Solutions Total Accepted: 42241 Total Submissions ...
- 重新学习MySQL数据库1:无废话MySQL入门
重新学习Mysql数据库1:无废话MySQL入门 开始使用 我下面所有的SQL语句是基于MySQL 5.6+运行. MySQL 为关系型数据库(Relational Database Manageme ...