用IDEA编写spark的WordCount
我习惯用Maven项目 所以用IDEA新建一个Maven项目
下面是pom文件 我粘上来吧
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>com</groupId>
<artifactId>ScalaMavenTest2</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.11.8</scala.version>
<scala.compat.version>2.11</scala.compat.version>
</properties> <dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency> <dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.2.2</version>
</dependency> <dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.2.2</version>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.5</version>
</dependency>
</dependencies> <!-- 指定插件-->
<build>
<plugins>
<!--编译java的插件-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
</plugin>
<!-- 指定编译scala的插件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
</plugin> <!-- maven打包的插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>reference.conf</resource>
</transformer>
<!-- 指定main方法 -->
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass></mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build> </project>
代码如下
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
//设置配置文件和名字
val conf = new SparkConf().setAppName("wordConut")
//生成Spark的上下文
val sc = new SparkContext(conf)
//传入文件
val rdd = sc.textFile(args(0))
//先用split()按照空格进行分词 在通过flatMap对分割的单词进行展评,展评完毕后 使用map(x=>(x,1))对每个单词
//计数1最后使用ReduceByKey(_+_) 根据Key也就是单词进行计数 这是一个Shuffer过程
val wordcount = rdd.flatMap(_.split(" ")).map(x=>(x,1)).reduceByKey(_+_)
//先使用map(x=>(x._2,x._1))对单词结果的k V 进行转换然后通过sortByKey(false)根据K V也就是词频进行排序 false要求
//按照倒序进行排列,最后再次通过map(x=>(x._2,x._1))让 K V 再次进行互换 形成最后结果
val wordsort = wordcount.map(x=>(x._2,x._1)).sortByKey(false).map(x=>(x._2,x._1))
//写出路径
wordsort.saveAsTextFile(args(1))
sc.stop()
}
}
之后设置参数 指定master 和文件所在目录 和输出目录
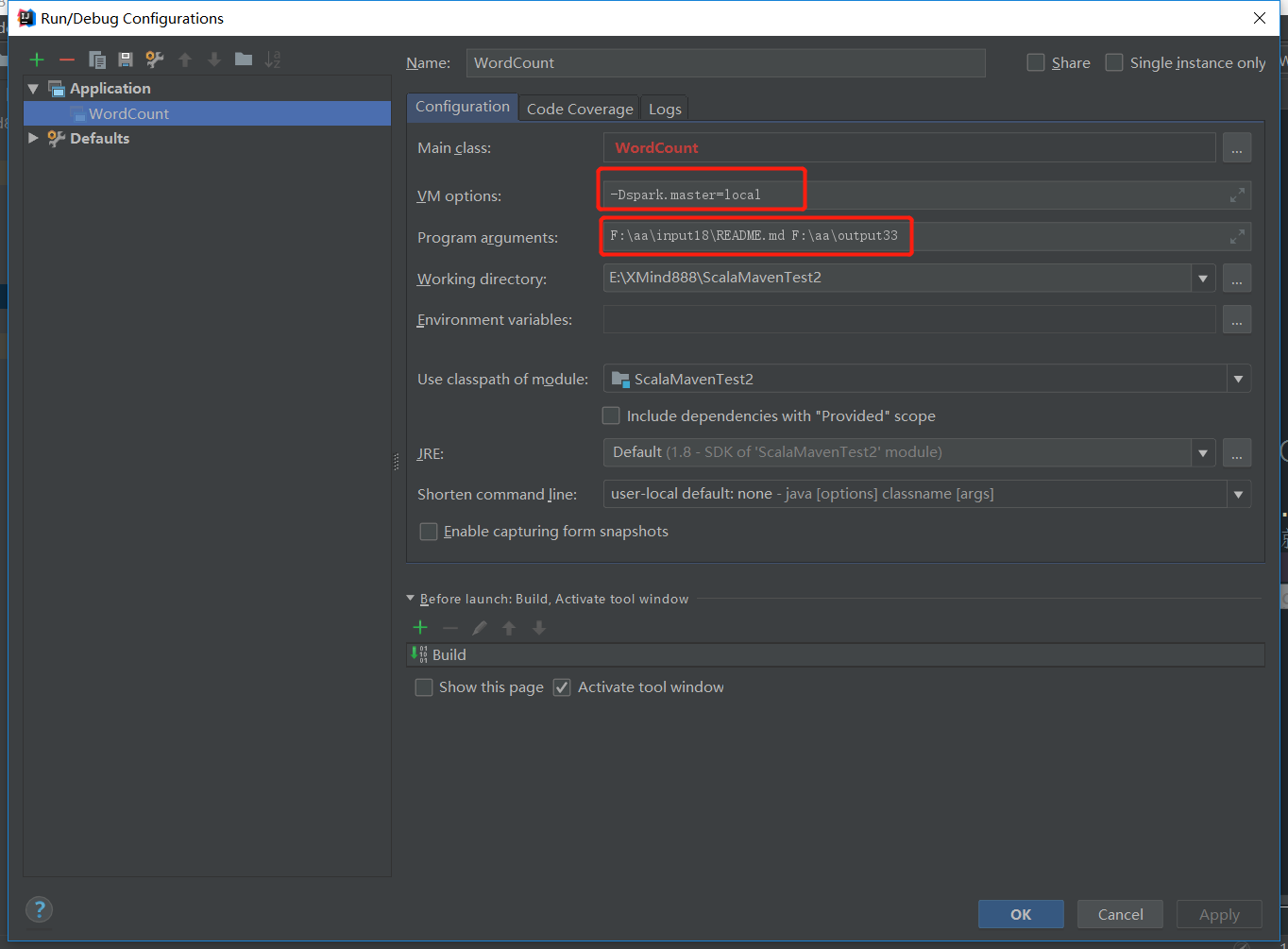
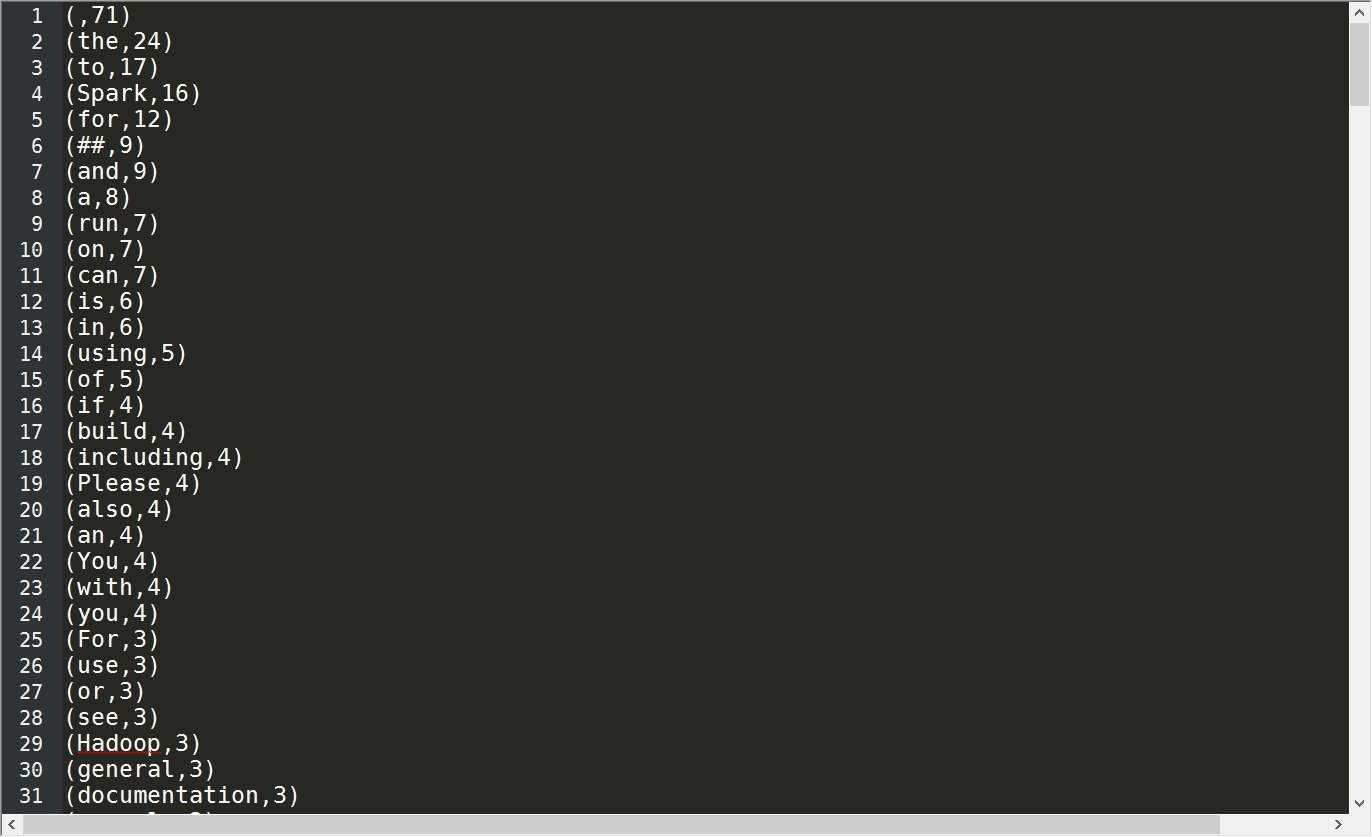
成功之后的结果
用IDEA编写spark的WordCount的更多相关文章
- 编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本]
编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本] 1. 开发环境 Jdk 1.7.0_72 Maven 3.2.1 Scala 2.10.6 Spark 1.6 ...
- 在IDEA中编写Spark的WordCount程序
1:spark shell仅在测试和验证我们的程序时使用的较多,在生产环境中,通常会在IDE中编制程序,然后打成jar包,然后提交到集群,最常用的是创建一个Maven项目,利用Maven来管理jar包 ...
- [转] 用SBT编译Spark的WordCount程序
问题导读: 1.什么是sbt? 2.sbt项目环境如何建立? 3.如何使用sbt编译打包scala? [sbt介绍 sbt是一个代码编译工具,是scala界的mvn,可以编译scala,java等,需 ...
- Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码
Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本文主要是记录一写我在学习MapReduce时的一些 ...
- 用SBT编译Spark的WordCount程序
问题导读: 1.什么是sbt? 2.sbt项目环境如何建立? 3.如何使用sbt编译打包scala? sbt介绍 sbt是一个代码编译工具,是scala界的mvn,可以编译scala,java等,需要 ...
- 1.spark的wordcount解析
一.Eclipse(scala IDE)开发local和cluster (一). 配置开发环境 要在本地安装好java和scala. 由于spark1.6需要scala 2.10.X版本的.推荐 2 ...
- spark学习之IDEA配置spark并wordcount提交集群
这篇文章包括以下内容 (1)IDEA中scala的安装 (2)hdfs简单的使用,没有写它的部署 (3) 使用scala编写简单的wordcount,输入文件和输出文件使用参数传递 (4)IDEA打包 ...
- Spark 实现wordcount
配置完spark之后,使用spark实现wordcount,这一部分完全参考<深入理解Spark:核心思想与源码分析> 依然使用hadoop wordcountTest的那几个txt文件 ...
- 【未完成】[Spark SQL_2] 在 IDEA 中编写 Spark SQL 程序
0. 说明 在 IDEA 中编写 Spark SQL 程序,分别编写 Java 程序 & Scala 程序 1. 编写 Java 程序 待补充 2. 编写 Scala 程序 待补充
随机推荐
- 关注磁盘的两个指标: IOPS 和传输带宽(吞吐量)
㈠ IOPS 磁盘的 IOPS.也就是每秒能进行多少次IO 那么.如何才算一次IO呢? 其实.这是个定义很混乱的问题 因为.系统 ...
- HDU 2050(折线分割平面)
传送门: http://acm.hdu.edu.cn/showproblem.php?pid=2050 折线分割平面 Time Limit: 2000/1000 MS (Java/Others) ...
- HDU 2018母牛的故事(类似斐波那契,找规律)
传送门: http://acm.hdu.edu.cn/showproblem.php?pid=2018 母牛的故事 Time Limit: 2000/1000 MS (Java/Others) ...
- OpenMax的接口与实现
OpenMax IL层的接口定义由若干个头文件组成,这也是实现它需要实现的内容,它们的基本描述如下所示. OMX_Types.h:OpenMax Il的数据类型定义 OMX_Core.h:OpenMa ...
- Oracle查找lobsegment、lobindex对应的表
在查看表空间的使用情况的时候,发现有几个LOBSEGMENT.LOBINDEX类型的对象占用了大量的空间.于是想找出那些表占用了大量的空间,以便于清理. Oracle对BLOB类型的定义 ...
- iOS之webview加载网页、文件、html的方法
UIWebView 是用来加载加载网页数据的一个框.UIWebView可以用来加载pdf.word.doc 等等文件 生成webview 有两种方法,1.通过storyboard 拖拽 2.通过a ...
- ABAP术语-Transaction
Transaction 原文:http://www.cnblogs.com/qiangsheng/archive/2008/03/19/1112804.html Logical process in ...
- linux 网络服务之一
- Redis(五):Redis的持久化
Redis的持久化目录导航: 总体介绍 RDB(Redis DataBase) AOF(Append Only File) 总结(Which one) 总体介绍 官网介绍 RDB(Redis Data ...
- PHP文档生成器(PHPDoc)的基本用法
目录 PHP文档生成器(PHPDoc)的基本用法 PHPDoc概述 安装 PHPDoc注释规范 页面级别的注释 代码级别的注释 生成API文档 额外软件 PHP文档生成器(PHPDoc)的基本用法 P ...