回溯和DFS效率分析
回溯和DFS效率分析
一、心得
多组数据记得初始化
两组样例,找圆点点的个数
6 9
....#.
.....#
......
......
......
......
......
#@...#
.#..#.
6 9
....#.
.....#
......
......
...#..
......
......
#@...#
.#..#.
0 0
测试结果
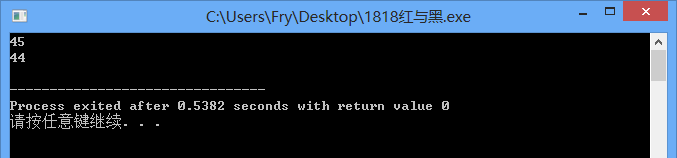
这题用DFS的次数:
45
44
这题用回溯的次数
7 3103 9439 (7亿)
1 5891 4555(1亿)
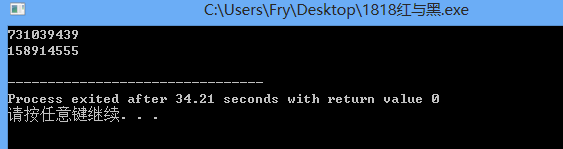
回溯的次数远高于DFS,
如果题目能用DFS做,就尽量用DFS做
因为DFS是找出一组解,而回溯是找出所有的解
二、题目
http://noi.openjudge.cn/ch0205/1818/
1818:红与黑
- 总时间限制:
- 1000ms
- 内存限制:
- 65536kB
- 描述
- 有一间长方形的房子,地上铺了红色、黑色两种颜色的正方形瓷砖。你站在其中一块黑色的瓷砖上,只能向相邻的黑色瓷砖移动。请写一个程序,计算你总共能够到达多少块黑色的瓷砖。
- 输入
- 包括多个数据集合。每个数据集合的第一行是两个整数W和H,分别表示x方向和y方向瓷砖的数量。W和H都不超过20。在接下来的H行中,每行包括W个字符。每个字符表示一块瓷砖的颜色,规则如下
1)‘.’:黑色的瓷砖;
2)‘#’:白色的瓷砖;
3)‘@’:黑色的瓷砖,并且你站在这块瓷砖上。该字符在每个数据集合中唯一出现一次。
当在一行中读入的是两个零时,表示输入结束。 - 输出
- 对每个数据集合,分别输出一行,显示你从初始位置出发能到达的瓷砖数(记数时包括初始位置的瓷砖)。
- 样例输入
-
6 9
....#.
.....#
......
......
......
......
......
#@...#
.#..#.
0 0 - 样例输出
-
45
三、AC代码
//1818:红与黑
#include <iostream>
using namespace std;
int width[]={,,-,};
int height[]={,,,-};
char a[][];
int vis[][];
int w,h;
int w1,h1;
int sum;
/*
6 9
....#.
.....#
......
......
......
......
......
#@...#
.#..#.
6 9
....#.
.....#
......
......
...#..
......
......
#@...#
.#..#.
0 0
这题用DFS的次数:
45
44
这题用回溯的次数
7 3103 9439 (7亿)
1 5891 4555(1亿)
*/
void search(int hh,int ww){
for(int i=;i<=;i++){
int h2=hh+height[i];
int w2=ww+width[i];
if(w2>=&&w2<=w&&h2>=&&h2<=h&&a[h2][w2]=='.'&&!vis[h2][w2]){
vis[h2][w2]=;
sum++;
search(h2,w2);
//vis[h2][w2]=0;
}
}
} int main(){
freopen("in.txt","r",stdin);
while(true){
cin>>w>>h;
if(w==&&h==) break;
sum=;
for(int i=;i<=h;i++){
for(int j=;j<=w;j++){
char c1;
cin>>c1;
if(c1=='@'){
w1=j;
h1=i;
}
a[i][j]=c1;
vis[i][j]=;
}
}
vis[h1][w1]=;
search(h1,w1); //cout<<h1<<w1<<endl;
//cout<<a[8][2]<<endl;
cout<<sum<<endl;
}
return ;
}
回溯和DFS效率分析的更多相关文章
- 递归,回溯,DFS,BFS的理解和模板【摘】
递归:就是出现这种情况的代码: (或者说是用到了栈) 解答树角度:在dfs遍历一棵解答树 优点:结构简洁缺点:效率低,可能栈溢出 递归的一般结构: void f() { if(符合边界条件) { // ...
- 递归,回溯,DFS,BFS的理解和模板
LeetCode 里面很大一部分题目都是属于这个范围,例如Path Sum用的就是递归+DFS,Path Sum2用的是递归+DFS+回溯 这里参考了一些网上写得很不错的文章,总结一下理解与模板 递归 ...
- in和exists的区别与SQL执行效率分析
可总结为:当子查询表比主查询表大时,用Exists:当子查询表比主查询表小时,用in SQL中in可以分为三类: 1.形如select * from t1 where f1 in ('a','b'), ...
- mssql分页原理及效率分析
下面是常用的分页,及其分页效率分析. 1.分页方案一:(利用Not In和SELECT TOP分页) 语句形式: SELECT TOP 10 * FROM TestTable WHERE (ID NO ...
- 团队工作效率分析工具gitstats
如果你是团队领导,关心团队的开发效率和工作激情:如果你是开源软件开发者,维护者某个repo:又或者,你关心某个开源软件的开发进度,那么你可以试一试gitstats. gitstats 是一个git仓库 ...
- 声笔飞码GB2312单字效率分析
-----------------------声笔飞码强字方式单字效率分析-------------------------- 2 keys: 567 items, 381900209 ...
- Flash和js交互的效率分析
Flash和js交互的效率分析 AS代码: var time:int = getTimer(); for (var i:int = 0; i < 50000; i++) { External ...
- [GIt] 团队工作效率分析工具gitstats
copy : http://www.cnblogs.com/ToDoToTry/p/4311637.html 如果你是团队领导,关心团队的开发效率和工作激情:如果你是开源软件开发者,维护者某个repo ...
- 递归,回溯和DFS的区别
递归是一种算法结构,回溯是一种算法思想一个递归就是在函数中调用函数本身来解决问题回溯就是通过不同的尝试来生成问题的解,有点类似于穷举,但是和穷举不同的是回溯会“剪枝”,意思就是对已经知道错误的结果没必 ...
随机推荐
- 高德js API moveAlong 函数的一个错误解决
使用覆盖物之一:点标记,让点标记沿着固定的路线移动. API 提供了现成的函数 moveAlong() 开始以为 实现移动很简单:分两部 1.准备好经纬度数组 2.调用moveAlong()函数.按照 ...
- 【转】Mysql的配置文件详解
[client]port = 3306socket = /tmp/mysql.sock [mysqld]port = 3306socket = /tmp/mysql.sock basedir = /u ...
- TCP原理
1.http://coolshell.cn/articles/11564.html 2.http://coolshell.cn/articles/11609.html 3.一站式学习wireshark ...
- CNI portmap插件实现源码分析
DNAT创建的iptables规则如下:(重写目的IP和端口) PREROUTING, OUTPUT: --dst-type local -j CNI-HOSTPORT_DNAT // PREROU ...
- 23种设计模式UML图
- HDU3552(贪心)
题目是将一系列点对(a,b)分成两个集合.使得A集合的最大a+B集合的最大数b得和最小. 思路:http://blog.csdn.net/dgq8211/article/details/7748078 ...
- atitit.client连接oracle数据库的方式总结
client连接oracle数据库的方式总结 文件夹 Java程序连接一般使用jar驱动连接.. ... 桌面GUI一般採取c语言驱动oci.dll 直接连接... 间接连接(须要配置tns及其env ...
- 什么是EJB
学习EJB可以加深对J2EE平台的认识. 百科定义EJB: 被称为java企业bean,服务器端组件,核心应用是部署分布式应用程序.用它部署的系统不限定平台.实际上ejb是一种产品,描述了应用组件要解 ...
- 查看Oracle的表中有哪些索引
用user_indexes和user_ind_columns系统表查看已经存在的索引 对于系统中已经存在的索引我们可以通过以下的两个系统视图(user_indexes和user_ind_columns ...
- VGA显示
VGA控制器的编写主要是了解VGA的显示标准和时序,如1024X768@60Hz,确定时钟频率(65MHz=1344X806X60),列像素时间等于时钟周期,扫描从左到右.从上到下(类似于电视扫描PA ...