python接口自动化-session_自动发文
一、session简介
查看 requests.session() 帮助文档(只贴了一部分内容)
import requests
help(requests.session()) class Session(SessionRedirectMixin)
| A Requests session.
|
| Provides cookie persistence, connection-pooling, and configuration.
|
| Basic Usage::
|
| >>> import requests
| >>> s = requests.Session()
| >>> s.get('http://httpbin.org/get')
| <Response [200]>
|
| Or as a context manager::
|
| >>> with requests.Session() as s:
| >>> s.get('http://httpbin.org/get')
| <Response [200]>
二、使用session登录
博客园登录实操:
# coding:utf-8
import requests
'''
https的请求相对于http安全级别高,需要验证SSL证书
import urllib3 使用这个方法就OK了
urllib3.disable_warnings() 忽略警告
'''
import urllib3
urllib3.disable_warnings() url = "https://passport.cnblogs.com/user/signin" headers = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"Content-Type": "application/json; charset=utf-8", #json格式
"X-Requested-With": "XMLHttpRequest",
"Referer": "https://passport.cnblogs.com/user/signin",
"Accept-Language": "zh-CN",
"Accept-Encoding": "gzip, deflate",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko",
"Connection": "Keep-Alive",
"Cookie": "_ga=GA1.2.2031405227.1553413697; _gid=GA1.2.1694843763.1553413697; "
"ASP.NET_SessionId=jw21lhtlzwfs14grozrtn5es; "
"SERVERID=4fea726178f35f0633c3d1a5c08ace19|1553430739|1553430738",
} payload = {
"input1":"k2bbCom4IU6eUoLehhL1l+uvFscRoUS5V9ZXmiiRnls"
"jS1fhvbTbj+sVg46vjJ6n3hm2kTVfx7O+dJh9+s7Fv"
"sWbNg1boYxn+mF2QdOoLBT6Zx4debvK3ieMaolFvCZH"
"gggaP+lvB1boSxMvfbKjjhB0R1anz72zyN1OUhfuitU=",
"input2":"iK6m5phf0al626Sfn/mKzAunzXlmaY65X5WX4hha67"
"cp1iS81fUmp5TwP6y3XZt7SRHStQ147xR/jMeAcjPnD"
"H5nhnQeDispR6ZAgmEd8bjInoc81tAKycOmlqBGNeCOj"
"PweXlcR8pREJhm7iSPPHqmN8GJ4c7GGc5C/eZc4Uks=",
"remember":True
} s = requests.session()
r = s.post(url, json=payload, headers=headers, verify=False)
print(r.json())
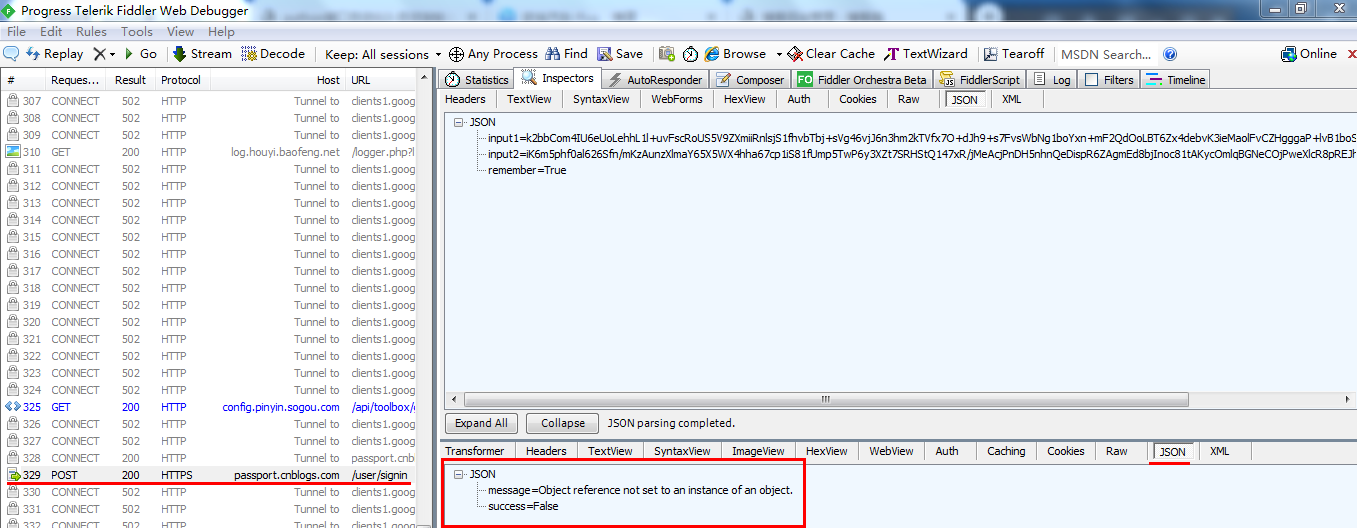
返回的结果:

Fiddler中的结果:
三、自动发文,保存草稿博客
1.先打开登录首页,刷新一下,fiddler抓包,获取部分cookie

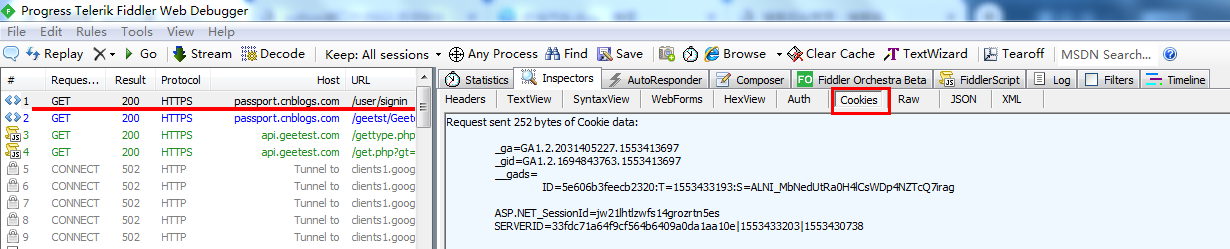
代码:
# coding:utf-8
import requests
import urllib3
urllib3.disable_warnings()
# 先打开登录首页,刷新一下,fiddler抓包,获取部分cookie
url = "https://passport.cnblogs.com/user/signin"
headers = {
"Accept": "text/html, application/xhtml+xml, */*",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko",
"Accept-Encoding": "gzip, deflate",
"Connection": "Keep-Alive",
}
s = requests.session()
r = s.get(url, headers=headers, verify=False)
print("第一次打印")
print(s.cookies)
2.添加登录需要的两个cookie
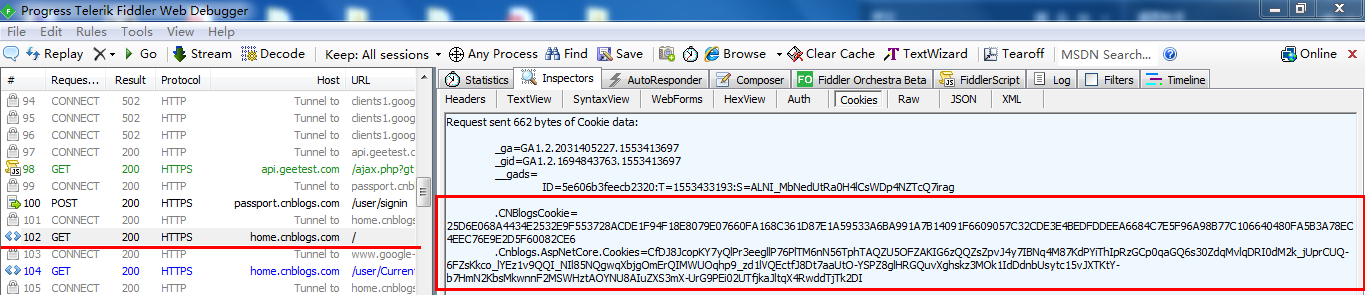
代码:
c = requests.cookies.RequestsCookieJar()
c.set('.CNBlogsCookie', '25D6E068A4434E2532E9F553728ACDE1F94F18E8079E07660FA1'
'68C361D87E1A59533A6BA991A7B14091F6609057C32CDE3E4BEDFD'
'DEEA6684C7E5F96A98B77C106640480FA5B3A78EC4EEC76E9E2D5F60082CE6') # 填登录后的抓包内容
c.set('.Cnblogs.AspNetCore.Cookies', 'CfDJ8JcopKY7yQlPr3eegllP76PlTM6nN56TphTAQZU5'
'OFZAKIG6zQQZsZpvJ4y7IBNq4M87KdPYiThIpRzGCp0qaG'
'Q6s30ZdqMvlqDRI0dM2k_jUprCUQ-6FZsKkco_lYEz1v9QQ'
'I_NIl85NQgwqXbjgOmErQIMWUOqhp9_zd1lVQEctfJ8Dt7aa'
'UtO-YSPZ8glHRGQuvXghskz3MOk1IdDdnbUsytc15vJXTKtY'
'-b7HmN2KbsMkwnnF2MSWHztAOYNU8AIuZXS3mX-UrG9PEi0'
'2UTfjkaJltqX4RwddTjTk2DI') # 填登录后的抓包内容
c.set('AlwaysCreateItemsAsActive', "True")
c.set('AdminCookieAlwaysExpandAdvanced', "True")
s.cookies.update(c)
print("第二次打印")
print(s.cookies)
3.登录成功后访问编辑文章
r1 = s.get("https://i.cnblogs.com/EditPosts.aspx?opt=1", headers=headers, verify=False)
4.打开新随笔,输入内容后保存为草稿,用fiddler抓包
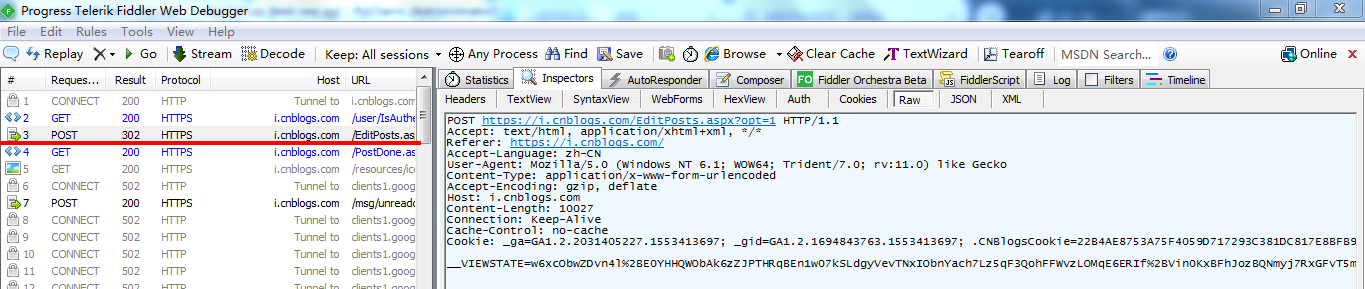
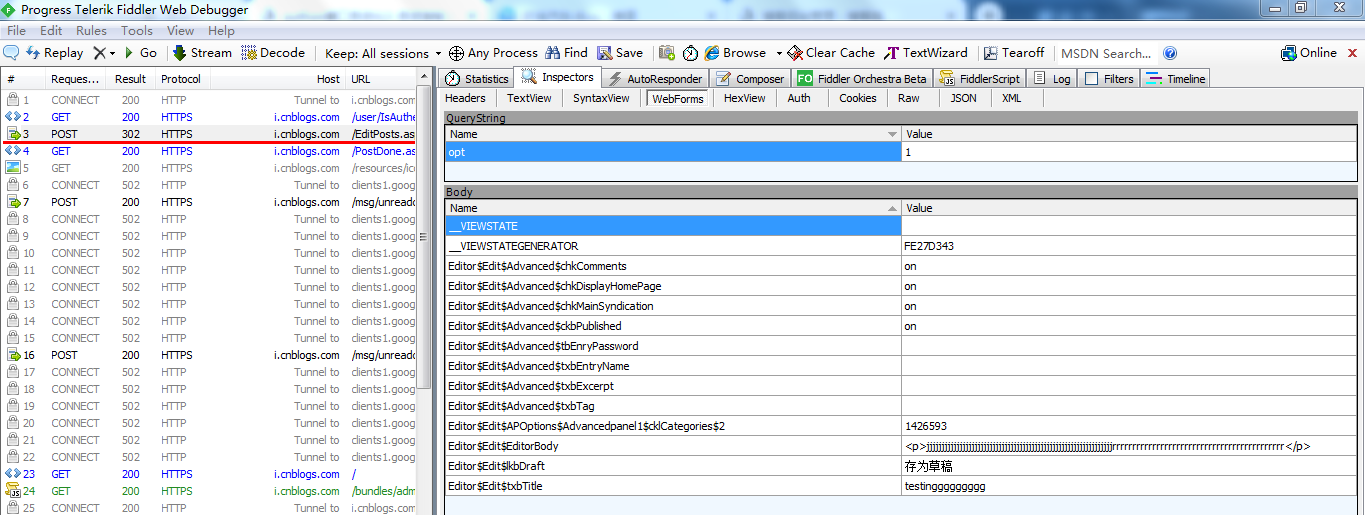
从博客园处可以查看到:

5.把 body 的参数内容写成字典格式,有几个空的参数不是必填项,可以去掉
body = {"__VIEWSTATE": "",
"__VIEWSTATEGENERATOR": "FE27D343",
"Editor$Edit$Advanced$chkComments": "on",
"Editor$Edit$Advanced$chkDisplayHomePage": "on",
"Editor$Edit$Advanced$chkMainSyndication": "on",
"Editor$Edit$Advanced$ckbPublished": "on",
"Editor$Edit$APOptions$Advancedpanel1$cklCategories$2": "1426593",
"Editor$Edit$EditorBody": "<p>jjjjjjjjjjjjjjjjjjjjjjjjjj"
"jjjjjjjjjjjjjjjjjjjjjjjjjjjjjj"
"jjjjjjrrrrrrrrrrrrrrrrrrrrrrrrr"
"rrrrrrrrrrrrrrrrrr</p>",
"Editor$Edit$lkbDraft": "存为草稿",
"Editor$Edit$txbTitle": "testinggggggggg",
}
6.用上面的 session 继续发送 post 请求,对参数稍作修改
url2 = "https://i.cnblogs.com/EditPosts.aspx?opt=1"
body = {"__VIEWSTATE": "",
"__VIEWSTATEGENERATOR": "FE27D343",
"Editor$Edit$Advanced$chkComments": "on",
"Editor$Edit$Advanced$chkDisplayHomePage": "on",
"Editor$Edit$Advanced$chkMainSyndication": "on",
"Editor$Edit$Advanced$ckbPublished": "on",
"Editor$Edit$APOptions$Advancedpanel1$cklCategories$2": "1426593",
"Editor$Edit$EditorBody": "<p>222222222222jjjjjjjjjjjjjjjjjjjjjjjjjj"
"jjjjjjjjjjjjjjjjjjjjjjjjjjjjjj"
"jjjjjjrrrrrrrrrrrrrrrrrrrrrrrrr"
"rrrrrrrrrrrrrrrrrr</p>",
"Editor$Edit$lkbDraft": "存为草稿",
"Editor$Edit$txbTitle": "testinggggggggg2222222222",
}
r2 = s.post(url2, data=body, verify=False)
print("第三次打印")
print(r.content.decode("utf-8"))
7.执行后,查看我的博客,就新增了一条草稿内容
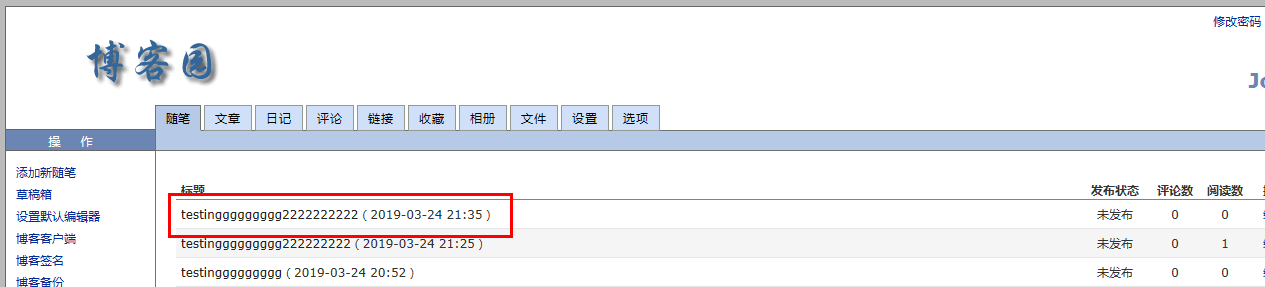
详细内容:

到这里整体的自动发文就完成了
四、全部代码参考
# coding:utf-8
import requests
import urllib3
urllib3.disable_warnings()
# 先打开登录首页,刷新一下,fiddler抓包,获取部分cookie
url = "https://passport.cnblogs.com/user/signin"
headers = {
"Accept": "text/html, application/xhtml+xml, */*",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko",
"Accept-Encoding": "gzip, deflate",
"Connection": "Keep-Alive",
}
s = requests.session()
r = s.get(url, headers=headers, verify=False)
print("第一次打印")
print(s.cookies) # 添加登录需要的两个cookie
c = requests.cookies.RequestsCookieJar() c.set('.CNBlogsCookie', '25D6E068A4434E2532E9F553728ACDE1F94F18E8079E07660FA1'
'68C361D87E1A59533A6BA991A7B14091F6609057C32CDE3E4BEDFD'
'DEEA6684C7E5F96A98B77C106640480FA5B3A78EC4EEC76E9E2D5F60082CE6') # 填登录后的抓包内容
c.set('.Cnblogs.AspNetCore.Cookies', 'CfDJ8JcopKY7yQlPr3eegllP76PlTM6nN56TphTAQZU5'
'OFZAKIG6zQQZsZpvJ4y7IBNq4M87KdPYiThIpRzGCp0qaG'
'Q6s30ZdqMvlqDRI0dM2k_jUprCUQ-6FZsKkco_lYEz1v9QQ'
'I_NIl85NQgwqXbjgOmErQIMWUOqhp9_zd1lVQEctfJ8Dt7aa'
'UtO-YSPZ8glHRGQuvXghskz3MOk1IdDdnbUsytc15vJXTKtY'
'-b7HmN2KbsMkwnnF2MSWHztAOYNU8AIuZXS3mX-UrG9PEi0'
'2UTfjkaJltqX4RwddTjTk2DI') # 填登录后的抓包内容
c.set('AlwaysCreateItemsAsActive', "True")
c.set('AdminCookieAlwaysExpandAdvanced', "True") s.cookies.update(c)
print("第二次打印")
print(s.cookies) # 登录成功后访问编辑文章
r1 = s.get("https://i.cnblogs.com/EditPosts.aspx?opt=1", headers=headers, verify=False) # 保存草稿箱
url2 = "https://i.cnblogs.com/EditPosts.aspx?opt=1" body = {"__VIEWSTATE": "",
"__VIEWSTATEGENERATOR": "FE27D343",
"Editor$Edit$Advanced$chkComments": "on",
"Editor$Edit$Advanced$chkDisplayHomePage": "on",
"Editor$Edit$Advanced$chkMainSyndication": "on",
"Editor$Edit$Advanced$ckbPublished": "on",
"Editor$Edit$APOptions$Advancedpanel1$cklCategories$2": "1426593",
"Editor$Edit$EditorBody": "<p>222222222222jjjjjjjjjjjjjjjjjjjjjjjjjj"
"jjjjjjjjjjjjjjjjjjjjjjjjjjjjjj"
"jjjjjjrrrrrrrrrrrrrrrrrrrrrrrrr"
"rrrrrrrrrrrrrrrrrr</p>",
"Editor$Edit$lkbDraft": "存为草稿",
"Editor$Edit$txbTitle": "testinggggggggg2222222222",
}
r2 = s.post(url2, data=body, verify=False)
print("第三次打印")
print(r.content.decode("utf-8"))
运行后返回的结果:
F:\test-req-py\venv\Scripts\python.exe F:/test-req-py/day2/t4.py
第一次打印
<RequestsCookieJar[<Cookie ASP.NET_SessionId=z4hfksxhg2j2l0s5yuvbrljc for passport.cnblogs.com/>, <Cookie AspxAutoDetectCookieSupport=1 for passport.cnblogs.com/>, <Cookie SERVERID=33fdc71a64f9cf564b6409a0da1aa10e|1553434512|1553434512 for passport.cnblogs.com/>]>
第二次打印
<RequestsCookieJar[<Cookie .CNBlogsCookie=25D6E068A4434E2532E9F553728ACDE1F94F18E8079E07660FA168C361D87E1A59533A6BA991A7B14091F6609057C32CDE3E4BEDFDDEEA6684C7E5F96A98B77C106640480FA5B3A78EC4EEC76E9E2D5F60082CE6 for />, <Cookie .Cnblogs.AspNetCore.Cookies=CfDJ8JcopKY7yQlPr3eegllP76PlTM6nN56TphTAQZU5OFZAKIG6zQQZsZpvJ4y7IBNq4M87KdPYiThIpRzGCp0qaGQ6s30ZdqMvlqDRI0dM2k_jUprCUQ-6FZsKkco_lYEz1v9QQI_NIl85NQgwqXbjgOmErQIMWUOqhp9_zd1lVQEctfJ8Dt7aaUtO-YSPZ8glHRGQuvXghskz3MOk1IdDdnbUsytc15vJXTKtY-b7HmN2KbsMkwnnF2MSWHztAOYNU8AIuZXS3mX-UrG9PEi02UTfjkaJltqX4RwddTjTk2DI for />, <Cookie AdminCookieAlwaysExpandAdvanced=True for />, <Cookie AlwaysCreateItemsAsActive=True for />, <Cookie ASP.NET_SessionId=z4hfksxhg2j2l0s5yuvbrljc for passport.cnblogs.com/>, <Cookie AspxAutoDetectCookieSupport=1 for passport.cnblogs.com/>, <Cookie SERVERID=33fdc71a64f9cf564b6409a0da1aa10e|1553434512|1553434512 for passport.cnblogs.com/>]>
第三次打印 <!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width" />
<meta name="renderer" content="webkit" />
<meta name="force-rendering" content="webkit" />
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1" />
<title>用户登录 - 博客园</title>
...内容太多,省略...
</head>
</body>
</html>
python接口自动化-session_自动发文的更多相关文章
- python接口自动化-Cookie_绕过验证码登录
前言 有些登录的接口会有验证码,例如:短信验证码,图形验证码等,这种登录的验证码参数可以从后台获取(或者最直接的可查数据库) 获取不到也没关系,可以通过添加Cookie的方式绕过验证码 前面在“pyt ...
- python接口自动化(十)--post请求四种传送正文方式(详解)
简介 post请求我在python接口自动化(八)--发送post请求的接口(详解)已经讲过一部分了,主要是发送一些较长的数据,还有就是数据比较安全等.我们要知道post请求四种传送正文方式首先需要先 ...
- python接口自动化28-requests-html爬虫框架
前言 requests库的好,只有用过的人才知道,最近这个库的作者又出了一个好用的爬虫框架requests-html.之前解析html页面用过了lxml和bs4, requests-html集成了一些 ...
- python接口自动化 -参数关联(一)
原文地址https://www.cnblogs.com/yoyoketang/p/6886610.html 原文地址https://www.cnblogs.com/yoyoketang/ 原文地址ht ...
- python接口自动化24-有token的接口项目使用unittest框架设计
获取token 在做接口自动化的时候,经常会遇到多个用例需要用同一个参数token,并且这些测试用例跨.py脚本了. 一般token只需要获取一次就行了,然后其它使用unittest框架的测试用例全部 ...
- python接口自动化4-绕过验证码登录(cookie)
前言 有些登录的接口会有验证码:短信验证码,图形验证码等,这种登录的话验证码参数可以从后台获取的(或者查数据库最直接). 获取不到也没关系,可以通过添加cookie的方式绕过验证码. 一.抓登录coo ...
- python接口自动化1-发送get请求
前言 requests模块,也就是老污龟,为啥叫它老污龟呢,因为这个官网上的logo就是这只污龟,接下来就是学习它了. 一.环境安装 1.用pip安装requests模块 >>pip in ...
- python接口自动化7-参数关联
前言 我们用自动化发帖之后,要想接着对这篇帖子操作,那就需要用参数关联了,发帖之后会有一个帖子的id,获取到这个id,继续操作传这个帖子id就可以了 (博客园的登录机制已经变了,不能用账号和密码登录了 ...
- 2020年第二期《python接口自动化+测试开发》课程,已开学!
2020年第二期<python接口自动化+python测试开发>课程,12月15号开学! 主讲老师:上海-悠悠 上课方式:QQ群视频在线教学,方便交流 本期上课时间:12月15号-3月29 ...
随机推荐
- 好程序员web前端分享CSS基础篇
学习目标 1.CSS简介 2.CSS语法 3.样式的创建 4.两种引入外部样式表的区别 5.样式表的优先级和作用域 6.CSS选择器 7.选择器的权重 8.浮动属性的简单应用 9.HTML.CSS注释 ...
- aspnetcore.webapi实战k8s健康探测机制 - kubernetes
1.浅析k8s两种健康检查机制 Liveness k8s通过liveness来探测微服务的存活性,判断什么时候该重启容器实现自愈.比如访问 Web 服务器时显示 500 内部错误,可能是系统超载,也可 ...
- require.js简单入门
推荐文章:http://www.ruanyifeng.com/blog/2012/11/require_js.html 1.以下例子主要实现功能, 1)引用jq库获取dom中元素文本, 2)实现并引用 ...
- 移动设备分辨率(终于弄懂了为什么移动端设计稿总是640px和750px)
在我开始写移动端页面至今,一直有2个疑问困扰着我,我只知道结果但不知道为什么 问题1:为什么设计师给的设计稿总是640px或750px(现在一般以Phone6为基准,给的750px) 问题2:为什么我 ...
- python获取set-cookies
python获取set-cookies #!/usr/bin/python3.4 # -*- coding: utf-8 -*- import requests url = "https:/ ...
- Linux命令(精简版)
1:init 0 关机(root用户可用) 2:exit退出终端 3:who查看登录用户 4:whoami 查看当前用户 5:data 查看当前时间 data “月日时分年” 修改当前 ...
- nginx报错 [error] open() “/usr/local/var/run/openresty.pid” failed (2: No such file or directory)
解决: 服务没有启动 使用start启动服务,因为没有start而直接使用stop或者reload报错这个问题: 如果方法一没有解决,使用方法二:-C 指定配置文件nginx.conf或者weblua ...
- Python:说说字典和散列表,散列冲突的解决原理
散列表 Python 用散列表来实现 dict.散列表其实是一个稀疏数组(总是有空白元素的数组称为稀疏数组).在一般书中,散列表里的单元通常叫做表元(bucket).在 dict 的散列表当中,每个键 ...
- js事件循环机制辨析
对于新接触js语言的人来说,最令人困惑的大概就是事件循环机制了.最开始这也困惑了我好久,花了我几个月时间通过书本,打代码,查阅资料不停地渐进地理解他.接下来我想要和大家分享一下,虽然可能有些许错误的 ...
- .net core +codefirst(.net core 基础入门,适合这方面的小白阅读,本文使用mysql或mssql)
设置为model所在的那一层 前言 .net core mvc和 .net mvc开发很相似,比如 视图-模型-控制器结构.所以.net mvc开发员很容易入手.net core mvc .但是两个又 ...