python爬虫(6)--Requests库的用法
1.安装
利用pip来安装reques库,进入pip的下载位置,打开cmd,默认地址为
C:\Python27\Scripts
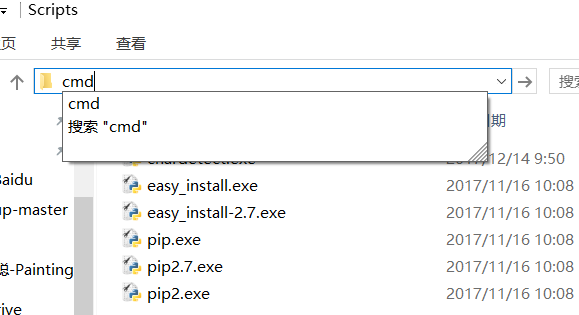
可以看到文件中有pip.exe,直接在上面输入cmd回车,进入命令行界面,输入下载指令即可下载
pip install requests
2.基本请求
requests库提供了http所有的基本请求方式。
r = requests.get("http://httpbin.org/get")
r = requests.post("http://httpbin.org/post")
r = requests.put("http://httpbin.org/put")
r = requests.delete("http://httpbin.org/delete")
r = requests.head("http://httpbin.org/head")
r = requests.options("http://httpbin.org/options")
1)基本GET请求
一个简单的例子
import requests
word = {'key1': 'value1', 'key2': 'value2'}
headers = {'content-type': 'application/json'}
r = requests.get("http://httpbin.org/get", params=word, headers=headers)
print r.url
print type(r)
print r.status_code
print r.encoding
print r.cookies
这里requests.get可以打开网址,如果想要加参数,可以利用 params 参数,如果想添加 headers,可以传 headers 参数。得到结果如下:
http://httpbin.org/get?key2=value2&key1=value1
<class 'requests.models.Response'>
200
None
<RequestsCookieJar[]>
2)基本POST请求
对于 POST 请求来说,我们一般需要为它增加一些参数。那么最基本的传参方法可以利用 data 这个参数。
以表单形式传送数据:
import requests
word = {'key1': 'value1', 'key2': 'value2'}
r = requests.post("http://httpbin.org/post", data=word)
print r.text
运行结果
{
"args": {},
"data": "",
"files": {},
"form": {
"key1": "value1",
"key2": "value2"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Connection": "close",
"Content-Length": "",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.18.4"
},
"json": null,
"origin": "211.69.161.114",
"url": "http://httpbin.org/post"
}
传JSON格式的数据,可以用 json.dumps() 方法把表单数据序列化:
import requests
import json word = {'key1': 'value1', 'key2': 'value2'}
r = requests.post("http://httpbin.org/post", data=json.dumps(word))
print r.text
运行结果
{
"args": {},
"data": "{\"key2\": \"value2\", \"key1\": \"value1\"}",
"files": {},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Connection": "close",
"Content-Length": "",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.18.4"
},
"json": {
"key1": "value1",
"key2": "value2"
},
"origin": "211.69.161.114",
"url": "http://httpbin.org/post"
}
通过上述方法,我们可以POST JSON格式的数据
上传文件,直接用 file 参数
新建一个test.txt里面写上一段话:hello,zcx~
import requests
files = {'file': open('test.txt', 'rb')}
r = requests.post("http://httpbin.org/post", files=files)
print r.text
运行结果
{
"args": {},
"data": "",
"files": {
"file": "hello zcx~"
},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Connection": "close",
"Content-Length": "",
"Content-Type": "multipart/form-data; boundary=1908d06ba8ed4066b557bf5e44359eaa",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.18.4"
},
"json": null,
"origin": "211.69.161.114",
"url": "http://httpbin.org/post"
}
requests 是支持流式上传的,这允许你发送大的数据流或文件而无需先把它们读入内存。要使用流式上传,仅需为你的请求体提供一个类文件对象即可
import requests
with open('test.txt') as f:
a = requests.post('http://httpbin.org/post', data=f)
print a.text
3.Cookies
如果一个响应中包含了cookie,那么我们可以利用 cookies 变量来拿到
import requests url = 'http://example.com'
r = requests.get(url)
print r.cookies
另外可以利用 cookies 变量来向服务器发送 cookies 信息
import requests url = 'http://httpbin.org/cookies'
cookies = dict(cookies_are='working')
r = requests.get(url, cookies=cookies)
print r.text
运行结果:
{
"cookies": {
"cookies_are": "working"
}
}
4.超时配置
可以利用 timeout 变量来配置最大请求时间
requests.get('https://www.baidu.com', timeout=0.1)
注:timeout 仅对连接过程有效,与响应体的下载无关。
也就是说,这个时间只限制请求的时间。即使返回的 response 包含很大内容,下载需要一定时间
5.会话对象
在以上的请求中,每次请求其实都相当于发起了一个新的请求。也就是相当于我们每个请求都用了不同的浏览器单独打开的效果。也就是它并不是指的一个会话,即使请求的是同一个网址
很明显,这不在一个会话中,无法获取 cookies,那么在一些站点中,我们需要保持一个持久的会话怎么办呢?就像用一个浏览器逛淘宝一样,在不同的选项卡之间跳转,这样其实就是建立了一个长久会话
解决方案如下
import requests s = requests.Session()
s.get('http://httpbin.org/cookies/set/sessioncookie/123456')
r = s.get("http://httpbin.org/cookies")
print r.text
这里我们请求了两次,一次是设置 cookies,一次是获得 cookies
运行结果
{
"cookies": {
"sessioncookie": ""
}
}
发现可以成功获取到 cookies 了,这就是建立一个会话到作用。
会话是一个全局的变量,可以用来全局的配置
import requests s = requests.Session()
s.headers.update({'x-test': 'true'})
r = s.get('http://httpbin.org/headers', headers={'x-test2': 'true'})
print r.text
运行结果
{
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Connection": "close",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.18.4",
"X-Test": "true",
"X-Test2": "true"
}
}
如果get方法传的headers 同样也是 x-test ,那么它会覆盖掉全局变量。如果不想要全局配置中的一个变量了,设置为 None 即可
headers = {'x-test': None}
6.SSL证书验证
现在随处可见 https 开头的网站,Requests可以为HTTPS请求验证SSL证书,就像web浏览器一样。要想检查某个主机的SSL证书,可以使用 verify 参数
import requests
r = requests.get('https://kyfw.12306.cn/otn', verify=True)
print r.text
如果想跳过证书验证,把 verify 设置为 False 即可,就可以正常请求了。在默认情况下 verify 是 True,所以如果需要的话,需要手动设置下这个变量。
7.代理
如果需要使用代理,可以通过为任意请求方法提供 proxies 参数来配置单个请求
import requests
proxies = {
"https": "http://41.118.132.69:4433"
}
r = requests.post("http://httpbin.org/post", proxies=proxies)
print r.text
也可以通过环境变量 HTTP_PROXY 和 HTTPS_PROXY 来配置代理
export HTTP_PROXY="http://10.10.1.10:3128"
export HTTPS_PROXY="http://10.10.1.10:1080"
python爬虫(6)--Requests库的用法的更多相关文章
- Python爬虫之requests库介绍(一)
一:Requests: 让 HTTP 服务人类 虽然Python的标准库中 urllib2 模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 ...
- python爬虫之requests库
在python爬虫中,要想获取url的原网页,就要用到众所周知的强大好用的requests库,在2018年python文档年度总结中,requests库使用率排行第一,接下来就开始简单的使用reque ...
- Python爬虫:requests 库详解,cookie操作与实战
原文 第三方库 requests是基于urllib编写的.比urllib库强大,非常适合爬虫的编写. 安装: pip install requests 简单的爬百度首页的例子: response.te ...
- Python爬虫之requests库的使用
requests库 虽然Python的标准库中 urllib模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests宣传是 "HTTP for ...
- 【Python爬虫】Requests库的基本使用
Requests库的基本使用 阅读目录 基本的GET请求 带参数的GET请求 解析Json 获取二进制数据 添加headers 基本的POST请求 response属性 文件上传 获取cookie 会 ...
- python爬虫(1)requests库
在pycharm中安装requests库的一种方法 首先找到设置 搜索然后安装,蓝色代表已经安装 requests库中的get请求 与HTTP协议相对应,requests库也有七种请求方式. 获取ur ...
- python爬虫之requests库介绍(二)
一.requests基于cookie操作 引言:有些时候,我们在使用爬虫程序去爬取一些用户相关信息的数据(爬取张三“人人网”个人主页数据)时,如果使用之前requests模块常规操作时,往往达不到我们 ...
- Python爬虫之Requests库的基本使用
import requests response = requests.get('http://www.baidu.com/') print(type(response)) print(respons ...
- Python爬虫系列-Requests库详解
Requests基于urllib,比urllib更加方便,可以节约我们大量的工作,完全满足HTTP测试需求. 实例引入 import requests response = requests.get( ...
- (转)Python爬虫利器一之Requests库的用法
官方文档 以下内容大多来自于官方文档,本文进行了一些修改和总结.要了解更多可以参考 官方文档 安装 利用 pip 安装 $ pip install requests 或者利用 easy_install ...
随机推荐
- IE 内使用ActiveX,写注册表被重定向到如下注册表
IE 内使用ActiveX,写注册表被重定向到如下注册表,所以使用注册表做标记要注意下,目前还没找为什么会这样 HKEY_CURRENT_USER\Software\Microsoft\Interne ...
- Spring Boot入门——集成Mybatis
步骤: 1.新建maven项目 2.在pom.xml文件中引入相关依赖 <!-- mysql依赖 --> <dependency> <groupId>mysql&l ...
- 本地的html服务
本地的调试的时候, 我们服务器返回的cookie就会变的失效,因为你的本地服务器的域名不太对.
- jedis的源码理解-基础篇
[jedis的源码理解-基础篇][http://my.oschina.net/u/944165/blog/127998] (关注实现关键功能的类) 基于jedis 2.2.0-SNAPSHOT ...
- Codeforces 610D Vika and Segments 线段树+离散化+扫描线
可以转变成上一题(hdu1542)的形式,把每条线段变成宽为1的矩形,求矩形面积并 要注意的就是转化为右下角的点需要x+1,y-1,画一条线就能看出来了 #include<bits/stdc++ ...
- MySQL 基础知识(基本架构、存储引擎差异)
前言: // MySQL 并发.异步IO.进程劫持 最近在看高性能 MySQL,记录写学习笔记: 高性能 MySQL 学习笔记(一) 架构与历史 笔记核心内容:MySQL 服务器基础架构.各种存储引擎 ...
- RK30SDK系统重启源码分析
Linux系统重启的最底层函数是arch_reset,这是一个全局的函数指针变量,定义在 arch/arm/mach-rk30/include/mach/system.h中: extern void ...
- [转载] Java开发在线编辑Word同时实现全文检索
一.背景介绍 Word文档与日常办公密不可分,在实际应用中,当某一文档服务器中有很多Word文档,假如有成千上万个文档时,用户查找打开包含某些指定关键字的文档就变得很困难,一般情况下能想到的解决方案是 ...
- LeetCode OJ:Serialize and Deserialize Binary Tree(对树序列化以及解序列化)
Serialization is the process of converting a data structure or object into a sequence of bits so tha ...
- 条款44:将与参数无关的代码剥离template
使用template时,不小心的时候可能就会带来代码膨胀的问题: template<typename T, std::size_t n> class SquareMatrix{ publi ...