Solr 15 - Solr添加和更新索引的过程 (文档的路由细节)
1 添加文档的细节
1.1 注册观察者 - watcher
Solr单机服务中, 与Solr内部进行交互的类是
HttpSolrServer.
SolrCloud集群中, 与Solr内部进行交互的类是CloudSolrServer.
这里以SolrCloud集群为例讲解添加文档的相关细节.
当Solr客户端向CloudSolrServer发送add/update请求时, CloudSolrServer会从ZooKeeper获取当前SolrCloud的集群状态,并在ZooKeeper管理的配置文件/clusterstate.json和/live_nodes中注册观察者watcher, 便于监视ZooKeeper和SolrCloud.
注册观察者的好处是:
①
CloudSolrServer获得SolrCloud的状态后, 就能直接把要添加/修改的document发往Solr集群的leader, 从而降低网络转发上的消耗;
② 注册watcher有利于添加索引时的负载均衡: 如果有个节点的leader下线了,CloudSolrServer就能立刻感知到, 它就会停止往已下线的leader发送请求.
1.2 文档的路由 - document route
CloudSolrServer添加document时, 需要确定该document发往哪个Shard. SolrCloud集群中, 每个Shard都有一个Hash区间, 添加时, SolrCloud会计算该文档的Hash值, 然后根据它的Hash值, 把它发送到对应Hash区间的Shard.
—— 上述过程称为文档的分发, 由Solr的document route(文档路由)组件来完成.
1.2.1 路由算法
SolrCloud提供了两种路由算法, 创建Collection(集合, 类似于MySQL中的表)时, 需要通过router.name来指定路由策略.
① compositeId - 默认的路由算法:
- 该策略是一致性哈希路由, Shards的哈希范围是
80000000~7fffffff;- 创建Collection的时候必须指定numShards, 这个路由算法将根据Shard的个数, 计算出每个Shard的哈希范围;
- 索引数据会均匀分布在每个Shard上;
- 这个路由策略不支持扩展Shard, 否则会导致一些已经索引到Solr中的文档无法被检索.
② implicit - 绝对路由策略:
- 该路由策略是直接指定索引文档落到具体的某个Shard上;
- 索引数据并不会均匀分布到每个Shard上;
- 使用implicit路由策略的Collection才支持 创建/扩展 Shard.
1.2.2 Solr路由的实现类
Solr中路由的基类是DocRouter, 它有2个子类: CompositeIdRouter(默认使用的), 和ImplicitDocRouter.
我们可以通过继承DocRouter类来定制自己的document route组件.
1.2.3 implicit路由算法的使用
通过SolrJ创建文档索引时, 使用implicit策略指定文档的所属Shard:
代码如下:
doc.addField("route", "shard_X");
同时, 要在schema.xml约束文件中添加字段:
<field name="_route_" type="string"/>
利用URL创建implicit路由方式的Collection:
http://ip:port/solr/admin/collections?action=CREATE&name=coll&router.name=implicit&shards=shard1,shard2,shard3
1.2.4 Solr获取文档Hash值的要求
① Hash值的计算速度必须很快, 这是分布式创建索引的第一步;
② Hash值必须能均匀地分布到每一个Shard上. 如果某个Shard中document数量远多于其他Shard, 那么在查询等操作中, 文档数量多的Shard所花的时间就会大于其他Shard, 而SolrCloud的查询是 先分给各个Shard查询, 然后汇总返回 的过程, 也就是说SolrCloud的查询速度是由最慢的Shard决定的.
基于以上两点, Solr的底层引擎Lucene使用了MurmurHash算法, 用来提高Hash值的计算速度和均匀分布.
关于MurmurHash哈希算法, 可参考文末的相关链接.
2 添加索引的过程
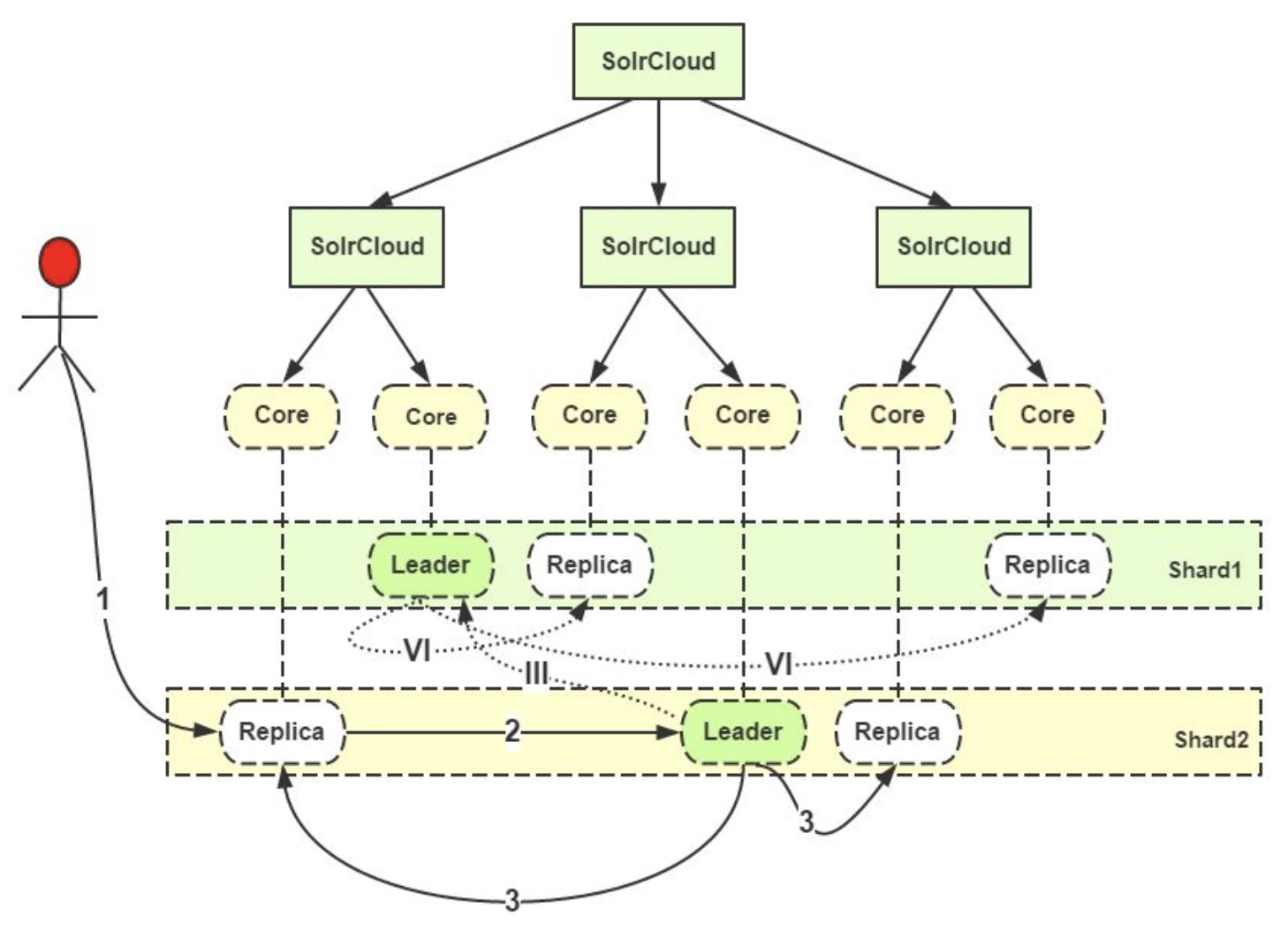
参照上图, 解析添加索引的过程:
(1) 用户把要添加的文档提交给任意一个Replica(副本, 可以是主副本, 也可以是从副本);
(2) 如果接收到请求的Replica不是Leader, 它会把请求转给同Shard中的Leader;
(3) Leader把文档路由给本Shard的其他所有Replica;
(III) 如果根据路由规则, 当前文档并不属于当前的Shard, 这个Leader就会把它转交给对应Shard的Leader;
(VI) 对应的Leader会把文档路由给本Shard的每个Replica, 从而完成添加操作.
注意:
添加索引时, 单个document的路由非常简单.
但是SolrCloud支持批量添加索引, 也就是说对多个document同时进行路由, 这时SolrCloud会根据document路由的去向分开存放document, 然后并发传送到相应的Shard, 这就需要SolrCloud具有较高的并发能力.
3 更新索引的过程
(1) Leader接受到update请求后, 先将需要修改的文档存放到本地的update log, 同时Leader还会对这个文档分配新的version(版本信息), 对于已经存在的文档, 如果新版本值大于旧版本值, 就会抛弃旧版本;
(2) 一旦document经过验证并修改了version后, 就会被并行转发到所有上线的Replica;
SolrCloud并不关注那些已经下线的Replica, 因为当它们上线之后就会有Recovery恢复进程对它们进行恢复. 如果Replica处于recovering(恢复中)的状态, 那这个Replica就会把update放入update transaction日志, 等待恢复完成后再做同步.
(3) 当Leader接受到所有的Replica的成功反馈后, 它才会向客户端反馈操作成功的信息;
Shard中就算只有一个Replica是active的, Solr都会继续接受update请求 —— 这个策略牺牲了一致性, 换取了写入的有效性.
有一个很重要的参数:
leaderVoteWait: 只有一个Replica的时候, 这个Replica进入recovering状态并持续一段时间等待Leader的重新上线. 如果在这段时间内Leader没有上线, 它就会转成Leader. 期间可能会导致部分document丢失.==> 可以借鉴ZooKeeper的选举策略, 使用majority quorum(大多数法定人数)策略来避免这个情况: 比如当多数Replica下线了, 客户端的写请求就会失败.
(4) 索引的commit(提交)有两种:
① softcommit(软提交): 在内存中生成segment, 此时document是可见的, 可以供客户端请求查询, 但是还没有写入磁盘, 系统断电等故障后数据会丢失;
② hardcommit(硬提交): 直接把内存中的数据写入磁盘, 知道写入完成才可见.
—— 软提交的近实时性更强, 硬提交的安全性更高.
4 Solr创建和更新索引的总结
4.1 Leader的转发规则
(1) 请求来自Leader转发: 只需要把数据写到本地的ulog, 不需要转发给Leader, 也不需要转发给其它的Replicas. 如果当前Replica处于非活跃状态, 就会将请求数据接受并写入ulog, 但不会写入索引; 如果发现有重复的更新, 会丢弃旧版本的更新;
(2) 请求不是来自Leader, 但自己就是Leader: 需要把请求写到本地, 并分发给其他的Replicas;
(3) 请求不是来自Leader, 自己也不是Leader: 该请求应该是最原始的请求, 就需要将请求写到本地ulog, 顺便转发给Leader, 再由Leader分发给同一个Shard下的Replica.
(4) 每commit一次(生成新的提交点), 就会重新生成一个ulog更新日志. 当服务器挂掉、内存数据丢失的时候, 数据就可以从ulog中恢复.
4.2 高效实践的建议
(1) 创建索引的时候最好使用CloudSolrServer: 因为CloudSolrServer会直接向Leader发送update请求, 避免了网络的额外开销;
(2) 批量添加索引的时候, 建议在客户端提前做好document的路由, 因为在SolrCloud内进行文档路由的开销比较大.
参考资料
版权声明
作者: 马瘦风
出处: 博客园 马瘦风的博客
您的支持是对博主的极大鼓励, 感谢您的阅读.
本文版权归博主所有, 欢迎转载, 但请保留此段声明, 并在文章页面明显位置给出原文链接, 否则博主保留追究相关人员法律责任的权利.
Solr 15 - Solr添加和更新索引的过程 (文档的路由细节)的更多相关文章
- Java 添加OLE对象到Excel文档
本文介绍通过Java程序添加OLE对象到Excel文档.OLE分为两种形式,一种通过嵌入(Embed),方式,一种通过链接(Link)方式.前者是将对象嵌入到文档中,外部对该对象的更改不影响嵌入操作时 ...
- 微信公众号怎么添加附件?比如word文档,pdf文件等
微信公众号怎么添加附件?比如word文档,pdf文件等 我们都知道创建一个微信公众号,在公众号中发布一些文章是非常简单的,但公众号添加附件下载的功能却被限制,如今可以使用小程序“微附件”进行在公众 ...
- 电脑软件安装过程文档.BA
MD 01-打印并阅读-电脑软件安装过程文档.BAT-即此批处理脚本文档MD 02-阅读-电脑软件安装经验教训文档.DOCX-MD 03-制作-杏雨梨云USB维护系统2019中秋版之国庆更新-可启动U ...
- S01-晓亮的电脑软件安装过程文档 腾讯QQ 595076941 2019年10月
S01-晓亮的电脑软件安装过程文档 腾讯QQ 595076941 2019年10月 本文档的创建作者的腾讯QQ聊天号码是 595076941 S02-电脑软件安装过程中不要随意关闭窗口除非必需关闭窗口 ...
- ABBYY FineReader 15 中保存和导出PDF文档的小细节
运用ABBYY FineReader OCR文字识别软件,用户能将各种格式的PDF文档保存为新的PDF文档.PDF/A格式文档,以及Microsoft Word.Excel.PPT等格式.在保存与导出 ...
- 每日学习心得:SharePoint 2013 自定义列表项添加Callout菜单项、文档关注、SharePoint服务端对象模型查询
前言: 前一段时间一直都比较忙,没有什么时间进行总结,刚好节前项目上线,同时趁着放假可以好好的对之前遇到的一些问题进行总结.主要内容有使用SharePoint服务端对象模型进行查询.为SharePoi ...
- Eclipse 添加 Source 源代码、Javadoc 文档
源代码 Source 按住 Ctrl 键,鼠标放到对应的类.方法上,出现 Open Declaration,Open Implementation ,可查看对应的实现.声明源代码. 也可以在[Proj ...
- Spring boot 添加日志 和 生成接口文档
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring- ...
- Java 添加超链接到Word文档
对特定元素添加超链接后,用户可以通过点击被链接的元素来激活这些链接,通常在被链接的元素下带有下划线或者以不同的颜色显示来进行区分.按照使用对象的不同,链接可以分为文本超链接,图像超链接,E-mail链 ...
随机推荐
- Python三元运算
result = 值1 if 条件 else 值2 如果条件为真,result = 值1 如果条件为假, result = 值2.
- 面试时怎样回答:你对原生ajax的理解
很多人跟我一样用习惯了jq封装好的$.ajax,但是面试时,原生ajax是很多面试官喜欢问的问题,今天再查资料,打算好好整理一下自己理解的原生ajax. 首先,jq的ajax:一般我常用的参数就是这些 ...
- java编程思想-第五章-某些练习题
参考https://blog.csdn.net/caroline_wendy/article/details/46844651 10&11 finalize()被调用的条件 Java1.6以下 ...
- luoguP2526_[SHOI2001]小狗散步_二分图匹配
luoguP2526_[SHOI2001]小狗散步_二分图匹配 题意: Grant喜欢带着他的小狗Pandog散步.Grant以一定的速度沿着固定路线走,该路线可能自交.Pandog喜欢游览沿途的景点 ...
- [NOIP2016]愤怒的小鸟 D2 T3
Description Kiana最近沉迷于一款神奇的游戏无法自拔. 简单来说,这款游戏是在一个平面上进行的. 有一架弹弓位于(0,0)处,每次Kiana可以用它向第一象限发射一只红色的小鸟,小鸟们的 ...
- 从字节码和JVM的角度解析Java核心类String的不可变特性
1. 前言 最近看到几个有趣的关于Java核心类String的问题. String类是如何实现其不可变的特性的,设计成不可变的好处在哪里. 为什么不推荐使用+号的方式去形成新的字符串,推荐使用Stri ...
- postman-----使用CSV和Json文件实现批量接口测试
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 12.0px ".PingFang SC"; color: #454545 } span ...
- 程序设计语言——实践之路 笔记:Beginning
这本书已经看了不下3遍了,计划在6月写完1,3,6,7,8,9章的笔记. 为什么要写笔记呢,我觉得有这么几个必要: 1.一个概念的首次提出与补充会跨越几个章节,整理在一起有助记忆 2.所有书籍的安排都 ...
- Mock接口平台Moco学习
Mock就是模拟接口的.本文学习Mock的 Moco开源框架. Moco源码和jar下载地址: git jar 下载moco-runner-xxxx-standalone.jar moco的启动及 ...
- linux命令----查看磁盘空间
今天用“web发布平台”发布测试的服务,两个节点中发现有一个节点没有发布成功,压测TPS始终上不去,排查后发现只有一个节点在打日志,另一个节点的服务进程都没有在运行,由此断定应该是没有发布成功,有点坑 ...