闲里偷忙的CPU-某个kwoker进程忙
https://zhuanlan.zhihu.com/p/34311472
有一类比较特殊的CPU使用率问题,这类问题的特点是,系统平均CPU使用率很低,但是个别CPU的使用率非常高。今天借助这个真实案例,来跟大家探讨一下这类问题的解题思路。
四平八稳的kworker进程
如下图,客户提交问题的时候描述,kworker这个进程会把单个CPU几乎跑满。看到问题截图,我的第一反应是,客户是不是算错了?这台ECS实例有56个vCPU,客户是不是没有把这76%平均到每个CPU上去啊。平均一下才1.x%,这是相当可以接受啊。
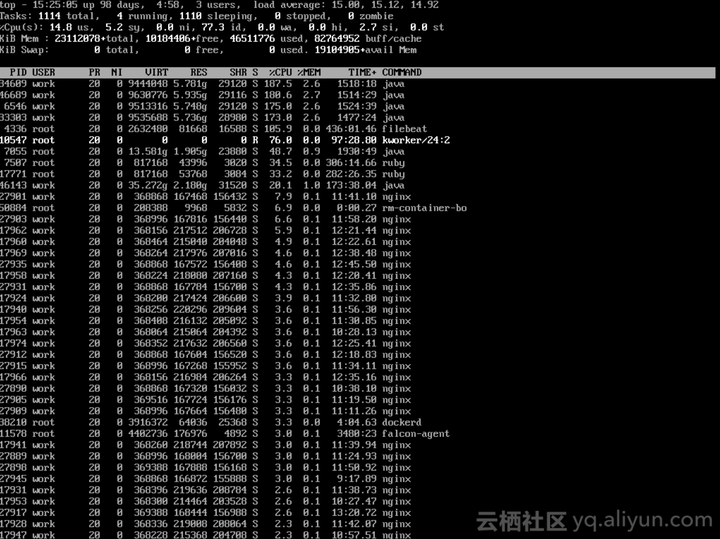
事实证明,还是我太简单了。下边是客户提供的第二张图。仔细观察这张图之后,才发现第24号CPU在内核空间下CPU使用率是73.1%。这个值约等于上图中的76%。这两张图说明,客户所描述的问题,是真实存在的。
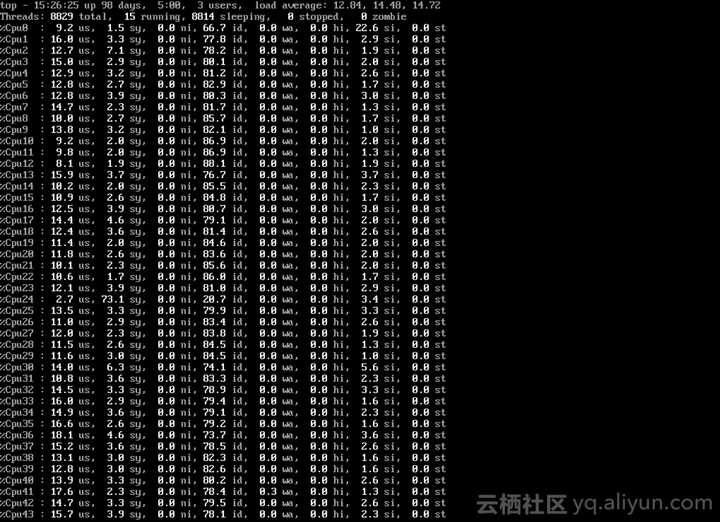
闲里偷忙
在多核环境里,我们能见到的,CPU使用率的问题,大多是每个CPU的使用率都比较高。进程调度算法的一个最主要目标,就是保证不会有有的人撑死,有的人饿死的情况发生。能影响这种“公平性”的因素有两个,一个是优先级(priority),另外一个是相关性(affinity)。优先级处理的是进程之间,哪个比较重要的问题;相关性处理的是进程需要某一个CPU专门负责的问题。
相关性会引起“闲里偷忙”这种问题是显而易见的。如果一个进程被绑定到某一个CPU,那么如果这个进程持续的做计算,势必会让这一个CPU占用率变高。当前这个问题属于这一类。至于优先级和这类问题的关联,不是那么明显。优先级在一些特殊的状况下,会制造类似的麻烦,有机会我会借助例子来分析。
工作队列
相信观察仔细的同学,会发现第一张图里,kworker进程名字后边跟了24:2这样的标识。这个和大多数其他进程是不一样的。我们先从这两个数字背后的机制,工作队列说起。
关于工作队列(work queue),这边有五个核心的概念,分别是工作(work,也就是需要做的事情,分装一个函数),工作池(work pool,工作需要一个一个处理,这是一个工作的集合),工人(worker,实现为内核进程),工人小组(worker pool,工人小团队)以及第五个概念,中介。中介是把工作队列和工人小组联系起来的纽带。工作队列这个机制,是为了保证,每一个work,从被放在工作池里,然后经过中介的手,分配给某一个工人小组的某一个工人去处理,这一切都能高效有序的进行。
对每个CPU,系统会创建两个的工作小组,普通优先级组,和高优先级组。系统会根据工作多少,动态管理每个工人小组里,工人的数量。下边是从网上拿的一张图,这张图对应一个CPU的(普通优先级在上、高优先级在下)两个工作小组。我们可以看到,每个worker被实现为一个kworker进程。而kworker后边的两个数字,大家应该可以猜到,第一个代表的是CPU的编号,第二个代表着一个工人在工人小组里的编号。当前这个问题中,kworker是第24个CPU的第2个worker。这也是为什么,在第二张图里,第24个CPU的系统使用率高的。
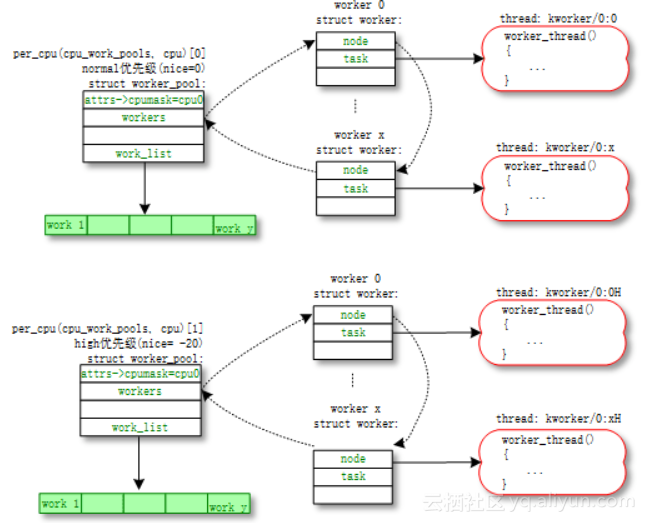
备注:关于工作队列,我这里其实省略了很多细节,而且work pool这个概念是不存在的,它原本是work queue,为了区分这个概念,和工作队列这个机制本身,我稍微修改了一下。
调用栈
到目前为止,我们的结论是,24号CPU的2号kworker进程在持续的使用CPU资源。那为什么这个进程会持续使用CPU资源呢?两种典型情况:一是有一个工作本身定义有问题,怎么做也做不完。二是有很多工作源源不断的交给这个工人。要知道是哪种情况,第一件可以做的事,是看进程(线程)的调用栈。
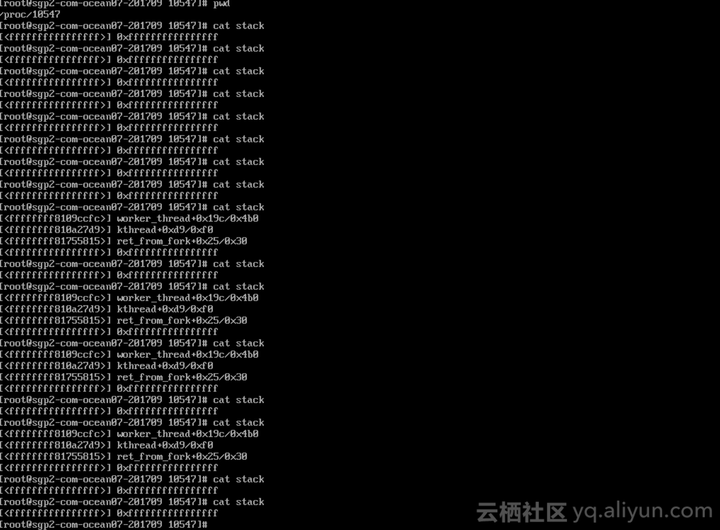
这是一张在客户系统里的截图,我连续查看stack文件内容,发现可以看到的调用栈,都是最终到worker_thread就结束了。这显然是不够的。因为worker_thread是属于framework的一部分,framework相当于电路,要知道家里为什么电费高,一般情况下只看电路是没用的,还是要看挂载电路上的电器是什么。
ftrace
除了stack文件,下一个可以使用的神器是ftrace。ftrace不是一个程序,虽然它的名字和ltrace,和strace像是同类,但其实ftrace完全另外一回事。简单点说,ftrace是一种内核追踪的机制,这种机制集成在内核里,它会根据用户的设置,提供给用户某一方面的日志供调试所用。当前这个问题与工作队列有关,下图是ftrace实现的与工作队列相关的几个事件追踪开关。

其中workqueue_queue_work,显然可以追踪把工作添加到工作队列的事件。开启这个事件追踪,在客户系统里,我拿到下边的日志。
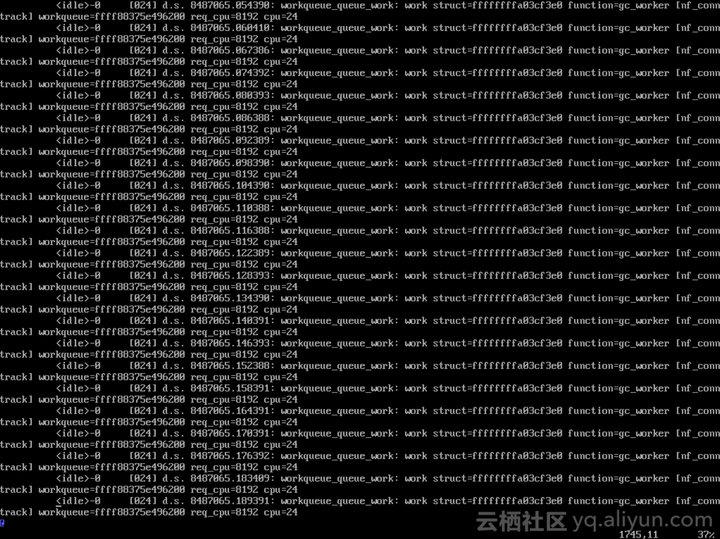
这个日志,能说明三个问题:第一,高CPU使用率并不是某一个有问题的工作导致的,而是很多工作被不断地添加到工作队列里,并分派到24号CPU上导致的;第二,这些工作对应一个函数,就是nf_conntrack这个模块的gc_worker函数;第三,work struct指针从头到尾都没有变化,说明同样一个work被重复添加。
备注:关于ftrace的更多细节,这里不再详述,如果感兴趣,或者用到的时候,请自行Google。
perf
问题进展到这一步,我还是想搞清楚使用CPU资源高的调用栈是什么样子,因为这才是真正的实锤。其间我想到向sysrq-trigger文件写入l字符来产生所有CPU上运行的call stack,但是最终还是怕出事没有做。sysrq确实是一个看起来比较吓人的机制。
下一个可用的工具是perf,很巧的是,我发现客户系统安装了这个工具。而比这更巧的事情是,我发现客户在root目录下,居然有一份收集好的perf日志。顺手用perf report分析这份日志,得到下边输出。很显然这里有我想要的调用栈。而这个调用栈完全匹配之前用其他工具得到的结果。
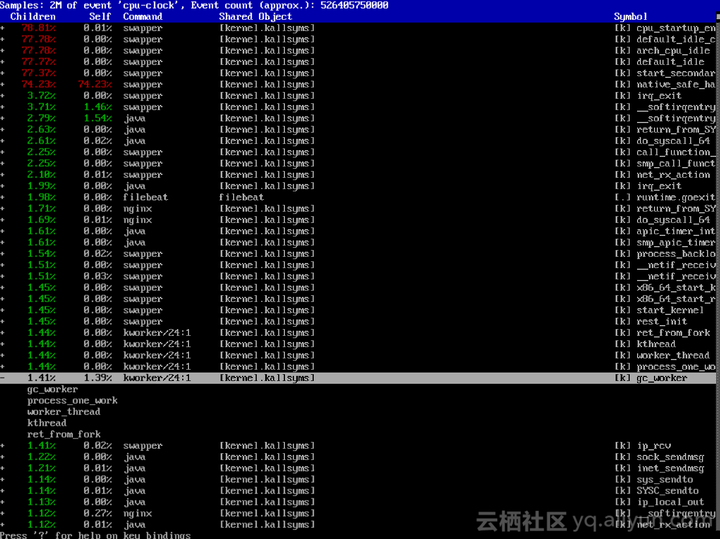
源码分析&建议
知道导致问题的调用栈,下边能做的,只有代码分析。
gc_worker是nf_conntrack模块里定义的,用来执行conntrack表项超时回收任务的一个函数,而这个函数会在自己的结尾处,以一定的延迟策略,重新把自己queue到工作队列中去。这也是为什么我们在ftrace日志里看到所有的work struct指针都不变的原因。
确定了问题是由大量gc_worker工作导致的,那么,从逻辑上来讲,有三个方向可以去调优这个问题。第一个是,让gc_worker的工作分摊到所有的CPU上去。但这个方案必须有内核相关配置项支持。可惜的是,工作队列的代码逻辑为了保证效率,采取了就近原则。就是说,一个工作,运行在一个CPU上,去queue另外一个工作,那么被queue的工作也会被放在同样的CPU上执行。第二个是,根据网络环境,优化gc_worker的相关参数。第三个是,把所有业务进程提升到实时优先级,这样,当业务进程被分派到kworker使用的这个CPU的时候,会抢占kworker,从而保证业务不受影响。
在不能修改内核代码的情况下,我强烈建议客户用第三个方案。
客户的选择
客户最终选择了第二个方案,而且做的比我预想的要彻底,他们直接修改了nf_conntrack这个模块。通过修改影响gc_worker延迟策略相关的参数,保证gc_worker以比较低的频率被执行,从而解决了这个问题。
闲里偷忙的CPU-某个kwoker进程忙的更多相关文章
- 忙里偷闲( ˇˍˇ )闲里偷学【C语言篇】——(8)枚举、补码
一.枚举 # include <stdio.h> enum WeekDay //定义了一个数据类型(值只能写以下值) { MonDay, TuesDay, WednesDay, Thurs ...
- 忙里偷闲( ˇˍˇ )闲里偷学【C语言篇】——(5)有趣的指针
一.指针是C语言的灵魂 # include <stdio.h> int main(){ int *p; //p是变量名,int *表示p变量存放的是int类型变量的地址,p是一个指针变量 ...
- 忙里偷闲( ˇˍˇ )闲里偷学【C语言篇】——(3)输入输出函数
一.基本的输入和输出函数的用法 1.printf() //屏幕输出 用法: (1)printf("字符串\n"); (2)printf("输出控制符", 输出 ...
- 忙里偷闲( ˇˍˇ )闲里偷学【C语言篇】——(2)准备知识
一.变量为什么必须初始化? 在回答这个问题之前,我们先来运行一段代码: #include <stdio.h> int main(){ int i; printf("i=%d\n& ...
- 忙里偷闲( ˇˍˇ )闲里偷学【C语言篇】——(9)链表
我们至少可以通过两种结构来存储数据 数组 1.需要一整块连续的存储空间,内存中可能没有 2.插入元素,删除元素效率极低. 3.查找数据快 链表 1.查找效率低 2.不需要一块连续的内存空间 3.插入删 ...
- 忙里偷闲( ˇˍˇ )闲里偷学【C语言篇】——(7)结构体
一.为什么需要结构体? 为了表示一些复杂的事物,而普通类型无法满足实际需求 二.什么叫结构体? 把一些基本类型组合在一起形成的一个新的复合数据类型叫做结构体. 三.如何定义一个结构体? 第一种方式: ...
- 忙里偷闲( ˇˍˇ )闲里偷学【C语言篇】——(6)动态内存分配
一.传统数组的缺点: 1.数组的长度必须事先定制,且只能是常整数,不能是变量 int len = 5; int a[len]; //error 2.传统形式定义的数组,该程序的内存程序员无法手动释放 ...
- 忙里偷闲( ˇˍˇ )闲里偷学【C语言篇】——(4)for == while ?
一.for和while等价替换 int i = 1; for (i; i<=100; i++){ sum = sum + 1; } int i = 1; while(i<=100){ su ...
- 忙里偷闲( ˇˍˇ )闲里偷学【C语言篇】——(1)GCC介绍及C语言编译过程
一.GCC基本介绍 GCC(GNU Compiler Collection,GNU编译器套装),是一套由GNU开发的编程语言编译器.它是一套以GPL及LGPL许可证所发布的自由软件,也是GNU计划的关 ...
随机推荐
- c++中怎么实现Java中finally语句
所有学习c++的书籍都明确提出了,不要使用goto, 以免造成程序流程的混乱,使理解和调试程序都产生困难. 但是我们遇到这样一个场景怎么办:就是不管程序执行成功与否,都要执行一些资源释放语句,相当ja ...
- ubuntu nvidia驱动+cuda9.0
https://blog.csdn.net/fdqw_sph/article/details/78745375
- 【IMOOC学习笔记】多种多样的App主界面Tab实现方法(四)
ViewPagerIndicator+ViewPager 要想使用ViewPagerIndicator,要使用到viewPagerlibrary开源库 top.xml <?xml version ...
- Python之‘’控制流‘’
一.if语句 格式: i1 = 3 if i1 > 4: print('yes you are right') elif 0 < i1 < 4: print('im dont kon ...
- 用勤哲excel服务器开发设计燃烧器生产行业ERP
J公司是一家专业从事设计.制造.生产及销售各类燃油燃气燃烧设备和各类冶金燃烧装置的专业公司.2011年随着企业的发展,原来手工操作模式已经很难应付日益增长的工作量. J公司希望通过软件管理实现以下几个 ...
- JavaScript Succinctly 读后笔记
1.JavaScript does not have block scope 2.Scope is determined during function definintion, not invo ...
- light oj 1047 - Neighbor House(贪心)
The people of Mohammadpur have decided to paint each of their houses red, green, or blue. They've al ...
- 江西财经大学第一届程序设计竞赛 B
链接:https://www.nowcoder.com/acm/contest/115/B来源:牛客网 题目描述 给出一个出生日期,比如:1999-09-09, 问:从出生那一天开始起,到今天2018 ...
- 75th LeetCode Weekly Contest Champagne Tower
We stack glasses in a pyramid, where the first row has 1 glass, the second row has 2 glasses, and so ...
- Educational Codeforces Round 7 B
Description You are given the current time in 24-hour format hh:mm. Find and print the time after a ...